5分钟阅读
值得关注的几个AI消息

前言
又一个月过去了,距离上次分享AI前沿消息的这段时间,AI界又涌现出不少新技术。今天带大家看看。上期的大家也可以回顾一下,感觉新的技术很快又被更新的技术所替代了,比娱乐圈的热门更新更快、更猛🤦♂️。# 【AI前沿】值得关注的几个AI信息
几个消息
相信重磅(也会列出来)的消息,大家都能在其他地方看到了,我只讲一些不在重磅列表里的,但是值得关注的消息:
- 【重磅】快手发布新版视频生成模型可灵2.0,同时上线网页端。(这个太火了,今天就不聊了~😂)
- 【重磅】快手发布基于SDXL和GLM的生图模型可图,效果很顶!这个我带大家看看测试一下效果。
- UltraPixel-效果很顶的图像放大方法,香港科技大学(广州)、华为团队发布。
- Lora-ease-训练LoRA更方便。不过安装过程有些bug,但是速度和易用性确实不错。
1.【重磅】快手发布新版视频生成模型可灵2.0
效果很炸裂,因为太火,消息已经铺天盖地了,我这里略过~🚬。
2. 【重磅】快手发布基于SDXL和GLM的生图模型可图
快手在AI上的动作和成果,真的让人惊呆🤯,除了可灵,可图的效果也同样炸裂,不仅在出图效果上,综合评分超过了SD3和MJ,在提示语理解和中文生成方面,也非常惊人。
可图 (Kolors): 快手出品的高质量、双语文本到图像生成模型
Kolors 是由快手可图团队开发的大规模文本到图像生成模型,基于潜在扩散模型,并在数十亿个图文对上进行了训练。Kolors 在视觉质量、复杂语义准确性和中英文文本渲染方面均优于开源和闭源模型。Kolors 支持中英文双语输入,并对中文内容的理解和生成表现出色。
主要优势:
- 高质量图像生成: Kolors 在人脸肖像、中国元素、复杂语义和文本渲染方面表现出色,生成高质量、细节丰富的图像。
- 双语支持: Kolors 同时支持中文和英文输入,并能准确理解和生成中文特定内容。
- 高效的训练和推理: Kolors 在紧凑的潜在空间中进行操作,共享大部分参数,从而提高了效率。
评估结果:
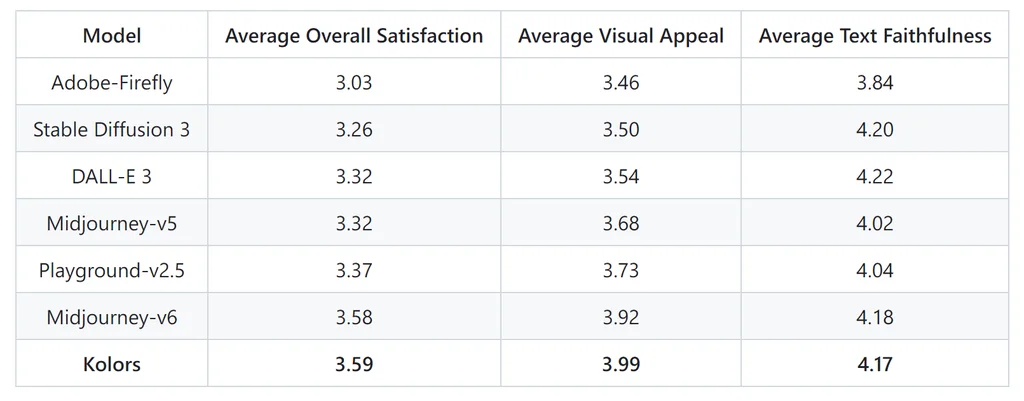
为了评估 Kolors 的性能,快手团队收集了一个名为 KolorsPrompts 的综合性评估数据集,其中包含 14 个类别和 12 个评估维度的 1000 多个提示。评估过程结合了人工和机器评估。
人工评估:
50 位图像专家对不同模型生成的图像进行了比较评估,根据视觉吸引力、文本忠实度和总体满意度三个标准进行评分。Kolors 在总体满意度得分方面排名最高,并且在视觉吸引力方面明显领先于其他模型。

机器评估:
使用 MPS(多维人类偏好评分)对 KolorsPrompts 数据集进行机器评估。Kolors 实现了最高的 MPS 分数,这与人工评估的结果一致。
开源计划:
Kolors 已经完全开源用于学术研究,并提供推理代码、检查点、LoRA、ControlNet 和 IP-Adapter 等资源。商业用途需联系快手可图团队获取免费使用协议。
可图的亮点:
- Kolors 在多个基准测试中表现出极强的竞争力,达到了行业领先水平。
- Kolors 能够生成具有丰富细节和高度真实感的图像。
- Kolors 对中文内容有深入的理解,可以生成高质量的中文相关图像。



总结:
Kolors 是快手可图团队在文本到图像生成领域的一项重要成果,它以高质量的图像生成、双语支持和开源特性,为研究者和开发者提供了一个强大的工具,并推动了文本到图像生成技术的进一步发展。
项目地址: https://github.com/Kwai-Kolors/Kolors
如何使用
本地部署
官方提供在线和本地部署的体验:
要求
- Python 3.8 or later
- PyTorch 1.13.1 or later
- Transformers 4.26.1 or later
- Recommended: CUDA 11.7 or later
- 项目拉取和安装依赖
apt-get install git-lfs
git clone https://github.com/Kwai-Kolors/Kolors
cd Kolors
conda create --name kolors python=3.8
conda activate kolors
pip install -r requirements.txt
python3 setup.py install
- 模型下载(link):
huggingface-cli download --resume-download Kwai-Kolors/Kolors --local-dir weights/Kolors
或者
git lfs clone https://huggingface.co/Kwai-Kolors/Kolors weights/Kolors
- 示例:
python3 scripts/sample.py "一张瓢虫的照片,微距,变焦,高质量,电影,拿着一个牌子,写着“可图”"
# The image will be saved to "scripts/outputs/sample_text.jpg"
- Web demo:
python3 scripts/sampleui.py
ComfyUI
目前官方认可的ComfyUI的工作流https://github.com/kijai/ComfyUI-KwaiKolorsWrapper,可以在项目地址找得到。我试着出了几张图,效果确实不错。模型比较大,貌似需要16G显存以上才能运行。
3. UltraPixel: 将超高分辨率图像合成推向新高峰
还没放出代码,看效果真的很不错!一旦发布,独霸一方的magnific的放大功能,是不是“危”了~🤔。
项目地址:
https://jingjingrenabc.github.io/ultrapixel/#paper-info
论文概述:
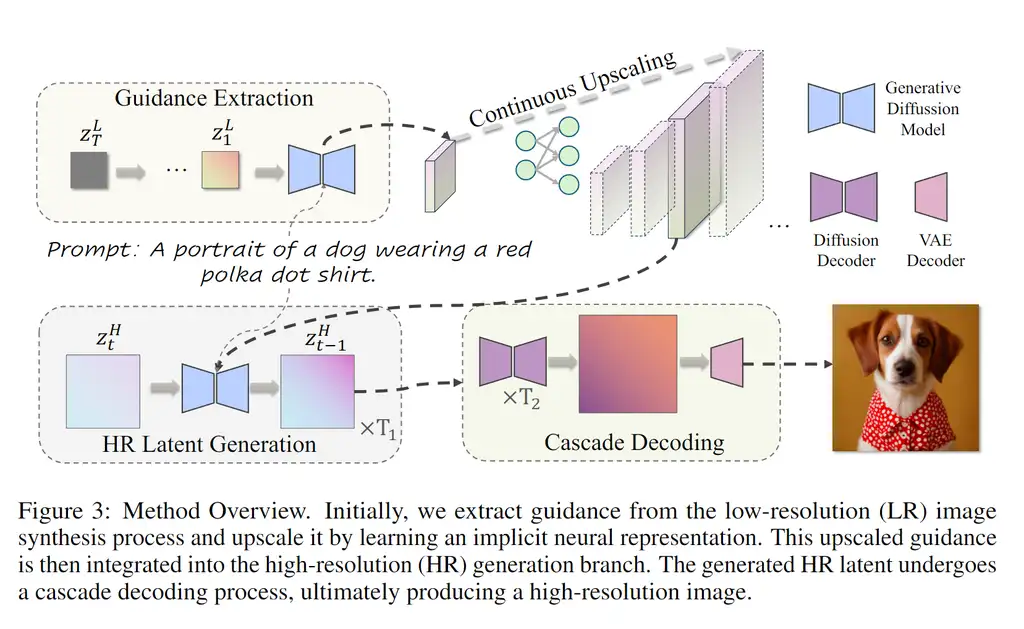
这篇论文介绍了 UltraPixel,一种利用级联扩散模型在单个模型中生成多种分辨率(例如 1K 到 6K)高质量图像的新颖架构,同时保持计算效率。UltraPixel 利用低分辨率图像中语义丰富的表示,在后期去噪阶段引导整个高分辨率图像的生成,从而显著降低复杂性。此外,该方法还引入了隐式神经表示以实现连续上采样,以及可适应各种分辨率的尺度感知归一化层。值得注意的是,低分辨率和高分辨率过程都在最紧凑的空间中执行,共享大部分参数,高分辨率输出分支仅需额外增加不到 3% 的参数,极大地提高了训练和推理效率。该模型能够以较少的训练数据快速完成训练,生成照片级真实感的高分辨率图像,并在大量实验中展示了最先进的性能。

UltraPixel 的关键理念:

-
级联架构: 基于 StableCascade 架构,其 42:1 的高压缩率提供了一个紧凑的潜在空间,使得高效生成高分辨率图像成为可能。
-
低分辨率引导: 从低分辨率图像的生成过程中提取内部特征作为语义和结构引导,用于指导高分辨率图像的生成。
-
连续上采样: 使用隐式神经表示 (INR) 将低分辨率引导特征连续上采样到任意分辨率,确保一致的引导信息。
-
尺度感知归一化: 开发了尺度感知的、可学习的归一化层,以适应不同分辨率的数值差异,提高模型对不同分辨率的适应性。
UltraPixel 的优势:
- 高效率: 与全模型微调相比,UltraPixel 只需要训练少量参数,显著降低了计算成本和内存需求。
- 高质量: 生成图像质量高,可与 DALL·E 3 和 Midjourney V6 等领先的闭源商业产品相媲美。
- 多分辨率: 能够高效地生成多种分辨率(例如 1K 到 6K,包括不同的宽高比)的图像。
- 可控性: 可以通过边缘图控制图像生成,并支持个性化微调。
实验结果:
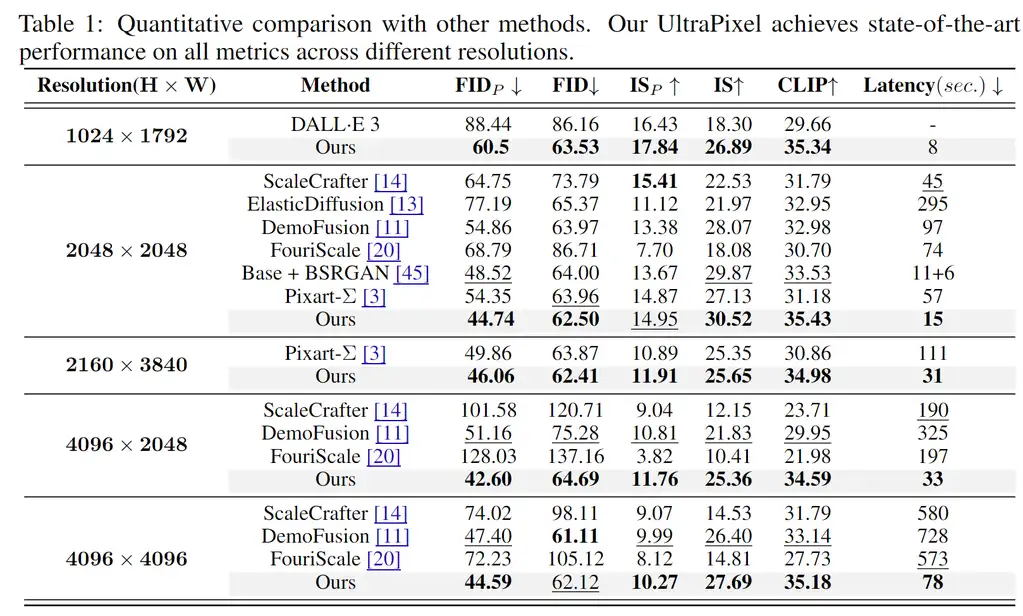
论文在多个数据集和任务上进行了实验,结果表明:
- 在各种分辨率下,UltraPixel 在感知导向的 PickScore [24] 指标上优于其他方法,表明其生成的图像更符合人类偏好。
- 与基于训练的 Pixart-Σ [3] 相比,UltraPixel 使用更少的参数和训练数据,却能生成质量更高的图像。
- 推理效率高,生成高分辨率图像的速度明显快于 Pixart-Σ 和其他训练免费的 HR 生成方法。


UltraPixel 是一种高效且高质量的超高分辨率图像生成方法,它通过利用低分辨率引导和新的网络设计,克服了超高分辨率图像生成中的挑战,将图像合成技术推向了一个新的高度。 UltraPixel 提供了一种有效且高效的方法来生成各种分辨率的逼真图像,其对计算资源的要求相对较低,为超高分辨率图像合成领域提供了一个有前景的方向。
4. SD-XL LoRA 微调的最佳实践:社区指南
这个技术把 Replicate 在 SDXL Cog 训练器中使用的枢轴微调 (Pivotal Tuning) 技术与 Kohya 训练器中使用的 Prodigy 优化器相结合,再加上一堆其他优化,一起对 SDXL 进行 Dreambooth LoRA 微调,取得了非常好的效果。你可以在
diffusers上找到 我们使用的训练脚本🧨,或是直接 在 Colab 上 试着运行一下。 总之,训练LoRA变得更加容易,且效果更好。 文章地址:https://huggingface.co/blog/zh/sdxl_lora_advanced_script
本地部署的界面长这样,确实很简单了:
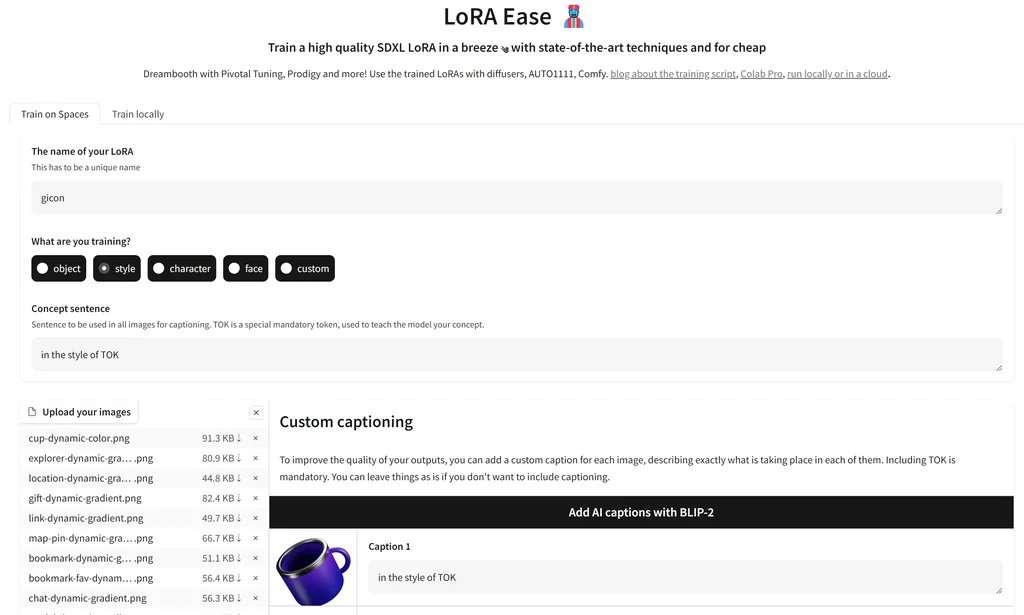
这篇文章总结了使用 LoRA 和 Dreambooth 微调 SD-XL 模型的最佳实践,包括:
关键技术:
- Pivotal Tuning: 结合 Textual Inversion 和扩散模型微调,通过插入新词元到模型的文本编码器中来表示新概念,避免使用已有词元带来的语义干扰。
- 自适应优化器: 使用 Adafactor 或 Prodigy 等自适应优化器,根据参数的梯度历史动态调整学习率,提高训练效率和结果质量。
- 其他最佳实践:
- 独立的文本编码器和 UNet 学习率: 文本编码器容易过拟合,因此使用较低的学习率进行训练。
- 自定义标题: 为每个训练图像提供独特的标题,有助于模型更好地理解和泛化新概念。
- Min-SNR Gamma 加权: 根据信噪比调整损失权重,平衡时间步之间的优化方向冲突,提高训练速度。
* **重复:** 增加训练集的重复次数,强化模型对新概念的学习。 * **训练集创建:** 使用高质量、多样化的图像,并注意主题的突出和构图的多样性。 * **优先保留损失:** 利用模型自己生成的样本或真实图像进行正则化,帮助模型学习生成更具多样性的图像,并保留其对类别的理解。
* **优先保留损失:** 利用模型自己生成的样本或真实图像进行正则化,帮助模型学习生成更具多样性的图像,并保留其对类别的理解。

实验结果:
文章通过 Huggy Dreambooth LoRA 和 Y2K 网页 LoRA 两个例子展示了不同技术组合的效果,并分析了不同参数设置的影响。


推理:
文章介绍了使用 diffusers 和 AUTOMATIC1111/ComfyUI 进行推理的步骤,包括如何加载 LoRA 权重和新词元的文本嵌入。
总结:
这篇文章为 SD-XL LoRA 微调提供了一套全面的最佳实践指南,帮助用户更高效地训练出高质量的 LoRA 模型。
未来展望:
文章提到将继续开发更多功能,例如多概念 LoRA 和 ZipLoRA,以进一步提升 SD-XL LoRA 微调的灵活性和控制能力。
其他要点
- 文章提供了丰富的代码示例和实验结果,方便用户理解和实践。
- 文章链接了相关的论文、代码库和数据集,为用户提供进一步学习的资源。
- 文章强调了社区合作的重要性,并对相关研究人员和贡献者表示感谢。
本地部署踩了一些坑,作者提供的脚本,不一定每个机器都能跑。实测我本地运行的脚本,需要做以下几个修改和准备:
- 使用wsl2环境,或者linux环境。
- 需要修改其中一些代码,例如arg参数的传递和vae参数的初始化问题。
- 还有其他的坑,有空写一篇教程出来。
分享介绍就到这里,有什么疑问或者问题,可以留言交流哦~
关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。