WithAI.Design
Toggle Menu
关于
博客
标签
中
一键电商出图利器?借助Nano Banana Pro的能力,这款工具是否做到?
其实之前我已出过一个虚拟棚拍的工具,总觉得还不够,我觉得更应该瞄准最终产出物更近一步,所以就出了这个工具
2025年12月21日
• AI辅助设计 • ai-design
最新发布
2025年12月28日
99公斤的碳纤维诗篇:EIDOLON,重新定义电动自行车的设计哲学
#design-inspiration
2025年12月28日
分享整理几个Nano Banana Pro电商广告大片提示语
#ai-design
2025年12月27日
劳力士的袖口心机:当顶级腕表品牌将设计语言铸入袖扣
#design-inspiration
2025年12月27日
速度与质量的博弈:ZImage + Nunchaku 加速实测,人像生成快300
#ai-design
2025年12月25日
从二维Logo到三维奖杯:看设计如何玩转形态与功能
#design-inspiration
2025年12月25日
当工具之王穿上高定西装:奔驰Unimog的80周年豪华蜕变
#design-inspiration
2025年12月24日
AI增长神话背后:Lovable增长负责人亲述,我们扔掉了80的增长宝典
#ai-trends
2025年12月24日
阿里最强开源改图模型升级!QwenImageEdit2511发布,为设计师带来更强控制力
#ai-design
2025年12月22日
告别抠图噩梦!阿里开源「AI版PS」,一键智能分层,设计师狂喜
#ai-design
2025年12月20日
当威尼斯邂逅未来:一艘从时尚界驶出的概念游艇,如何重新定义设计?
#design-inspiration
2025年12月20日
必读!K神的2025年AI回顾:6个正在重塑我们世界的惊人范式转变
#ai-trends
2025年12月19日
2026科技趋势:从实验到影响,成功组织的五大行动指南
#ai-trends
2025年12月19日
设计师值得一读!从产品锁屏到开源:Google Sans 字体的十年进化史
#design-thinking
设
WithAI.Design
2025年12月18日
十年观察,一栋小屋:当设计始于对土地的倾听
#design-inspiration
2025年12月18日
注意看!从图像到3D,从平面到分层:两项将重塑设计流程的AI技术
#ai-trends
2025年12月17日
就在刚刚!GPT Image 15 正式发布:是设计神器,还是挤牙膏?
#ai-design
2025年12月17日
重塑设计工作流:从Perplexity内部指南中提炼的4个AI心智模型
#ai-trends
2025年12月16日
当设计超越功能:三款产品如何重塑日常体验
#design-inspiration
2025年12月16日
璀璨与静谧:宝玑250周年,用两款腕表诠释两种极致
#design-inspiration
2025年12月15日
告别AI提示语混乱!这款免费开源神器,让设计师灵感管理井井有条
#ai-design
告
WithAI.Design
2025年12月15日
告别拼凑感!Dotti系列如何用统一设计语言,重塑办公休闲区?
#design-inspiration
2025年12月14日
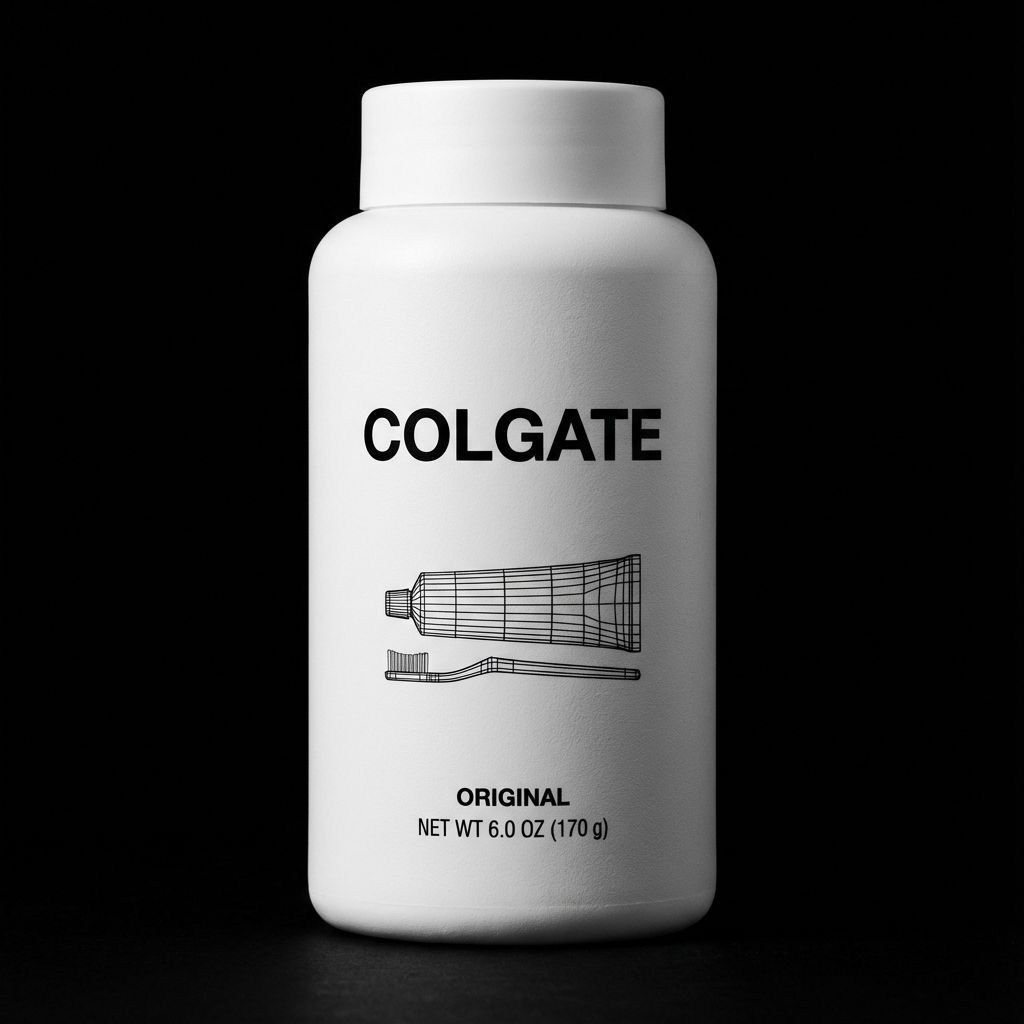
别只生成美女了!Nano Banana Pro 的生产力玩法,设计师必看
#ai-design
2025年12月14日
当数学与诗意在木纹中相遇:揭秘「幻象盒」的几何魔法
#design-inspiration
2025年12月13日
从单图到可缩放世界:三款前沿AI工具如何重塑3D与设计流程
#ai-design
从
WithAI.Design
2025年12月13日
当机器人拥有天使光环:Kriket 3000如何用设计破解人机共存的密码?
#design-inspiration
2025年12月12日
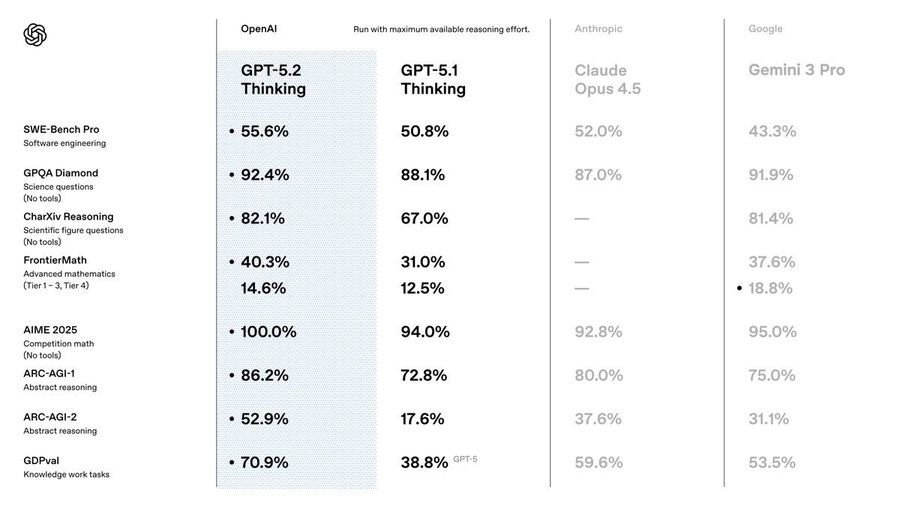
刚刚!GPT52 震撼发布:为真实工作而生的前沿模型,超级助手来了!
#ai-trends
2025年12月11日
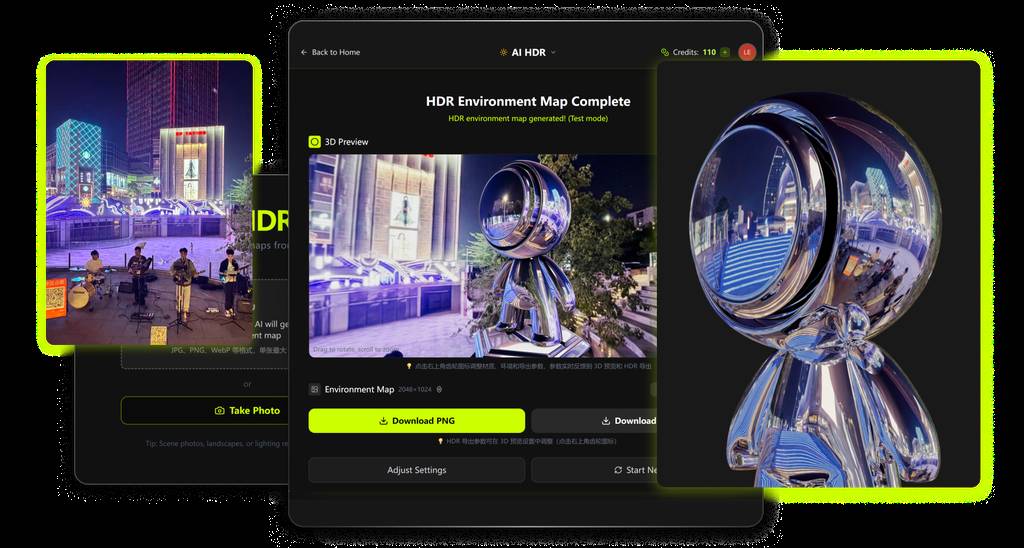
3D设计师盯!HDR自由?这款AI工具做到了
#ai-design
2025年12月11日
Nano Banana Pro 深度解析:设计师必知的四大高级玩法
#ai-design
2025年12月10日
AI设计前沿速递:从精准视频编辑到单图LoRA训练
#ai-trends
A
WithAI.Design
2025年12月10日
雷克萨斯LFA概念车回归:当传奇之名遇见电动灵魂
#design-inspiration
2025年12月9日
AI前沿动态:GLM46V开源、AutoGLM 20与RealGen,设计师与开发者的新工具
#ai-trends
2025年12月9日
个人飞行时代来临?LEO Solo JetBike:一款无需驾照的喷气式自行车
#design-inspiration
2025年12月8日
关乎设计AI 吞噬世界:一场范式转移!
#ai-trends
2025年12月8日
当911挣脱牢笼:RML如何用900匹马力重塑性能图腾
#design-inspiration
2025年12月7日
一周好设计:当形式与功能在细节中相遇
#design-inspiration
2025年12月7日
随手拍生成完整PBR贴图?这个AI工具做到了!
#ai-design
2025年12月6日
吐血整理!2026:AI重塑一切的一年——从SaaS融合到人本回归的44个预测
#ai-trends
2025年12月6日
当URWERK遇见雅典表:限量百枚的时空漫游者URFREAK
#design-inspiration
2025年12月5日
AI如何重塑工作方式?Anthropic内部调查揭示工程师的真实体验
#general
2025年12月5日
介绍我做的网站和几个AI实用小工具
#ai-design
2025年12月4日
NANO Mobilize:当电动单车成为都市青年的时尚胶囊舱
#design-inspiration
2025年12月4日
本周精选:三款融合科技与可持续理念的先锋设计
#design-inspiration
2025年12月3日
ZImage实力如何?人像对比测试
#ai-design
2025年12月3日
当钛金属生长成刀:Rike Predator 如何用五轴铣削颠覆工业设计认知
#design-inspiration
2025年11月30日
Nano Banana Pro人像摄影提示语分享 1
#ai-design
2025年11月28日
SP40 Restomod Speedster:当1930年代优雅邂逅现代工程美学
#design-inspiration
2025年11月28日
三款重新定义体验的未来产品设计
#design-inspiration
2025年11月27日
Anthropic:长效AI代理的高效管理方案:解决多轮会话中的持续推进难题
#ai-trends
2025年11月27日
刚刚!阿里AI小钢炮Z Image登场!6B参数实现顶尖文生图效果
#ai-design
2025年11月26日
FLUX 2开源初探:32B模型强势升级,能否撼动Nano Banana Pro?
#ai-design
F
WithAI.Design
2025年11月26日
腕间宇宙:Christiaan van der Klaauw 定制行星仪腕表「Julie」的工艺与深情
#design-inspiration
2025年11月25日
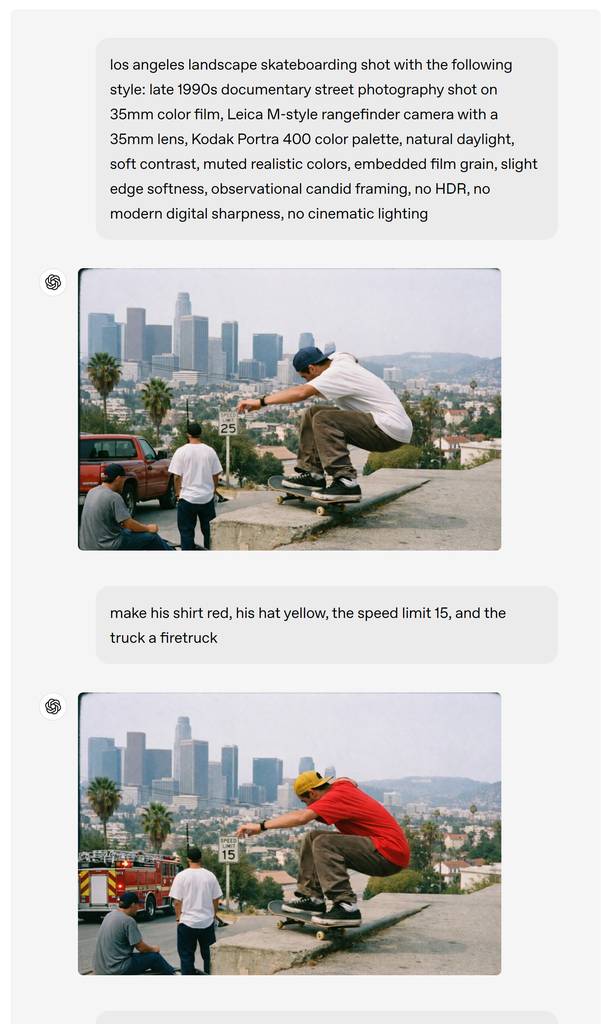
Google官方AI辅助设计工具:Nano Banana Pro 全面使用指南
#ai-design
G
WithAI.Design
2025年11月25日
工业设计师可以这样用Nano Banana Pro 1
#ai-design
2025年11月25日
工业设计师可以这样用Nano Banana Pro
#ai-design
2025年11月24日
AI 时代的恩格斯停顿
#ai-thinking
2025年11月22日
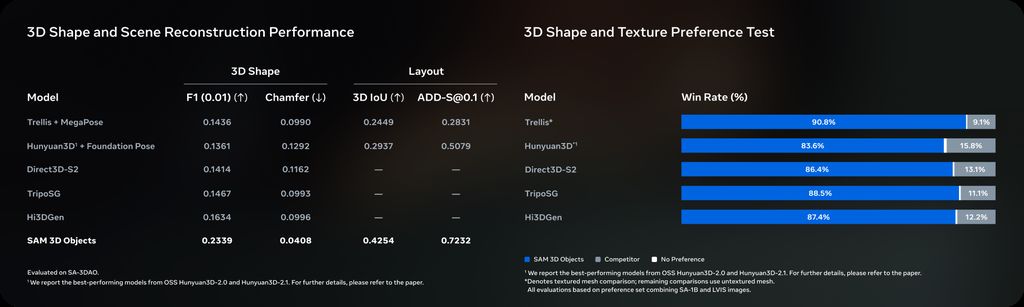
Gemini 3刷屏之际,Meta 重磅发布 SAM 3 与 SAM 3D:AI 辅助设计再添利器
#ai-design
2025年11月22日
宾利凭借2026 GT Supersports重振传奇
#design-inspiration
宾
WithAI.Design
2025年11月22日
施华洛世奇水晶健身器材:当运动装备成为家居艺术品
#design-inspiration
2025年11月21日
Nano Banana Pro 实战全攻略:AI生图的10+创意应用场景
#ai-design
2025年11月20日
4款实用派设计灵感:兼顾功能创新与生活美学
#design-inspiration
2025年11月20日
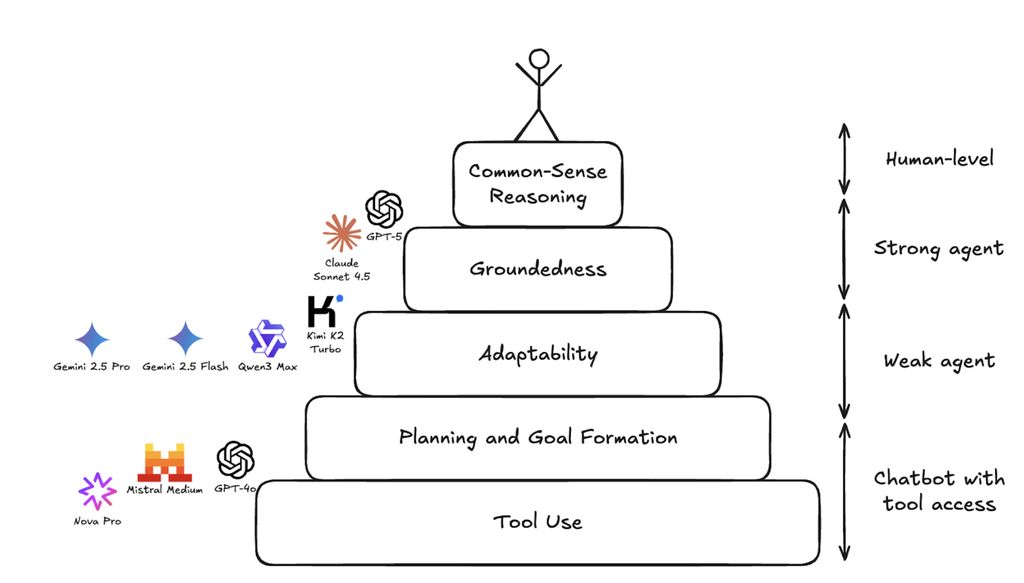
AI智能体能力层级揭秘:9大模型RL环境实测,离人类水平还有多远?
#ai-trends
2025年11月20日
Gemini 3前瞻:物理交互+设计级创作,AI的下一个GPT时刻?
#ai-trends
2025年11月20日
Qwen LoRA生态再升级!5款实用AI设计工具,覆盖场景合成、风格转换与质感优化
#ai-design
2025年11月20日
RAG已死?不,它在智能体时代完成了进化
#ai-trends
2025年11月20日
打破边界:Italjet Roadster 400 重塑踏板与摩托的融合形态
#design-inspiration
2025年11月20日
破桶宣言:为什么你的产品死于无人问津,以及如何用50法则自救(终极拉新实战手册)
#design-thinking
2025年11月20日
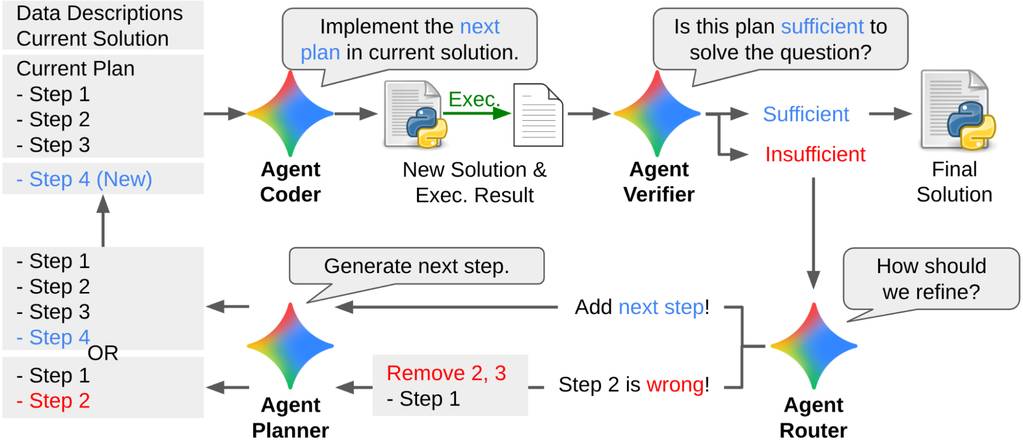
译文: LLM驱动的自主智能体:架构、组件与实践案例
#ai-thinking
译
WithAI.Design
2025年11月12日
AI人像摄影天花板!10组高端提示词+摄影大师深度解析
#ai-design
2025年11月12日
迈巴赫海洋俱乐部:500英尺超级游艇上的海上私享生活
#general
2025年11月11日
最近收集的3款颠覆认知的创意产品设计
#design-inspiration
2025年11月11日
雷克萨斯LS轿车2026年后停售,三款概念车开启豪华移动新范式
#design-inspiration
2025年11月10日
QwenImageEdit2509三大实用LoRA:重打光、多角度、电影级运镜
#ai-design
2025年11月10日
谷歌新发布DSSTAR:一站式数据科学智能体,性能超越AutoGen和DAAgent
#ai-trends
2025年10月28日
宝马跨界水上运动:首款电动立式桨板亮相,将纯粹驾驶乐趣延伸至水面
#ai-design
2025年10月28日
用ComfyUI复刻日系复古摄影:在像素里重现胶片时代的温柔瞬间
#ai-design
2025年10月27日
不止好看更实用:保时捷斯麦格联名厨房系列,从冰箱到咖啡机全解析
#design-inspiration
2025年10月27日
绝美!8个适合人像处理绝美提示语
#ai-design
2025年10月26日
Lotus Theory 1:从发布官图看路特斯性能车的未来设计DNA
#design-inspiration
2025年10月26日
贝叶斯思维产品设计不确定性的终极心智模型
#design-thinking
2025年10月25日
AI生图能有多真?日本创作者BNT的日系纪实作品
#ai-design
2025年10月25日
GPower改装宝马M4敞篷版:720马力进阶,打造高性价比敞篷性能座驾
#design-inspiration
2025年10月24日
精选UIUX设计资源合集:从动画工具到设计系统,提升效率必备
#design-resources
2025年10月24日
菲律宾巴拉望爱妮岛球形茧居:与自然共生的建筑新范式
#design-inspiration
菲
WithAI.Design
2025年10月23日
5个兼具科技感与实用性的优质设计案例,提升你的审美视野
#design-inspiration
2025年10月23日
设计师Ugur Sahin新作:保时捷960 GT RS概念车,平衡经典与电动化未来
#design-inspiration
2025年10月22日
一周内5大重磅更新!ChatGPT浏览器、Google智能编码等新工具集体亮相
#ai-trends
2025年10月22日
好图当赏karin 的AIGC作品:梦幻写实的日系瞬间,模糊AI与现实的视觉边界
#ai-design
2025年10月5日
3D关注者盯:SDF驱动的3D创作、云端协作工具Womp产品分析
#design-trends
2025年10月5日
突破传统制表逻辑!这款 生长 出来的概念腕表,重新定义可穿戴艺术
#design-inspiration
突
WithAI.Design
2025年10月4日
疯狂一周盘点:八大AI技术突破,从视频生成到商业落地全解析
#ai-trends
2025年10月4日
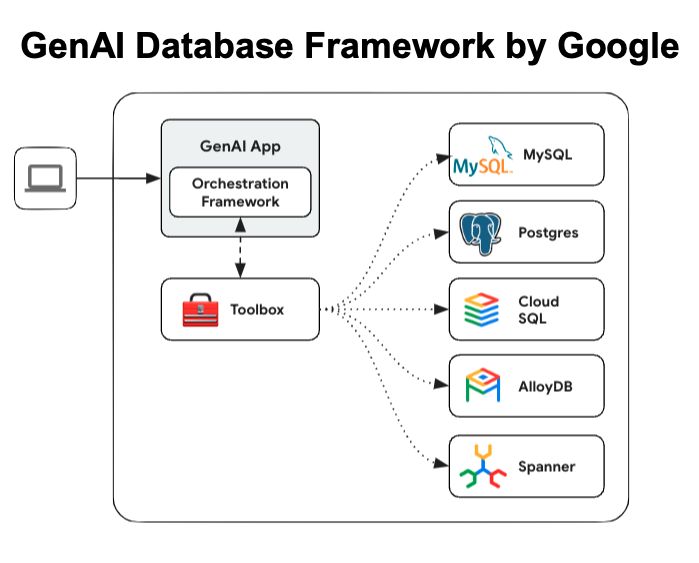
谷歌新发布!GenAI Toolbox:让SQL数据库集成AI,几行代码就能实现
#ai-trends
2025年10月3日
IBM Granite 40:超高效、高性能的企业级混合架构大模型
#ai-trends
2025年10月3日
审美提升:双节整理的3款优质产品设计,从座椅到物流再到工业设备,审美与功能兼备
#design-inspiration
2025年10月2日
OpenAI Codex 幕后工作原理(及与 Claude Code 的对比)
#ai-skills
O
WithAI.Design
2025年10月2日
可能是一盘大棋!尝试分析Sora2 产品逻辑与内核
#ai-trends
2025年10月1日
OpenAI发布Sora 2:视频生成模型新高峰?文末附上邀请码
#ai-trends
2025年10月1日
帕加尼Huayra Codalunga Speedster:复刻60年代赛车魂,10台限量的机械艺术品
#design-inspiration
2025年9月30日
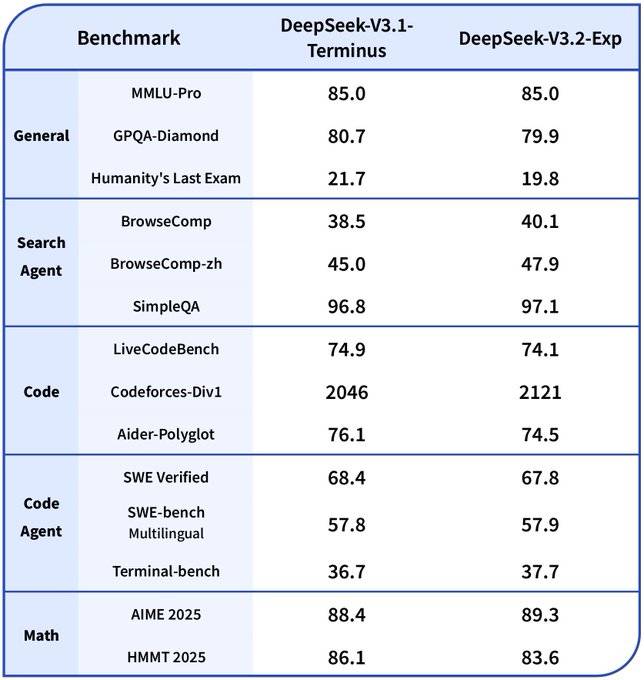
双雄对决:Claude Sonnet 45与DeepSeek V32,AI技术路线的两种突破方向
#ai-trends
双
WithAI.Design
2025年9月30日
审美提升:从包豪斯到当代,功能主义如何重塑日常美学?
#design-inspiration
2025年9月29日
并非温情复刻:Eccentrica Pacchetto Titano,让兰博基尼 Diablo 重拾赛道野性
#design-inspiration
查看更多