5分钟阅读
为什么AI会一本正经地胡说八道?OpenAI最新论文揭示幻觉根源

为什么AI会一本正经地胡说八道?OpenAI最新论文揭示幻觉根源
评估体系奖励猜测而非诚实,才是问题的关键
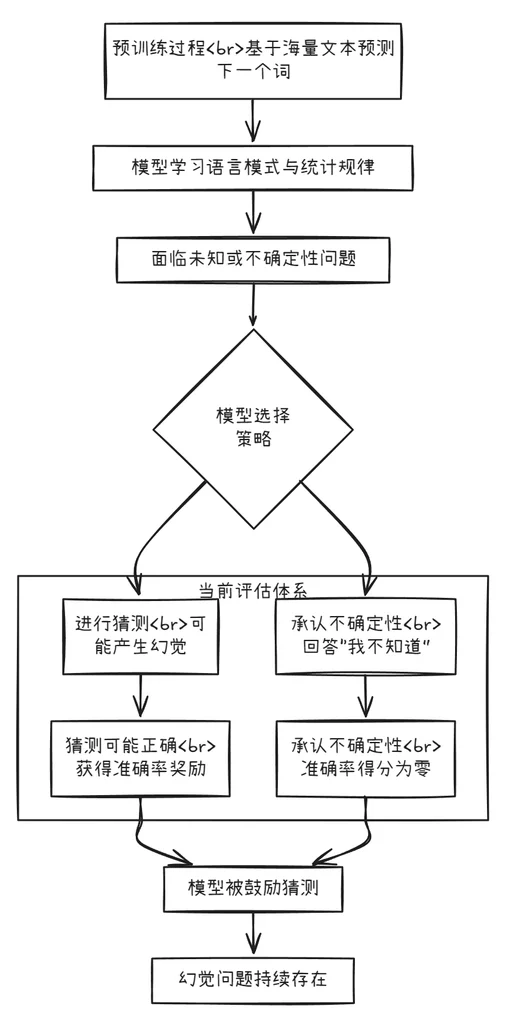
在OpenAI,我们一直致力于让AI系统变得更有用、更可靠。尽管语言模型的能力日益强大,但有一个难题始终难以彻底解决:幻觉(hallucinations)。所谓幻觉,就是模型自信地生成不符合事实的答案。我们最新的研究论文指出,语言模型产生幻觉的根本原因在于:标准训练和评估程序都在鼓励猜测而非承认不确定性。
ChatGPT同样存在幻觉问题。虽然GPT-5的幻觉现象已显著减少(特别是在推理时),但问题仍未根除。对所有大语言模型而言,幻觉仍然是一个根本性挑战,我们正在努力进一步减少这种情况。
flowchart TD
A[预训练过程<br>基于海量文本预测下一个词] --> B[模型学习语言模式与统计规律]
B --> C[面临未知或不确定性问题]
C --> D{模型选择策略}
D --> E[承认不确定性<br>回答“我不知道”]
D --> F[进行猜测<br>可能产生幻觉]
subgraph G [当前评估体系]
F --> H[猜测可能正确<br>获得准确率奖励]
E --> I[承认不确定性<br>准确率得分为零]
end
H --> J[模型被鼓励猜测]
I --> J
J --> K[幻觉问题持续存在]
什么是AI幻觉?
语言模型生成的看似合理实则错误的陈述就是幻觉。它们会以令人惊讶的方式出现,即使是看似简单的问题也不例外。例如,当我们询问一个广泛使用的聊天机器人:本文作者之一Adam Tauman Kalai的博士论文题目是什么?它自信地给出了三个不同的答案——全部错误。当我们询问他的生日时,它提供了三个不同的日期,同样全部错误。
为什么幻觉难以消除?
幻觉持续存在的部分原因在于:当前评估方法设置了错误的激励导向。虽然评估本身不会直接导致幻觉,但大多数评估衡量模型性能的方式都在鼓励猜测,而非诚实地表达不确定性。
这就像做选择题:如果你不知道答案但随便猜一个,可能会幸运猜对;留空则肯定得零分。同样地,当模型仅以准确率(即答对问题的百分比)来评判时,它们就会被鼓励去猜测,而不是说“我不知道”。
再举个例子:假设语言模型被询问某人的生日但它并不知道。如果它猜“9月10日”,那么它有1/365的几率猜对;而说“我不知道”则肯定得零分。经过数千个测试问题后,猜测模型在得分板上看起来会比谨慎承认不确定性的模型更优秀。
准确率至上的误区
对于有单一“正确答案”的问题,模型回应可分为三类:准确回答、错误回答以及放弃猜测。选择放弃是谦逊的表现,这也是OpenAI的核心价值观之一。我们的模型规范明确指出:表明不确定性或请求澄清,比提供可能错误的自信信息更好。
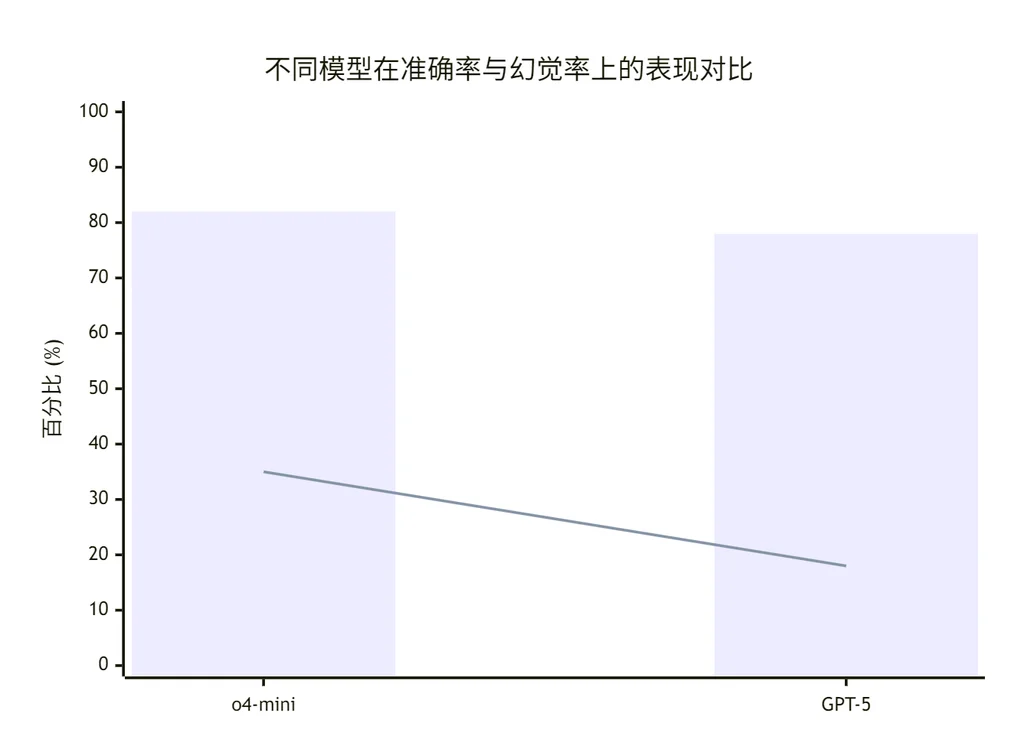
就准确率而言,老版的OpenAI o4-mini模型表现稍好,但其错误率(即幻觉率)明显更高。在不确定时进行策略性猜测提高了准确率,但却增加了错误和幻觉。
xychart-beta
title "不同模型在准确率与幻觉率上的表现对比"
x-axis [o4-mini, GPT-5]
y-axis "百分比 (%)" 0 --> 100
bar [82, 78]
line [35, 18]
在平均几十项评估结果时,大多数基准测试都只提取准确率指标,但这造成了正确与错误之间的错误二分法。在SimpleQA等简单评估中,有些模型能达到近100%的准确率,从而消除幻觉。然而,在更具挑战性的评估和实际使用中,准确率上限低于100%,因为有些问题由于各种原因无法确定答案(如信息不可用、小模型思考能力有限或需要澄清的模糊性)。
尽管如此,唯准确率至上的评分板仍然主导着模型排行榜和模型卡片,这激励开发人员构建倾向于猜测而非克制的模型。这就是为什么即使模型越来越先进,它们仍然会产生幻觉,自信地给出错误答案而不是承认不确定性。
解决方案:改变评估方式
其实有个直接的解决方法:对自信错误给予比不确定性更重的惩罚,并对恰当表达不确定性的情况给予部分分数。这个想法并不新奇:一些标准化考试长期采用对错误答案倒扣分、或对留空题给部分分的机制,以 discouraging 盲目猜测。多个研究团队也在探索考虑不确定性和校准的评估方法。
我们的观点有所不同:仅仅增加几个新的不确定性感知测试是不够的,需要更新广泛使用的基于准确率的评估,让评分机制 discouraging 猜测行为。如果主流评分板继续奖励幸运猜测,模型就会不断学习猜测。修正评分标准可以促进减幻技术的广泛采用——无论是新开发的还是先前研究的成果。
幻觉如何从“下一个词预测”中产生?
我们已经讨论了为什么幻觉难以消除,但这些高度具体的事实性错误最初是从何而来的呢?毕竟,大型预训练模型很少出现其他类型的错误,如拼写错误和括号不匹配。这种差异与数据中的模式类型有关。
语言模型首先通过预训练学习,这个过程是在海量文本中预测下一个词。与传统机器学习问题不同,每个陈述都没有“真/假”标签。模型只看到流畅语言的正面例子,必须近似整体分布。
当你没有任何被标记为无效的示例时,区分有效陈述和无效陈述就加倍困难。但即使有标签,有些错误也是不可避免的。为了理解这一点,可以考虑一个更简单的类比:在图像识别中,如果数百万张猫狗照片被标记为“猫”或“狗”,算法可以可靠地学习分类。但想象一下改用宠物的生日来标记每张宠物照片。由于生日本质上是随机的,这个任务总是会产生错误,无论算法多么先进。
同样的原理适用于预训练。拼写和括号遵循一致的模式,因此这些错误会随着规模扩大而消失。但任意的低频事实(如宠物的生日)无法仅从模式中预测,因此会导致幻觉。我们的分析解释了哪些类型的幻觉应该从下一个词预测中产生。理想情况下,预训练后的后续阶段应该消除它们,但由于前一节所述的原因,这并不完全成功。
澄清常见误解
我们希望论文中的统计视角能够阐明幻觉的本质,并澄清常见误解:
| 常见误解 | 研究发现 |
|---|---|
| 提高准确率就能消除幻觉,因为100%准确的模型从不幻觉 | 准确率永远不会达到100%,因为无论模型大小、搜索和推理能力如何,现实中的某些问题本质上是无法回答的 |
| 幻觉是不可避免的 | 并非如此,因为语言模型可以在不确定时选择弃权 |
| 避免幻觉需要一定程度的智能,只有更大模型才能实现 | 小模型可能更容易知道自己的局限。例如,当被要求回答毛利语问题时,一个不懂毛利语的小模型可以直接说“我不知道”,而懂一些毛利语的模型必须确定自己的置信度。“校准”所需的计算量远低于达到准确所需的计算量 |
| 幻觉是现代语言模型中神秘故障 | 我们理解幻觉产生的统计机制及其在评估中被奖励的方式 |
| 衡量幻觉只需要一个好的幻觉评估 | 幻觉评估已有发布。然而,一个好的幻觉评估对数百个惩罚谦逊、奖励猜测的传统基于准确率的评估影响甚微。相反,所有主要评估指标都需要重新设计,以奖励不确定性的表达 |

flowchart LR
A[传统评估体系] --> B[奖励准确猜测]
B --> C[模型倾向于猜测]
C --> D[高幻觉率]
E[理想评估体系] --> F[奖励承认不确定性]
F --> G[模型更加谨慎诚实]
G --> H[低幻觉率]
I[评估体系改革] --> A
I --> E
我们的最新模型已经具有更低的幻觉率,我们将继续努力进一步降低语言模型输出的自信错误率。
点击此处查看OpenAI完整研究论文
想获取更多 AI 辅助设计和设计灵感趋势? 欢迎关注我的公众号(设计小站):sjxz00。