5分钟阅读
一周内5大重磅更新!ChatGPT浏览器、Google智能编码等新工具集体亮相

前言
才刚到周三,AI领域就已迎来多个重要更新,涵盖浏览器、编码、桌面工具等多个方向:
- ChatGPT专属浏览器Atlas
- Google智能编码工具AI First Vibe Coder
- Claude桌面端正式开放
- DeepSeek OCR文本处理模型
- 网页版Claude Code
AI领域从不缺少新动态,每一次更新都在推动工具实用性再升级。
一、新浏览器——ChatGPT Atlas
OpenAI正式推出专属浏览器ChatGPT Atlas,今日已上线macOS系统,下载地址:http://chatgpt.com/atlas


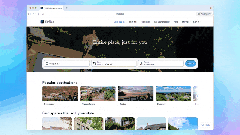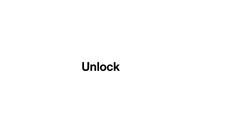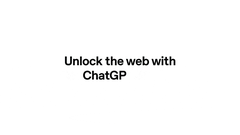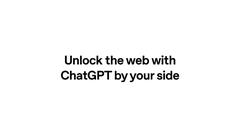





ChatGPT Atlas核心功能如下:
-
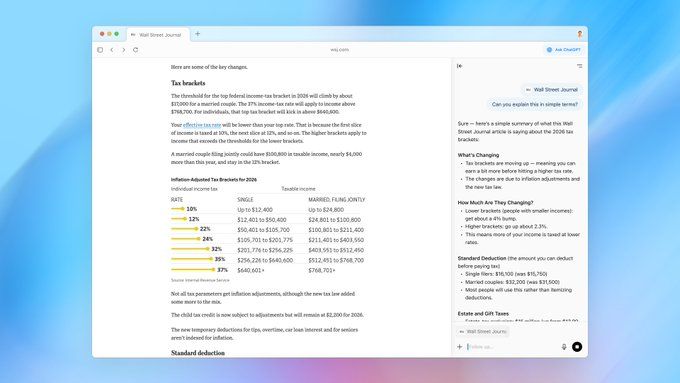
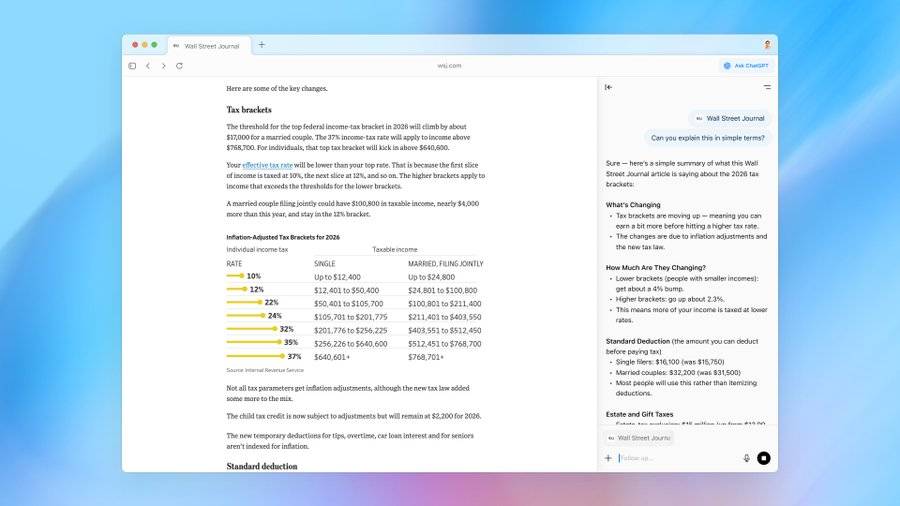
页面感知问答:通过“Ask ChatGPT”侧边栏,ChatGPT可识别当前浏览页面内容,直接解答相关问题。
-
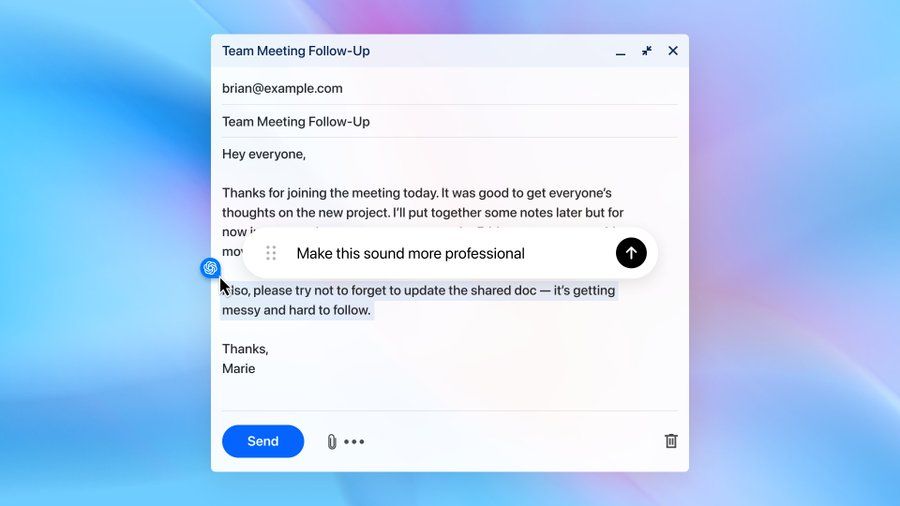
全局输入建议:在网页任意输入框打字时,ChatGPT会实时提供内容建议。
-
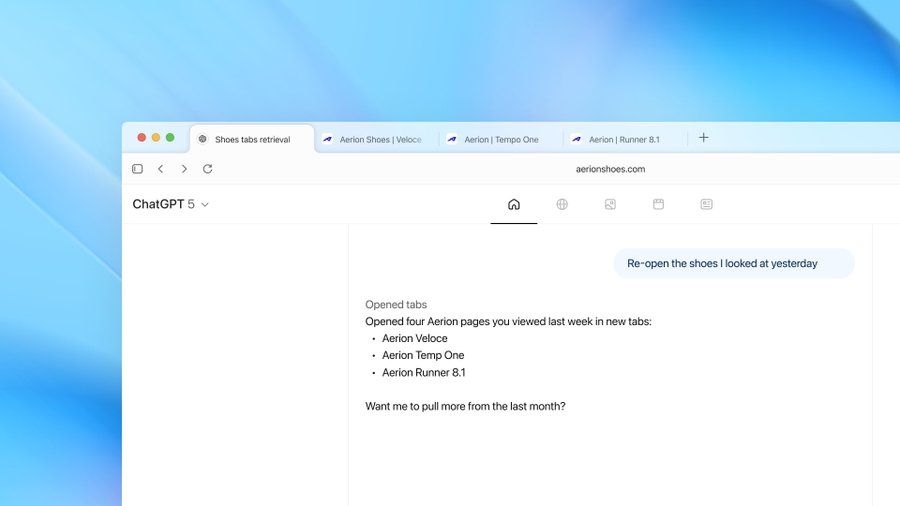
标签页控制:可指令ChatGPT执行打开、关闭、重新打开标签页,或添加书签、回访历史页面等操作。
-
Agent模式:浏览网页时,Agent模式可加速任务完成,目前面向Plus、Pro及Business用户提供预览。
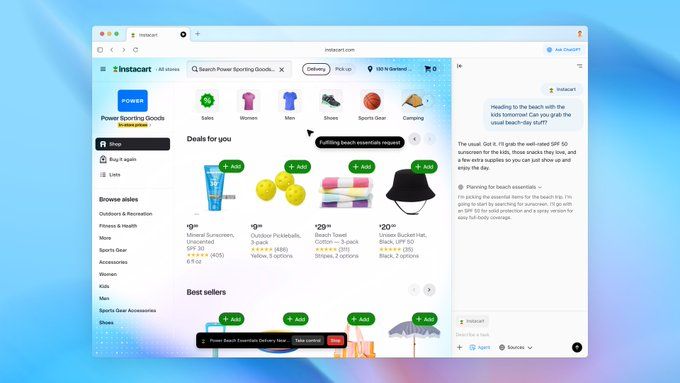
当前Atlas仍处于早期体验阶段,OpenAI将根据用户反馈优化功能。除已上线的macOS版本外,Windows、iOS及Android版本即将推出。

二、Google AI First Vibe Coder
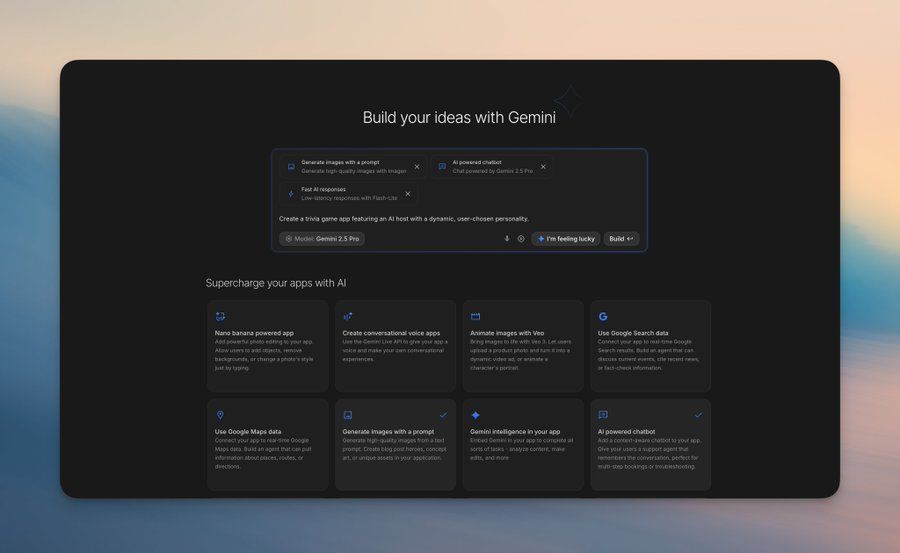
Google推出AI驱动的编码工具Vibe Coder,主打“人人可做AI应用”,核心优势在于:
- 升级后的“构建模式”支持自由组合AI能力,快速将想法转化为实际应用;
- 系统会自动匹配所需模型与API,无需手动配置;
- 若缺乏灵感,点击“I’m Feeling Lucky”即可获取启动帮助。
网友实测 @ciguleva
仅用20分钟就通过Google AI Studio的Vibe完成了开发。对部分任务而言,设计师可跳过单独的设计环节,直接测试实时原型;若后续支持后端开发,其对行业的变革力可能会超出预期,整体使用体验十分流畅。
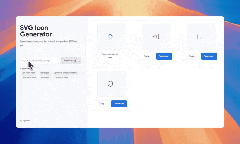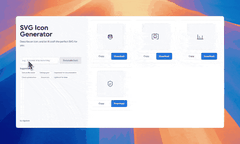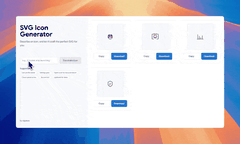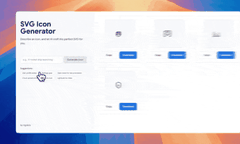
网友 @donvito
仅用一个提示词,就开发出了基于Gemini的AI聊天应用。个人认为,Google AI Studio中的这个“构建”功能,有望成为下一代核心工具。
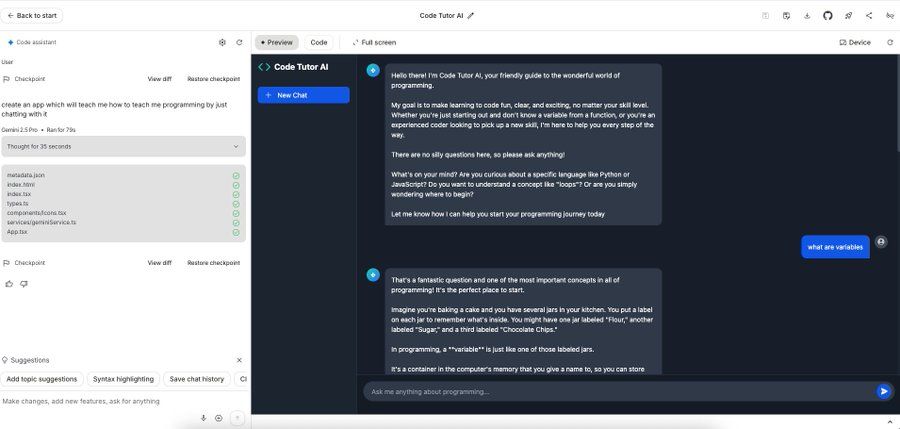
三、Claude Desktop
Claude桌面端已正式开放下载,其中macOS版本新增三大实用功能:
- 截图捕捉:直接截取屏幕内容并分享给Claude;
- 窗口context分享:点击任意窗口,即可将窗口内容作为上下文传给Claude;
- 语音交互:按下Caps Lock键,可直接语音对话Claude。


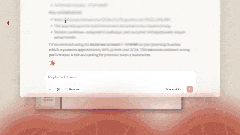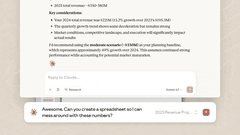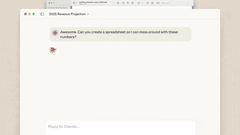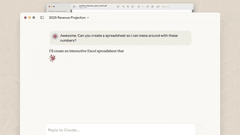

Claude桌面端常驻 Dock 栏,可即时调用,且能连接本地工作环境。目前支持macOS与Windows系统,下载地址:http://claude.com/download
网友实测 @seflless
团队将Claude Code集成到浏览器与白板工具中,打造出名为“Decode”的新工具。它是向Claude Code反馈UX建议的最快方式(支持本地编码时实时沟通),还能让Claude Code自动审查、测试代码修改;结合白板功能后,其浏览器体验进一步提升。
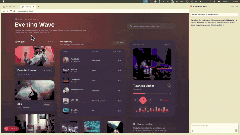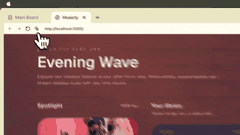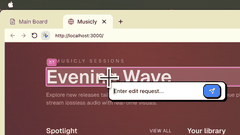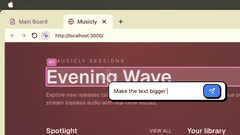
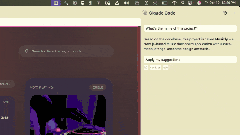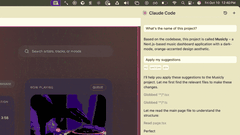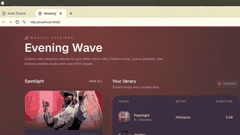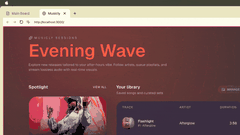
通过Decode可查看任意数量的应用界面,像浏览Figma文件一样轻松审查工作中的应用,且Claude Code能即时应用用户提出的修改建议。
网友 @lennysan
建议所有人(产品经理、营销人员、设计师、创始人、家长等)都多使用Claude Code。关键是要跳出“它只是编码工具”的认知,将其视为“Claude本地版”或“Claude智能代理”——本质是可在本地运行的高智能AI,能直接在电脑上完成多种任务:
- 整理文件与文件夹
- brainstorm域名名称
- 总结客户通话内容
- 提升图片质量
- 创建Linear任务工单

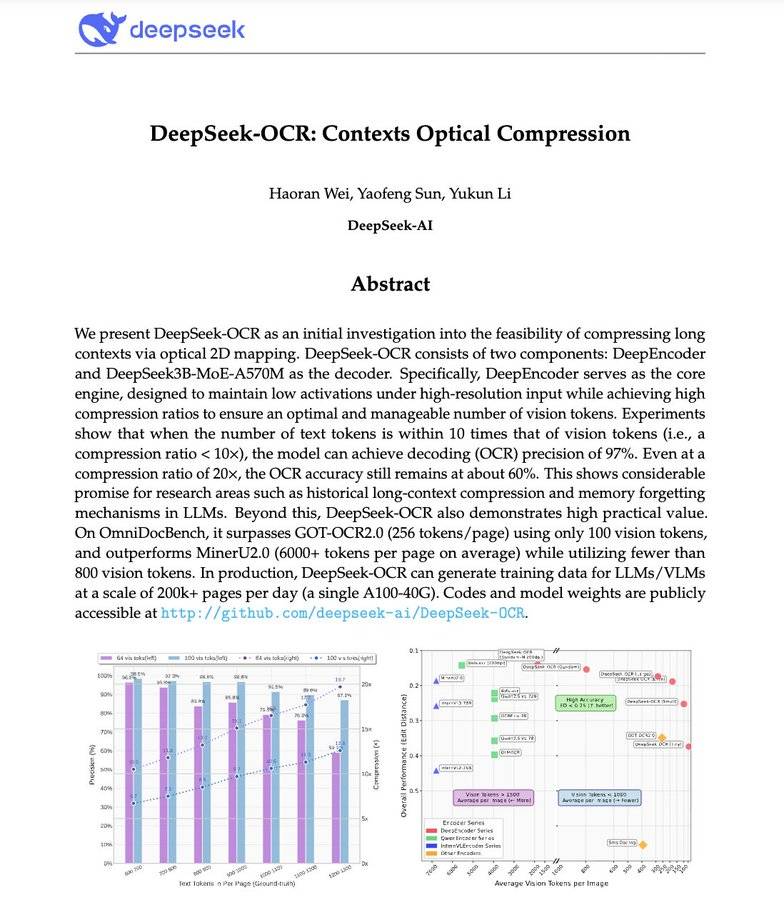
四、DeepSeek OCR
DeepSeek推出全新OCR(光学字符识别)小模型,其核心创新在于“文本视觉化压缩”,被认为是具有颠覆性的研究成果。
DeepSeek OCR的核心能力:
- 将长文本压缩为“视觉令牌”(Vision Tokens),本质是把段落转化为像素;
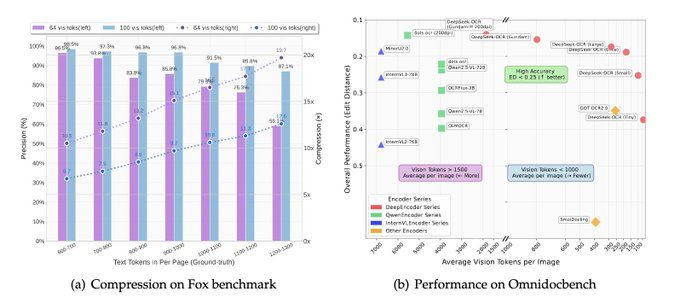
- 压缩10倍时,解码精度仍达97%;即使压缩20倍,准确率仍能保持60%;
- 单张图片可承载整篇文档信息,所需令牌数量仅为传统LLM的极小部分;
- 性能超越GOT-OCR2.0与MinerU2.0,且令牌用量减少60倍;单台A100服务器每日可处理20万+页面。
这一技术有望解决AI领域的核心痛点——长上下文效率低。未来无需为“更长文本序列”支付更高成本,模型可能通过“看文本”而非“读文本”处理信息,上下文压缩的未来或转向视觉化方向。项目开源地址:github. com/deepseek-ai/DeepSeek-OCR
DeepSeek OCR的5大核心设计
- 视觉-文本压缩:核心思路
LLM处理长文档时,令牌用量会随文本长度呈二次方增长;而DeepSeek OCR反其道而行之——不直接“读文本”,而是将整篇文档编码为“视觉令牌”,每个令牌代表一段压缩后的视觉信息。最终实现:处理10页文本的令牌用量,等同于传统GPT-4处理1页文本的用量。
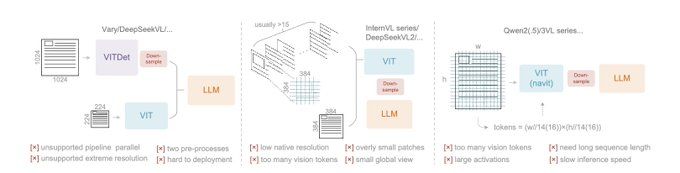
- DeepEncoder:光学压缩核心
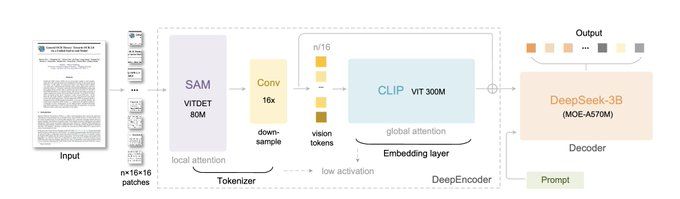
模型核心组件为“DeepEncoder”,通过两大骨干网络(感知层SAM、全局视觉层CLIP),结合16倍卷积压缩器实现连接;在保证高分辨率理解能力的同时,避免激活内存膨胀。最终可将数千个图像补丁,转化为数百个紧凑的视觉令牌。
- 多分辨率“高达模式”(Gundam Mode)
文档类型多样(发票≠蓝图≠报纸),因此DeepSeek OCR支持5种分辨率模式:Tiny、Small、Base、Large、Gundam。其中Gundam模式结合“局部切片+全局视图”,可高效实现512×512至1280×1280分辨率切换,无需重新训练即可适配不同场景。
- 数据引擎:从OCR 1.0到2.0
训练数据不仅包含文本扫描件,还涵盖多类型内容:
- 100种语言的3000万+ PDF页面
- 1000万自然场景OCR样本
- 1000万图表+500万化学公式+100万几何题
这意味着模型不仅能“读文本”,还能解析科学图表、公式与复杂版式。

- 不止是“新OCR”:上下文压缩的验证
DeepSeek OCR的本质是“上下文压缩的验证案例”——若文本可通过视觉化实现10倍压缩,LLM也可借鉴该思路优化长时记忆与推理效率。例如,未来GPT-5处理100万令牌文档时,或可转化为10万令牌的“图像地图”。

为何说DeepSeek OCR具有颠覆性?
其论文核心思路在于“用光学压缩模拟人类记忆遗忘机制”,与AI领域专家Andrej Karpathy提出的“会遗忘的智能”理念相通:
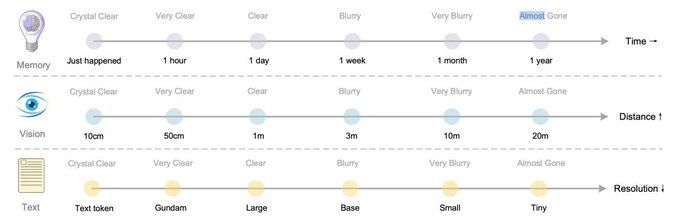
- 人类记忆特点:1小时前的事清晰,1周前的事模糊,1年前的事几乎遗忘;视觉感知同理:10cm内物体清晰,20米外物体模糊。
- DeepSeek的类比设计:用“分辨率衰减”模拟记忆衰减——近期对话用Gundam模式(800+令牌),1周前内容用Base模式(256令牌),久远记忆用Tiny模式(64令牌)。
- 核心价值:既保留历史信息,又控制令牌用量;远期记忆“自然淡化”,如同人类遗忘——这并非“容量不足”,而是“效率优化”。
若该思路落地,理论上可实现“无限上下文窗口”——无需无限扩大窗口,而是让信息随时间自然衰减。DeepSeek将“生物学直觉”转化为“工程方案”,可能重构行业对“长上下文问题”的认知。
五、Andrej Karpathy 的“暴论”
AI领域权威专家Andrej Karpathy公开表示看好DeepSeek OCR论文,核心观点如下:
“我很喜欢DeepSeek的新OCR论文。它本身是个不错的OCR模型(可能略逊于部分现有模型),数据收集等工作也值得肯定,但这些都不是重点。
对我而言(作为本质是计算机视觉研究者、暂时转型自然语言领域的人),更有意思的问题是:像素作为LLM的输入,可能比文本更优?文本令牌是否本身就是低效、甚至糟糕的输入形式?或许LLM的所有输入都应该是图像——即便面对纯文本,也应先渲染成图像再输入。
理由包括:
- 更高信息压缩率(如论文所示)→ 上下文窗口更短,效率更高;
- 信息流更通用→ 不仅支持文本,还能处理粗体、彩色文本、任意图像;
- 输入可默认用双向注意力处理,无需自回归注意力;
- 能力更强大;
- 可废除输入端的令牌生成器(Tokenizer)——我一直吐槽令牌生成器:它繁琐、独立、非端到端,还引入了Unicode、字节编码的复杂性,继承大量历史包袱,甚至存在安全/越狱风险(如续接字节问题);更关键的是,人类视觉上相同的两个字符,在模型内部可能被识别为完全不同的令牌(例如表情符号只是一个“奇怪的令牌”,而非带像素信息的“真实表情”,无法借助视觉迁移学习)。
令牌生成器必须被淘汰。OCR只是“视觉→文本”的众多实用任务之一,而“文本→文本”任务也可转化为“视觉→文本”任务(反之则不成立)。未来用户输入可能全是图像,而助手输出仍保留文本——毕竟生成像素的难度和必要性都更低。
现在我甚至忍不住想开发一个“纯图像输入”版的nanochat了。”

六、Claude Code in Web
网页版Claude Code正式推出,无需打开终端,即可直接委托Claude处理编码任务。
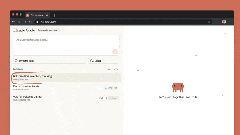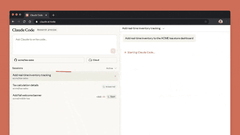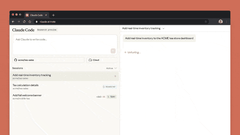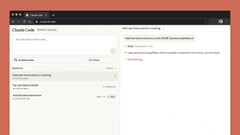
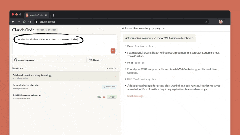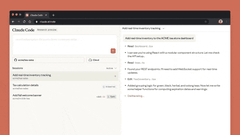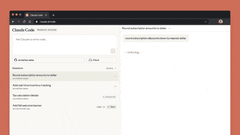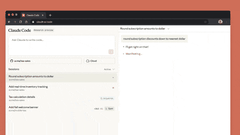
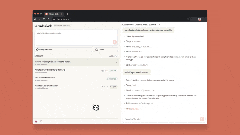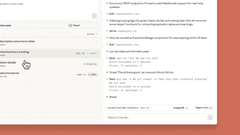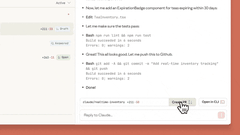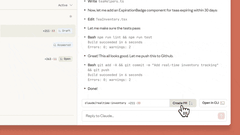
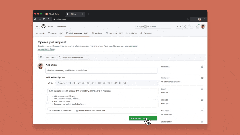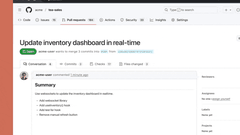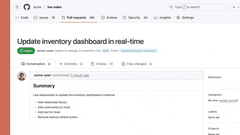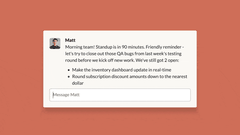
网页版Claude Code支持“多任务并行”:可同时分配多个编码任务,通过浏览器或iOS应用实时监控进度、调整方向,尤其适合处理bug积压、常规修复、并行开发等场景。
目前网页版Claude Code处于beta阶段,作为研究预览向Pro及Max用户开放,更多细节可查看官方说明。
写在最后
本周AI工具更新集中在“实用性升级”——从浏览器、桌面端到编码工具,均在降低AI使用门槛、提升效率;而DeepSeek OCR则从技术底层探索“长上下文难题”的新解法,为行业提供了颠覆性思路。
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。