5分钟阅读
很能打!SD3的最新动向

早前我们已经发布过SD3的一些新闻了,外网的大佬们都在紧密的测试中,上周二官方也放出了SD3的相关论文。今天我们来回顾一下SD3的信息和展望一下SD3会带来如何的改变。
SD3的效果
我们先来看看大佬们用SD3出的图。像素风格的,文字理解非常好。

真实电影风格,效果拉满了。





赛博朋克


未来电影风格,我们都知道,无论用MJ还是SDXL,一旦加入科幻元素,图片都会变得模糊起来,而SD3却还原的非常好,像一部真实的科幻电影了。



动漫风格,感觉可以媲美MJ的Niji模型了。




总的来说,因为使用了新的技术架构(跟Openai的Sora架构一样的架构),SD3在图片的生成质量、对文字的理解和还原,以及对提示语的理解能力都大幅提升,相信SD3发布后,对于使用SD进行绘图的设计师们,会更加得心应手,输出的图片质量也会更好,大家不妨再期待一下吧。
SD的论文要点
stablilituy.ai官方在上周二也发布了其SD3论文(看不懂系列..)。原文地址:https://stability.ai/news/stable-diffusion-3-research-paper?utm_source=Twitter&utm_medium=website&utm_campaign=blog。网上很多大佬也已经解读过,我这步再为大家总结几个点:
太长不看,一句话总结:Stable Diffusion 3通过采用多模态扩散变换器(MMDiT)架构、改良的整流流(RF)公式和灵活的文本编码器等先进技术,实现了在文本到图像生成领域的卓越性能和高度的灵活性。
- 性能优越性:在排版、提示遵循和视觉美感方面,Stable Diffusion 3超越了其他领先的文本到图像生成系统,如DALL·E 3、Midjourney v6和Ideogram v1,这是根据人类评估确定的。
- 多模态扩散变换器(MMDiT):SD3引入了一种新的架构,为图像和语言表示使用了不同的权重,增强了生成图像中的文本理解和拼写。
- 性能亮点:在与开源和闭源模型的比较测试中,SD3显示出等同或更优的性能。最大的模型拥有8B参数,可以适配24GB VRAM的RTX 4090,使用50个采样步骤在34秒内生成1024x1024分辨率的图像。将提供不同大小的模型,以适应不同的硬件能力。
- 架构细节:MMDiT架构分别处理文本和图像,但将它们的注意力集成在一起,从而改善了理解和排版。它还在视觉保真度和文本对齐方面超越了UViT和DiT等已建立的文本到图像基础架构。
- 通过重新加权改善整流流:SD3采用了整流流(RF)公式,并引入了一种新的轨迹采样计划,该计划改善了性能,特别是在较少步骤采样制度中。
- 扩展整流流变换器模型:扩展研究显示,验证损失与自动图像对齐指标和人类偏好得分之间存在强相关性,表明有进一步提高性能的潜力。
- 灵活的文本编码器:通过在推理中移除内存密集型的T5文本编码器,SD3可以显著降低内存需求,对视觉美感的影响最小,对文本遵循有一定的减少。
SD3带来的变化
论文中提到的技术,特别是Stable Diffusion 3所采用的多模态扩散变换器(MMDiT)架构、改良的整流流(RF)公式和灵活的文本编码器,可能会对AIGC(人工智能生成内容)行业带来以下几方面的变化和发展:
- 更高质量的生成内容:通过更精确地理解和遵循文本提示,这些技术能够生成更高质量、更符合用户意图的图像,从而提升用户体验和满意度。
- 更广泛的应用场景:改进的文本到图像生成技术将扩大AIGC的应用范围,包括但不限于增强现实、虚拟现实、游戏开发、广告创意、艺术创作等领域。
- 提高模型的可访问性和适应性:通过降低模型的内存需求和提供灵活的编码器配置,这些技术使得更多用户能够在不同的硬件条件下使用高级的图像生成模型,从而降低了技术门槛。
- 推动个性化和创新:随着模型对文本理解和图像生成能力的提升,用户可以更自由地表达创意,生成更加个性化和创新的内容,从而推动内容创作的多样性和创新性。
- 促进技术迭代和竞争:Stable Diffusion 3的突破性进展可能会激发其他AIGC技术和模型的开发和优化,推动整个行业技术的快速迭代和健康竞争。
- 新的伦理和法律挑战:随着生成内容的质量和逼真度的提升,也可能引发关于内容原创性、版权、隐私和伦理等方面的新挑战和讨论。
论文中提到的技术将进一步推动AIGC行业的发展,提升内容生成的质量和效率,同时也可能引起行业对于新挑战的关注和应对。
论文全文
设计小站把论文全文贴出来,大家可以自行研究一下:
Stable Diffusion 3:研究论文
要点:
今天(3月5日),我们发布了研究论文,深入探讨了推动 Stable Diffusion 3 的底层技术。
- 根据人类偏好评估,Stable Diffusion 3 在排版和提示遵循方面优于最先进的文本到图像生成系统,如 DALL·E 3、Midjourney v6 和 Ideogram v1。
- 我们的新多模态扩散变压器 (MMDiT) 架构为图像和语言表征使用了独立的权重集,与 SD3 的早期版本相比,这改善了文本理解和拼写能力。
- 继我们宣布 Stable Diffusion 3 的早期预览后,我们今天发布了研究论文,概述了我们即将发布的模型的技术细节。该论文很快将在 arXiv 上提供,我们邀请您注册候补名单以参与早期预览。

性能
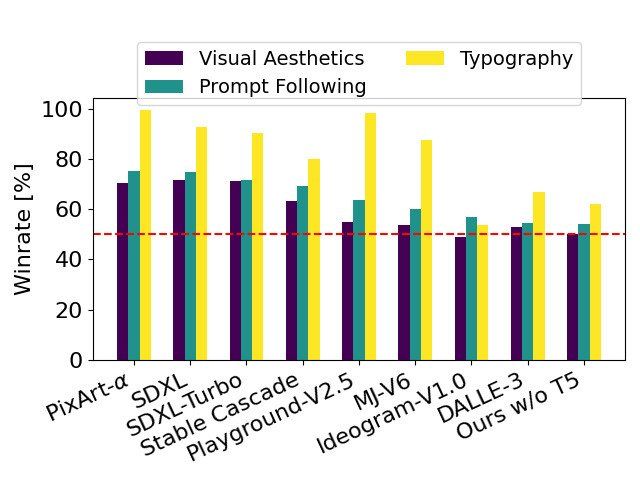
以 SD3 为基线,此图表概述了根据人类对视觉美学、提示遵循和排版的评估,它在与竞争模型的对比中获胜的领域。
我们比较了 Stable Diffusion 3 与其他各种开放模型的输出图像,包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α,以及闭源系统,如 DALL·E 3、Midjourney v6 和 Ideogram v1,以根据人类反馈评估性能。在这些测试中,向人类评估者提供了每个模型的示例输出,并要求他们根据模型输出与给定提示的上下文有多接近 (“提示遵循”)、文本根据提示呈现得有多好 (“排版”)以及哪张图像具有较高的美学质量 (“视觉美学”) 来选择最佳结果。
从我们的测试结果来看,我们发现 Stable Diffusion 3 在上述所有领域都与或优于当前最先进的文本到图像生成系统。
在针对消费级硬件进行的早期、未优化的推理测试中,我们最大的 SD3 模型(具有 8B 参数)适合 RTX 4090 的 24GB VRAM,并且在使用 50 个采样步骤时需要 34 秒来生成分辨率为 1024x1024 的图像。此外,在初始发布期间,将有多种 Stable Diffusion 3 变体,从 800m 到 8B 参数模型,以进一步消除硬件障碍。

架构细节
对于文本到图像生成,我们的模型必须考虑文本和图像这两种模态。这就是为什么我们称这个新架构为 MMDiT,这是指它处理多种模态的能力。与 Stable Diffusion 的早期版本一样,我们使用预训练模型来推导出合适的文本和图像表征。具体来说,我们使用三个不同的文本嵌入器——两个 CLIP 模型和 T5——来编码文本表征,并使用改进的自动编码模型来编码图像标记。
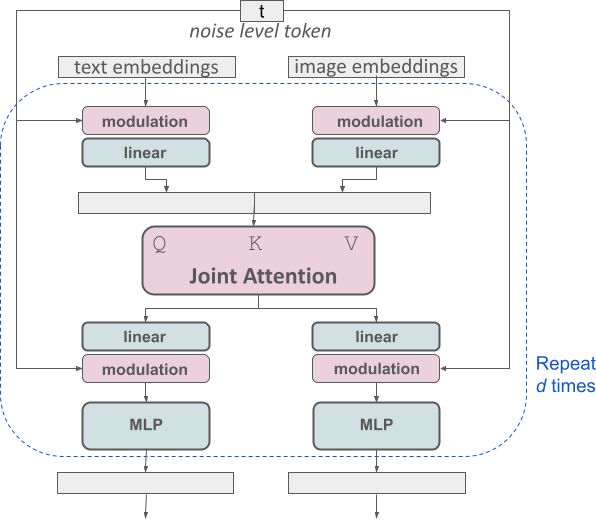
我们修改的多模态扩散变压器块的概念可视化:MMDiT。
SD3 架构建立在扩散变压器 (“DiT”,Peebles & Xie,2023) 的基础上。由于文本和图像嵌入在概念上非常不同,我们为这两种模态使用了两个独立的权重集。如上图所示,这相当于为每种模态都有两个独立的变压器,但连接两种模态的序列进行注意力操作,以便两种表征都可以在自己的空间中工作,同时考虑到对方。
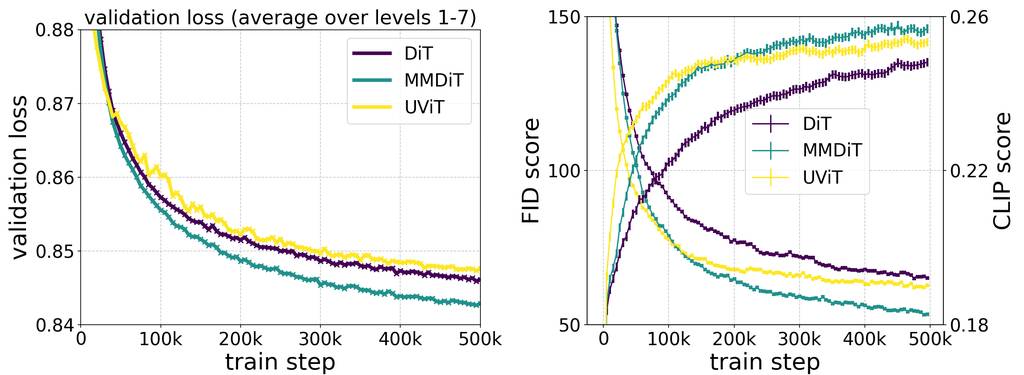
当在训练过程中测量视觉保真度和文本对齐度时,我们的新颖 MMDiT 架构优于已建立的文本到图像骨干,如 UViT (Hoogeboom et al, 2023) 和 DiT (Peebles & Xie, 2023)。
通过使用这种方法,允许信息在图像和文本标记之间流动,以提高生成输出中的整体理解和排版。正如我们在论文中所讨论的,此架构也易于扩展到多种模态,例如视频。

得益于 Stable Diffusion 3 改进的提示遵循,我们的模型能够创建专注于各种不同主题和质量的图像,同时在图像本身的风格方面也保持高度灵活性。

通过重新加权改进整流流
Stable Diffusion 3 采用了整流流 (RF) 公式(Liu et al., 2022; Albergo & Vanden-Eijnden,2022; Lipman et al., 2023),其中数据和噪声在训练期间在一条线性轨迹上连接。这导致了更直接的推理路径,然后允许使用更少的步骤进行采样。此外,我们在训练过程中引入了一个新的轨迹采样时间表。该时间表对轨迹的中间部分赋予了更大的权重,因为我们假设这些部分会导致更具挑战性的预测任务。我们使用多个数据集、指标和采样器设置针对 60 个其他扩散轨迹(例如 LDM、EDM 和 ADM)测试了我们的方法以进行比较。结果表明,虽然以前的 RF 公式在少数步骤采样方案中显示出改进的性能,但它们在更多步骤中的相对性能会下降。相比之下,我们的重新加权 RF 变体始终提高性能。
扩展整流流变压器模型
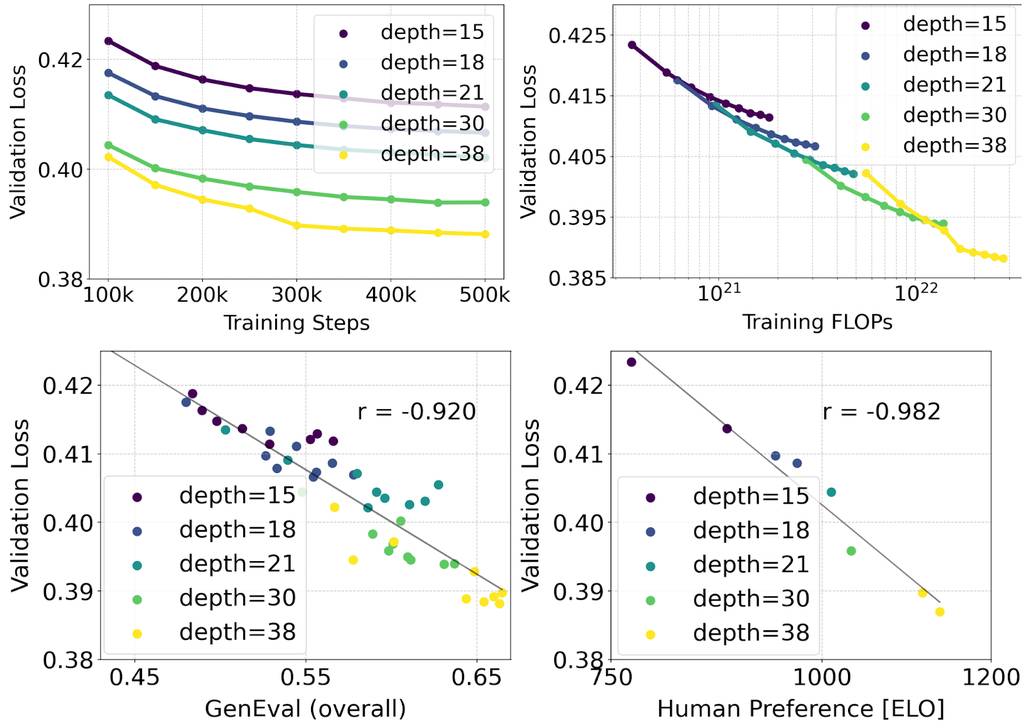
我们针对文本到图像合成进行了扩展研究,采用了我们的重新加权整流流公式和 MMDiT 骨干。我们训练了从 15 个块(具有 4.5 亿个参数)到 38 个块(具有 8B 个参数)的模型,并观察到验证损失随着模型大小和训练步骤平稳下降(顶行)。为了测试这是否转化为模型输出的实质性改进,我们还评估了自动图像对齐指标 (GenEval) 和人类偏好得分 (ELO)(底行)。我们的结果表明这些指标与验证损失之间存在很强的相关性,表明后者是整体模型性能的强有力预测指标。此外,扩展趋势没有饱和的迹象,这让我们乐观地认为我们未来可以继续提高我们模型的性能。
灵活的文本编码器

通过在推理中移除占用大量内存的 4.7B 参数 T5 文本编码器,SD3 的内存需求可以显着降低,而性能损失很小。移除此文本编码器不会影响视觉美学(不使用 T5 的获胜率:50%),并且只会导致文本遵循度略有降低(获胜率 46%),如“性能”部分下的上图所示。然而,我们建议包括 T5 以使用 SD3 在生成书面文本中的全部功能,因为我们发现没有它在排版生成中观察到更大的性能下降(获胜率 38%),如下面的示例所示:
仅在推理中移除 T5 仅在呈现涉及许多细节或大量书面文本的非常复杂的提示时才会导致显着的性能下降。上图显示了每个示例的三个随机样本。
要了解更多有关 MMDiT、整流流和 Stable Diffusion 3 背后的研究,请在此处阅读我们的完整研究论文。
关注我们的 Twitter、Instagram、LinkedIn,加入我们的 Discord 社区,了解我们的进展。
原文完
关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。