5分钟阅读
从单图到可缩放世界:三款前沿AI工具如何重塑3D与设计流程
从单图到可缩放世界:三款前沿AI工具如何重塑3D与设计流程
前言
对于设计师而言,从静态的二维概念迈向动态、可交互的三维世界,往往意味着高昂的学习成本和繁琐的制作流程。然而,随着AI技术的飞速发展,这一壁垒正在被打破。今天,我们将介绍三款前沿的AI研究项目:它们分别致力于从单张图片生成可无限放大的3D世界、为任意3D模型捕捉动作,以及智能生成或分解分层的PSD文件。这些工具不仅展示了技术的可能性,更预示着未来设计工作流程的革命性简化。
正文
WonderZoom:从单图生成多尺度3D世界





作者: Jin Cao, Hong-Xing Yu, Jiajun Wu

摘要
WonderZoom 能够从单张图像生成跨越多个空间尺度的3D场景,其核心在于使用了尺度自适应的高斯面元和渐进式细节合成器,在生成质量和场景对齐度上都超越了现有模型。

现有的3D世界生成模型通常局限于单一尺度的合成,无法在不同粒度上生成连贯的场景内容。根本挑战在于缺乏一种能够生成和渲染空间尺寸差异巨大的内容的、具备尺度感知能力的3D表示方法。
WonderZoom通过两项关键创新解决了这一问题:
- 尺度自适应高斯面元:用于生成和实时渲染多尺度3D场景。
- 渐进式细节合成器:能够迭代生成更精细尺度的3D内容。
该方法使用户能够“放大”3D场景的某个区域,并自回归地合成从风景到微观特征等原本不存在的精细细节。实验表明,WonderZoom在质量和对齐度上均显著优于当前最先进的视频和3D模型,实现了从单张图像创建多尺度3D世界。
项目主页与交互体验: 你可以在 https://wonderzoom.github.io/ 查看视频结果和生成的多尺度3D世界的交互式查看器。
交互操作指南:
- 键盘:使用“W/A/S/D”移动,使用“I/J/K/L”环顾四周。按“F”键围绕中心点旋转。点击“Scale 0/1/2”按钮进行缩放。
- 注意:点击图像将从匿名来源自动下载生成的世界示例(约100MB)。加载后,请点击画布以激活控制。此处的渲染是在你的设备上实时进行的。由于网页渲染器不支持我们提出的多尺度表示渲染,并应用了深度量化,渲染质量相比上方视频有所下降。
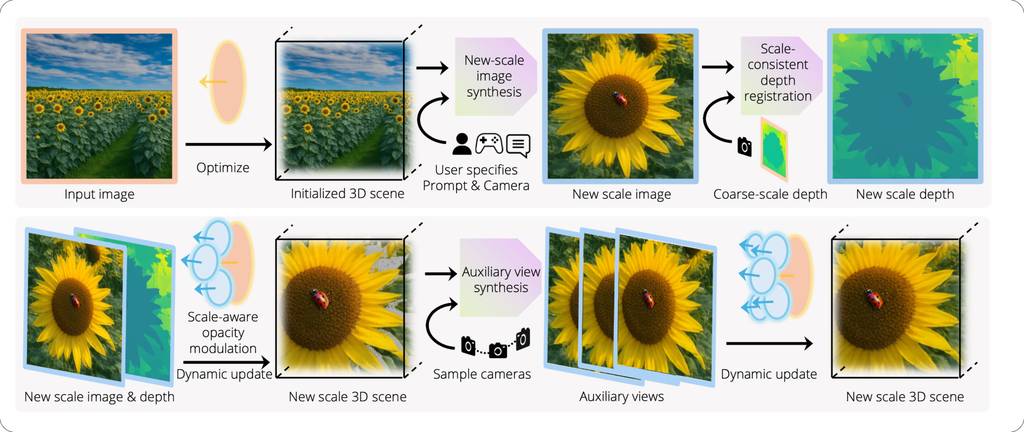
工作原理简述: 从输入图像开始,系统首先重建一个初始3D场景。用户指定提示词和相机视角来生成更精细尺度的内容。我们的渐进式细节合成器会创建新尺度的图像,配准深度以保持几何一致性,并合成辅助视图以完成3D场景的创建。我们的尺度自适应高斯面元支持动态更新而无需重新优化,能够无缝集成新内容,同时保持实时渲染。
MoCapAnything:为任意骨骼从单目视频进行统一3D动作捕捉




作者: Kehong Gong, Zhengyu Wen, Weixia He, Mingxi Xu, Qi Wang, Ning Zhang, Zhengyu Li, Dongze Lian, Wei Zhao, Xiaoyu He, Mingyuan Zhang
摘要
MoCapAnything 是一个参考引导的框架,能够从单目视频中为任意绑定骨骼的3D资产重建基于旋转的动画(如BVH格式),实现跨物种的动作重定向和可扩展的3D动作捕捉。
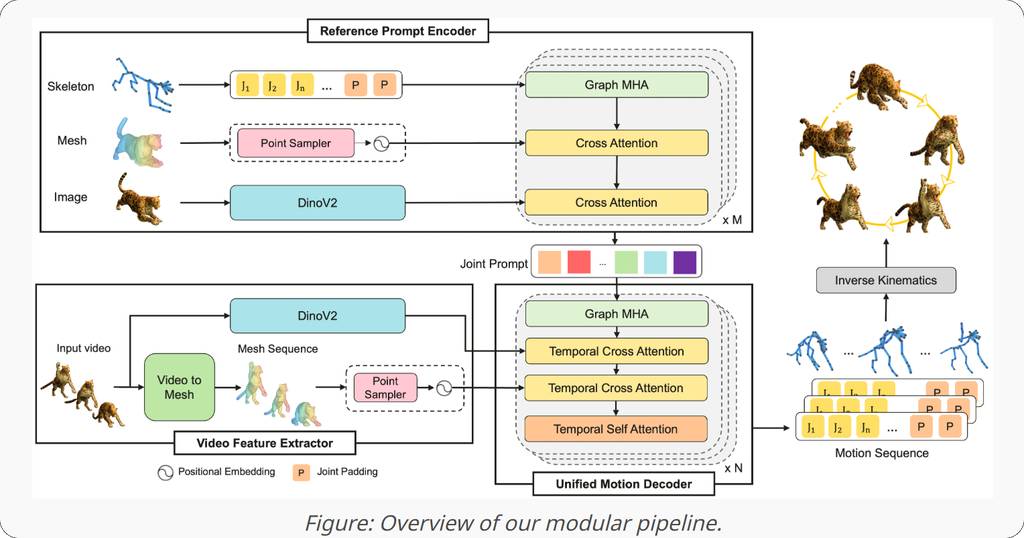
动作捕捉技术如今支撑着远超数字人范畴的内容创作,但大多数现有流程仍然局限于特定物种或模板。我们将这一差距形式化为类别无关动作捕捉:给定一个单目视频和一个任意绑定骨骼的3D资产作为提示,目标是重建一个可以直接驱动该特定资产的、基于旋转的动画。
我们提出了 MoCapAnything,这是一个参考引导的、因子分解的框架:它首先预测3D关节轨迹,然后通过约束感知的逆运动学恢复资产特定的旋转。

该系统包含三个可学习模块和一个轻量级IK阶段:
- 参考提示编码器:从资产的骨骼、网格和渲染图像中提取每个关节的查询特征。
- 视频特征提取器:计算密集的视觉描述符,并重建一个粗糙的4D变形网格,以弥合视频空间和关节空间之间的差距。
- 统一运动解码器:融合这些线索,生成时间上连贯的关节轨迹。
我们还策划了 Truebones Zoo 数据集,包含1038个动作片段,每个片段都提供了一个标准化的“骨骼-网格-渲染”三元组。在领域内基准测试和真实世界视频上的实验表明,MoCapAnything能够提供高质量的骨骼动画,并在异构的骨骼绑定之间展现出有意义的跨物种动作重定向能力,从而实现了为任意资产进行可扩展的、提示驱动的3D动作捕捉。
项目主页: https://animotionlab.github.io/MoCapAnything/
OmniPSD:基于扩散Transformer的分层PSD生成
作者:
Cheng Liu, Yiren Song, Haofan Wang, Mike Zheng Shou





摘要
OmniPSD 是构建在Flux生态系统中的一个扩散框架,能够实现文生PSD和图生PSD分解,在保持透明度感知的同时,实现了高保真度的结果。
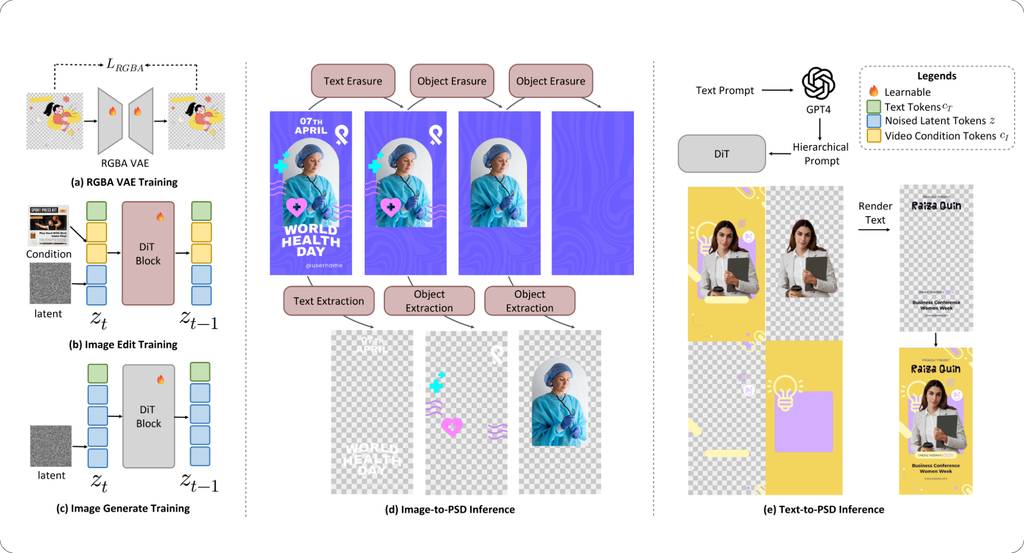
扩散模型的近期进展极大地改善了图像生成和编辑,但生成或重建带有透明通道的分层PSD文件仍然极具挑战性。

我们提出了 OmniPSD,这是一个基于Flux生态系统构建的统一扩散框架,通过上下文学习,既能实现文生PSD,也能实现图生PSD分解。

- 对于文生PSD:OmniPSD将多个目标图层在空间上排列到单个画布中,并通过空间注意力学习它们之间的组合关系,从而生成语义连贯、层次结构清晰的图层。
- 对于图生PSD分解:它执行迭代式上下文编辑,逐步提取和擦除文本及前景组件,从而从单张扁平化的图像中重建可编辑的PSD图层。

系统采用了一个RGBA-VAE作为辅助表示模块,在不影响结构学习的情况下保留透明度信息。在我们新的RGBA分层数据集上进行的大量实验表明,OmniPSD实现了高保真度的生成、结构一致性和透明度感知,为基于扩散Transformer的分层设计生成与分解提供了新的范式。
写在最后
从WonderZoom对空间尺度的无限探索,到MoCapAnything对动作通用性的突破,再到OmniPSD对设计源文件的智能理解与生成,这三项研究清晰地指向一个未来:AI正从执行命令的工具,转变为理解意图、拓展创意边界的合作伙伴。对于设计师来说,这意味着可以将更多精力集中于概念构思、审美判断和叙事构建等核心创意环节,而将繁琐、技术性的实现工作交给AI。拥抱这些变化,或许就是打开下一代设计大门的关键。
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。