5分钟阅读
一种高清放大的新技术链式缩放ChainofZoom
【AI前沿】一种高清放大的新技术-链式缩放Chain-of-Zoom
前言
关于 AI 放大图像,我们一直关注,因为对于设计师或者其他的图像处理领域,放大是一个绕不开的话题。
关于 AI 放大,感兴趣的可以回顾一下:
- 【AI辅助设计】号称Maginfic的开源替代又来一个!这次好像真的能打了!
- 【AI辅助设计】可能是最好的 ComfyUI 无损放大方案?看看我做的Comfy-Topaz-Photo 插件
- 【AI辅助设计】Magnific免费用?comfyui图像增强工作流
但是,无论使用哪种技术,甚至是 tile 这类的分块处理,只要降噪强度稍微大点,都会出现莫名其妙的元素。今天的这个这个技术,似乎可以解决这个问题。如果你对此领域感兴趣,不妨仔细阅读其原理。
简介
链式缩放(CoZ)通过分步放大和智能提示的结合,突破了传统超分辨率模型的放大限制,实现了超高分辨率的图像生成。其核心在于:
- 分步放大:避免一次性放大导致的崩溃。
- 多尺度提示:用 VLM 生成的文字辅助模型理解图像。
- 强化学习优化:让提示更符合人类偏好。
这项技术为图像处理领域提供了一种新的思路,未来可能在医学影像、卫星图像等领域发挥重要作用。
效果
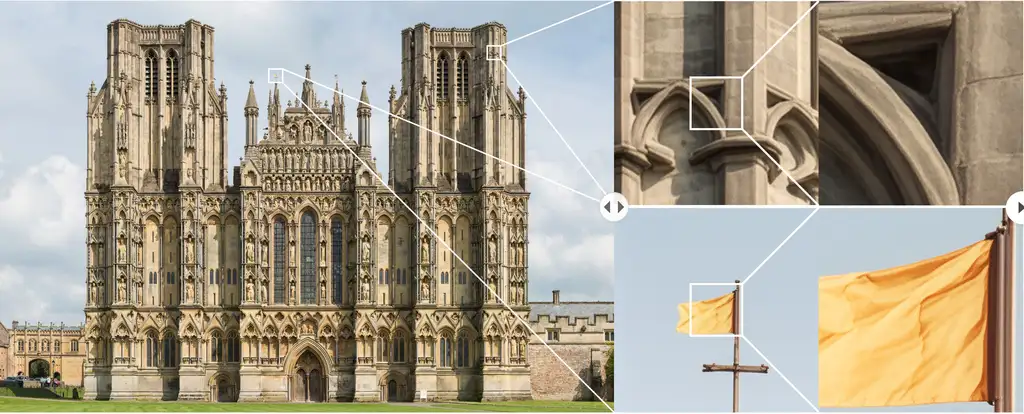
以下是官方放出的一些效果,可以把图片的细节,进行放大,且合理,确实跟一般的放大不一样。
这是官方的案例,实际本地部署后跑的,因为单 GPU 时间太长,所以只跑了一张!
输入图:

放大的位置:


放大 2X

放大 4X

如项目介绍的,结构合理,图像清晰,此技术方法效果很好👍!
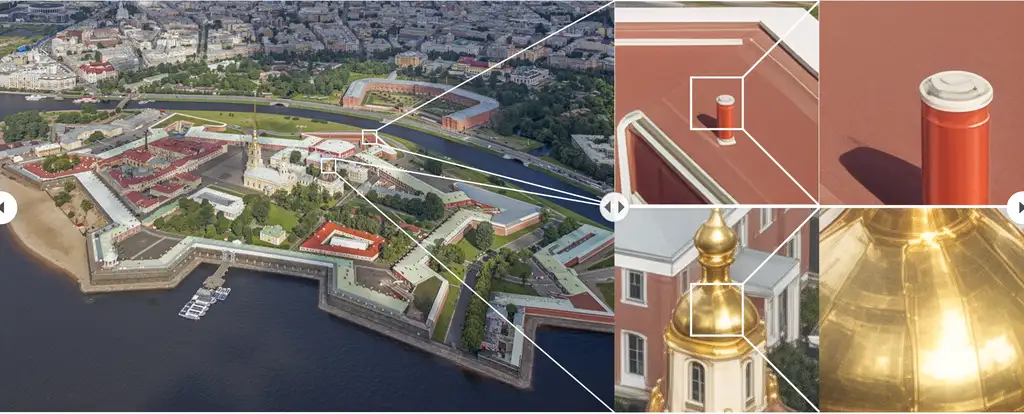
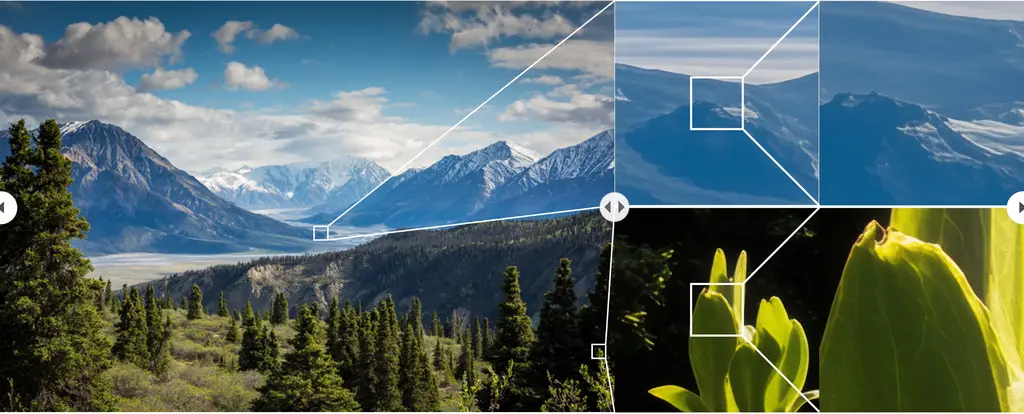
更多的官方案例:

链式缩放(Chain-of-Zoom, CoZ)技术解析
摘要
现代的单图像超分辨率(SISR)模型在训练时设定的放大倍数下能够生成逼真的图像,但如果要求放大倍数远超训练范围,模型就会失效。为了解决这一扩展性问题,我们提出了链式缩放(CoZ),这是一种与模型无关的框架,它将 SISR 分解为一系列中间缩放状态的自动回归链,并结合多尺度感知的文本提示。CoZ 通过重复使用一个基础的超分辨率模型,将条件概率分解为可处理的子问题,从而在不额外训练的情况下实现超高分辨率放大。由于在高倍放大时视觉线索会减少,我们为每一步缩放添加了由视觉语言模型(VLM)生成的多尺度感知文本提示。提示提取器本身通过**广义奖励策略优化(GRPO)**进行微调,使用一个评判 VLM 来使文本提示更符合人类偏好。实验表明,一个标准的 4 倍扩散超分辨率模型在 CoZ 框架下可以实现超过 256 倍的放大,同时保持高质量的感知效果和保真度。
技术原理通俗解释
传统超分辨率的问题
想象一下,你用一台相机拍了一张模糊的照片,然后用一个软件把它放大 4 倍。这个软件在 4 倍放大时效果很好,但如果强行放大到 256 倍,照片会变得模糊甚至出现奇怪的纹路。这是因为软件只在 4 倍放大的情况下训练过,超出这个范围就“不会”处理了。
链式缩放(CoZ)的解决方案
CoZ 的思路是:“分步放大”。就像爬楼梯一样,每次只迈一小步(比如 4 倍),然后重复这个过程。每次放大时,CoZ 还会用视觉语言模型(VLM)生成一些文字提示,比如“这是一只狗在草地上”,帮助模型更好地理解图像内容。这样,通过多次小步放大和文字提示的辅助,最终可以实现超高倍数的放大,而不会让图像崩溃。
如何让文字提示更“聪明”?
为了让 VLM 生成的提示更符合人类的偏好,研究人员用了一种新的强化学习方法(GRPO)。简单来说,就是让另一个评判模型(critic VLM)给提示打分,奖励那些语义清晰、简洁的提示,惩罚那些重复或无关的内容。通过这种训练,VLM 生成的提示会更准确,从而帮助超分辨率模型生成更逼真的图像。
方法
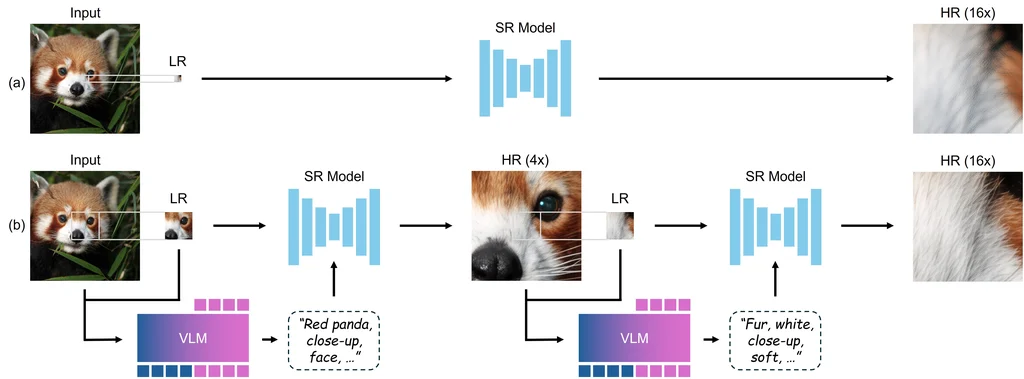
(a) 传统超分辨率
当一个仅针对固定放大倍数(如 4 倍)训练的超分辨率模型被强行用于更高倍数的放大时,会产生模糊和伪影。
(b) 链式缩放(CoZ)
从低分辨率输入开始,预训练的 VLM 生成描述性提示,这些提示与图像一起输入到同一个超分辨率模型中,生成下一个高分辨率状态。这种“提示-放大”循环不断重复,使得一个现成的模型可以逐步放大到超高分辨率(16 x-256 x),同时保持细节清晰和语义保真。
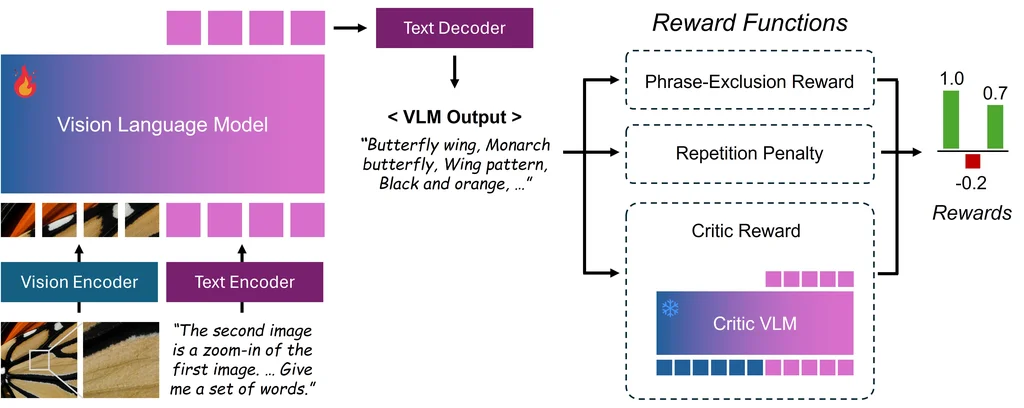
为了生成更符合人类偏好的文本提示,我们通过GRPO 强化学习流程对提示提取 VLM 进行微调。评判 VLM 用于评估提示的语义质量,同时通过短语排除和重复惩罚机制确保提示简洁且相关。
实验结果
1. 对比结果

不同方法的超分辨率效果:
- (a) 最近邻插值法:放大后图像模糊。
- (b) 单步直接超分辨率:在高倍数下失效。
- (c-e) 不同文本提示的 CoZ 变体:生成更高质量的图像。VLM 提示帮助克服了原始输入信号的稀疏性,生成了更逼真的图像。
2. GRPO 对 VLM 的影响
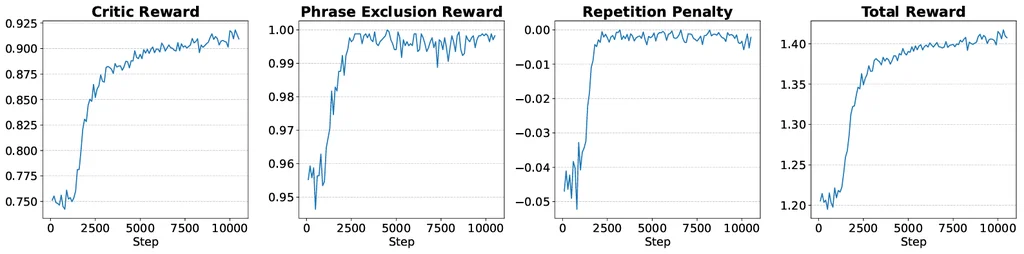
在训练初期,短语排除奖励和重复惩罚分别收敛到 1.00 和 0.00,而评判奖励在整个训练过程中逐渐增加。

- 基础 VLM:仅从低分辨率输入生成提示,容易产生错误(如错误的“狗”提示)。
- 多尺度图像提示:在低倍数下有效(如准确的“狗、棍子、水”提示),但在高倍数下失效。
- 符合人类偏好的 VLM:生成的提示更准确,指导效果更好。
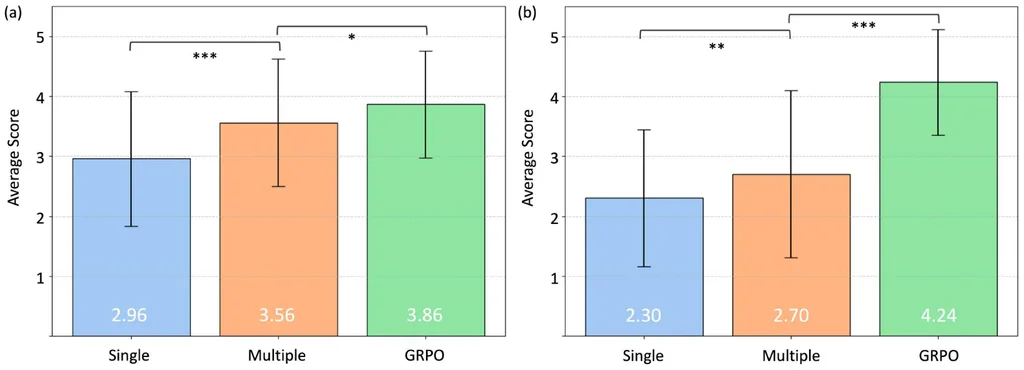
通过人类偏好图像生成和人类偏好文本生成的平均意见分数(MOS)测试,验证了 GRPO 微调 VLM 能够显著提升与人类偏好的对齐程度。
如何使用?
硬件要求和环境
- 目前代码最低支持 24 G 显存的 GPU,且推荐双 GPU 运行。
- 环境需要 Linux,也可以是 wsl 环境。
官方使用
官方 github 地址:https://github.com/bryanswkim/Chain-of-Zoom,可以按照官方的指引安装依赖和运行 py 即可。
使用Gradio 界面版本
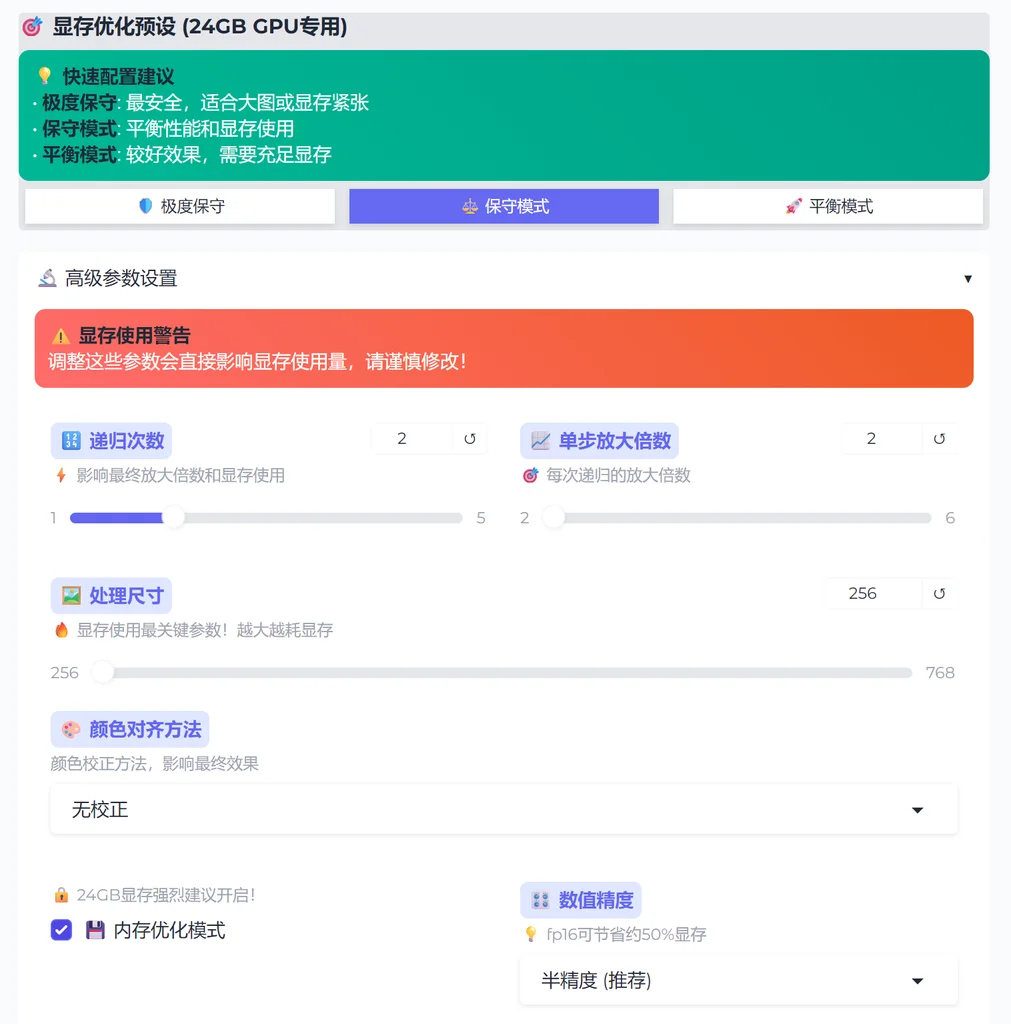
我根据官方的代码,做了一个 gradio 界面,增加了些预设。便于理解参数和根据 gpu 进行合理的运行参数。
感兴趣可以访问:https://github.com/leoleelxh/Chain-of-Zoom-webui
友好的中文界面
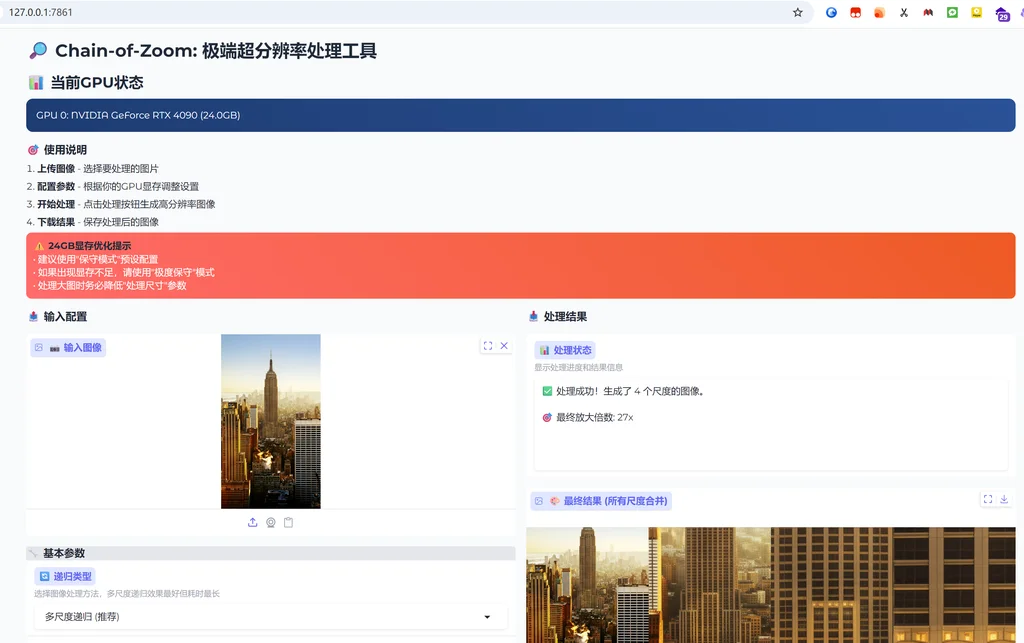
预设功能
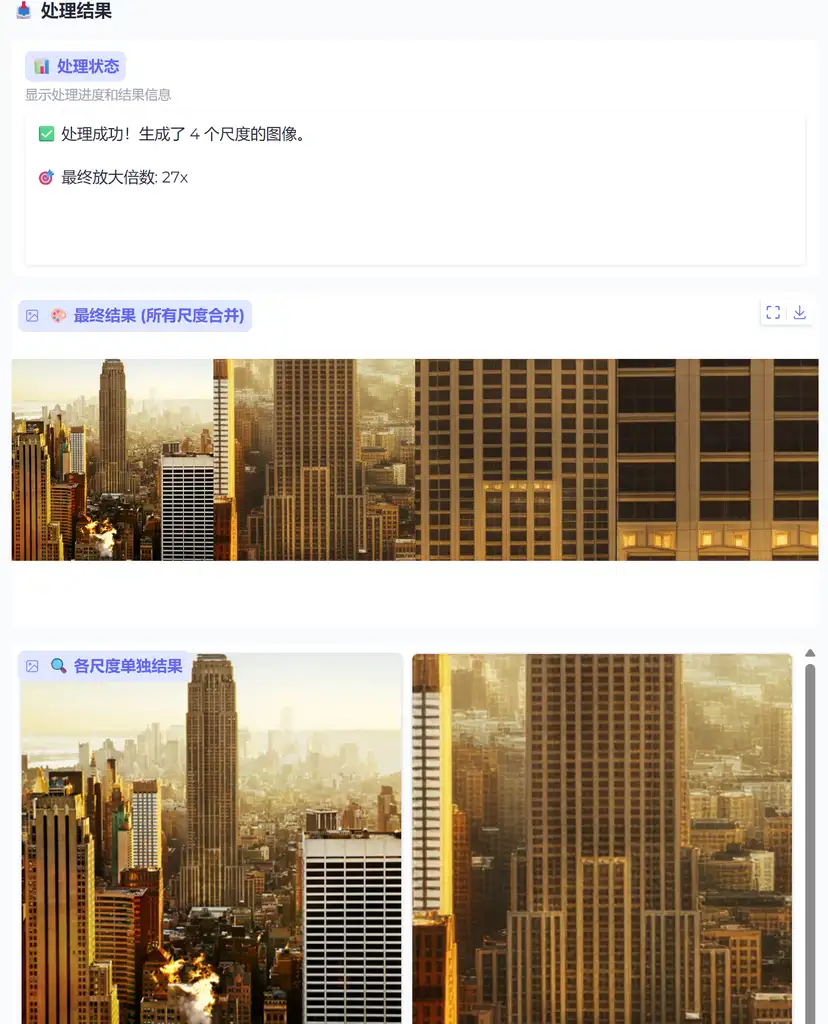
阅览功能
使用 webui 版本方法
git clone https://github.com/leoleelxh/Chain-of-Zoom-webui
cd Chain-of-Zoom-webui
conda create -n coz python=3.10
conda activate coz
pip install -r requirements.txt
python gradio_interface_cn.py
想获取更多 AI 辅助设计和设计灵感趋势? 欢迎关注我的公众号(设计小站):sjxz 00。