5分钟阅读
性价比很高的开源AI换衣方案?服装电商福音
前言
AI换衣已经不是新鲜话题了,很久设计小站也专门做过一期:# 【AI辅助设计】一键换装且高清出图&送红包封面。经过几个月的进化,最新的技术又来了,名字叫CatVTON。与OOTD和IDM相比,CatVTON允许你选择服装类型,然后将其替换为不同类型的服装,例如,模特穿着一件白色T恤,通过选择夹克作为服装类型,你可以将夹克替换到模特身上。
CatVTON介绍
该项目是由美图、中山大学、鹏城实验室共同完成,论文地址:http://arxiv.org/abs/2407.15886
基于简单拼接的虚拟试衣扩散模型 - 优化版本
CatVTON 提出了一种简单高效的虚拟试衣扩散模型,通过在空间维度上简单地拼接服装和人物图像来实现不同类别服装的虚拟试穿。该方法有效地降低了模型复杂度和计算成本,同时保持了高质量的虚拟试衣效果。

优势:
- 轻量级网络: 仅使用原始的扩散模块,无需额外的网络模块,参数量减少了 167.02M。
- 参数高效训练: 只训练与试衣相关的模块,参数量仅为骨干网络的 5.51%(49.57M)。
- 简化推理: 无需姿态估计、人体解析和文本输入等预处理步骤,只需提供服装参考图、目标人物图像和掩码。
- 优异性能: CatVTON 在定性和定量评估中均取得了优异的结果,并且在仅使用 73K 样本的开源数据集上表现出良好的泛化能力。
核心思想:

CatVTON 通过空间拼接将服装和人物图像融合,简化了虚拟试衣过程,并显著降低了模型的复杂度和计算成本。
模型结构:
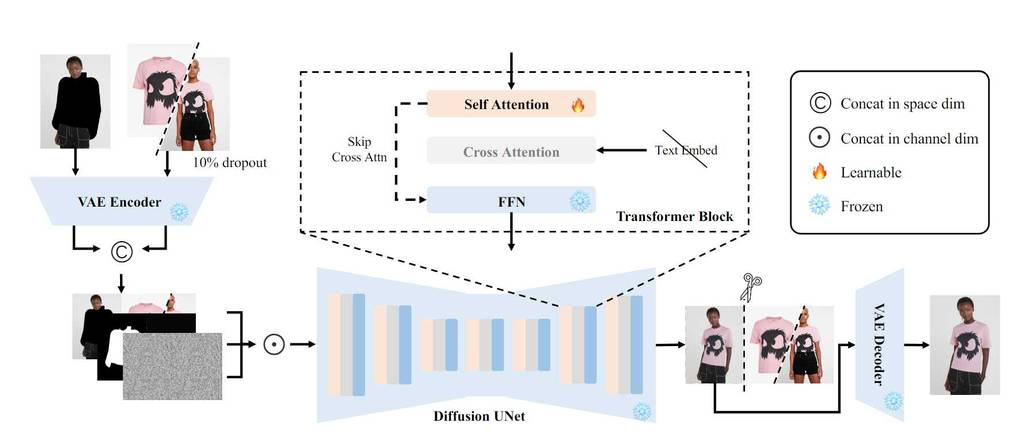
CatVTON 的核心结构包含三个部分:
- 图像预处理: 将服装图像和人物图像进行裁剪和缩放,并根据人物图像的掩码生成服装图像的掩码。
- 空间拼接: 将服装图像和人物图像根据掩码进行拼接,生成一个包含服装和人物信息的融合图像。
- 扩散模型: 利用预训练的扩散模型对融合图像进行解码,生成最终的虚拟试衣结果。
优化策略:
- 损失函数: CatVTON 使用 L1 损失函数来优化模型,并使用对抗损失来提高模型的生成质量。
- 数据增强: 在训练过程中使用数据增强技术,例如随机裁剪、颜色抖动和图像翻转,来提高模型的鲁棒性。
ComfyUI工作流
官方的github源码已经包含了ComfyUI工作流了,非常贴心 ❤️。但是,我这里用了另一位开发者的插件和工作流,地址:https://github.com/pzc163/Comfyui-CatVTON。
插件安装
安装这个插件其实还是有点复杂的,建议用wsl2环境进行安装,会顺畅很多。其中难搞的部分就是安装:Detectron2 和 DensePose,对了,cuda必须是12.1以上。
在wls2环境中,直接两条命令就可以装起来了。
pip install git+https://github.com/facebookresearch/[email protected]
pip install git+https://github.com/facebookresearch/[email protected]#subdirectory=projects/DensePose
其他的依赖可以通过正常的安装依赖方式安装即可。
pip install -r requirements.txt
这里如果已经成功安装了DensePose,就需要吧requirments.txt里面 这行注释掉。
# DensePose==0.6 git+https://github.com/facebookresearch/[email protected]#subdirectory=projects/DensePose
安装好后,拖入作者提供的工作流,就可以玩耍了🐸。
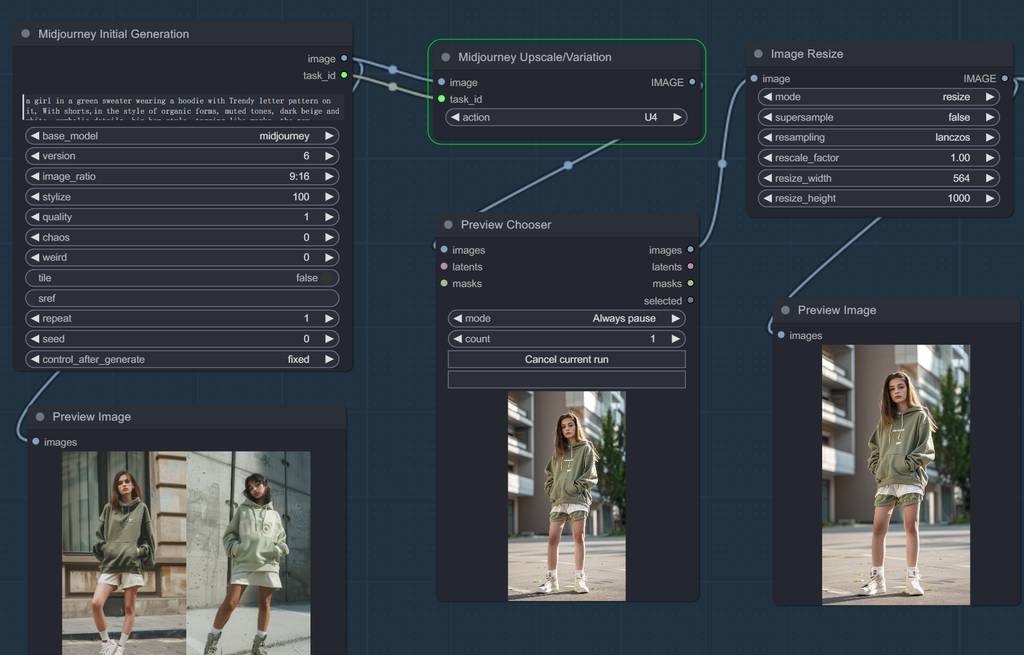
跟Midjourney结合
ComfyUI的强大之处,在于可以把各种优质技术和资源串联起来。我这里就用了自己做的Midjourney插件,利用mj给我生成高质量模特图片,再把衣服“穿上去”,这样模特素材也不用导出找了。关于该插件,请看我上期文章:# 【AI辅助设计】强强联手!我把Midjourney接入了ComfyUI
Midjourney模块
CatVTON模块
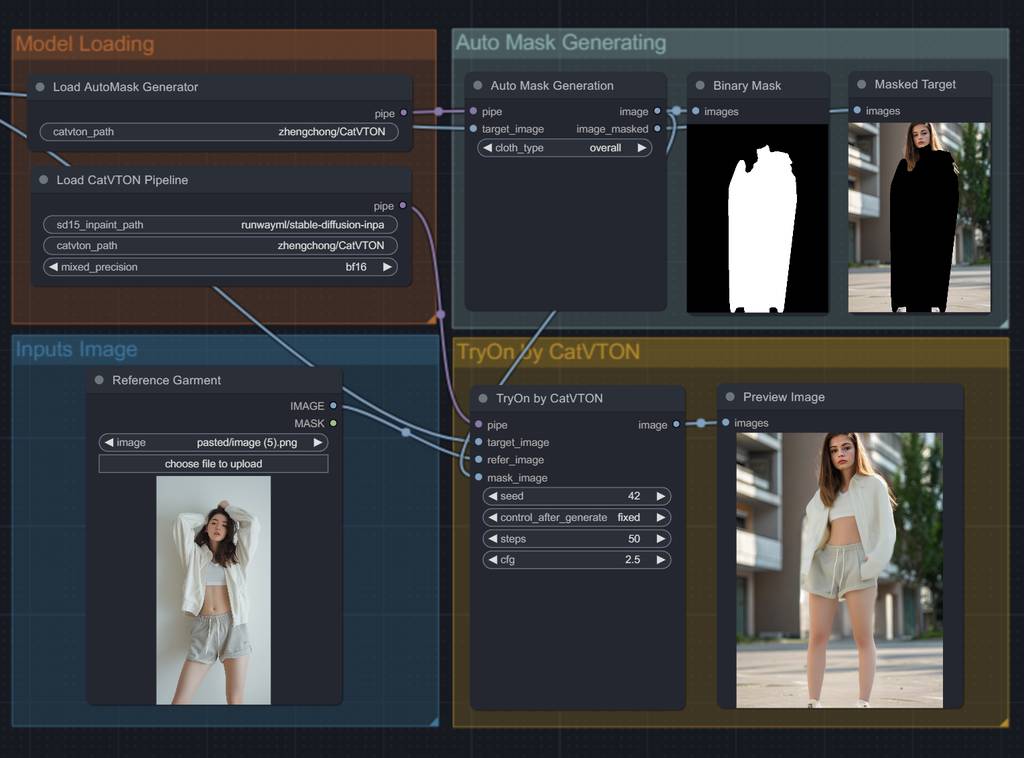
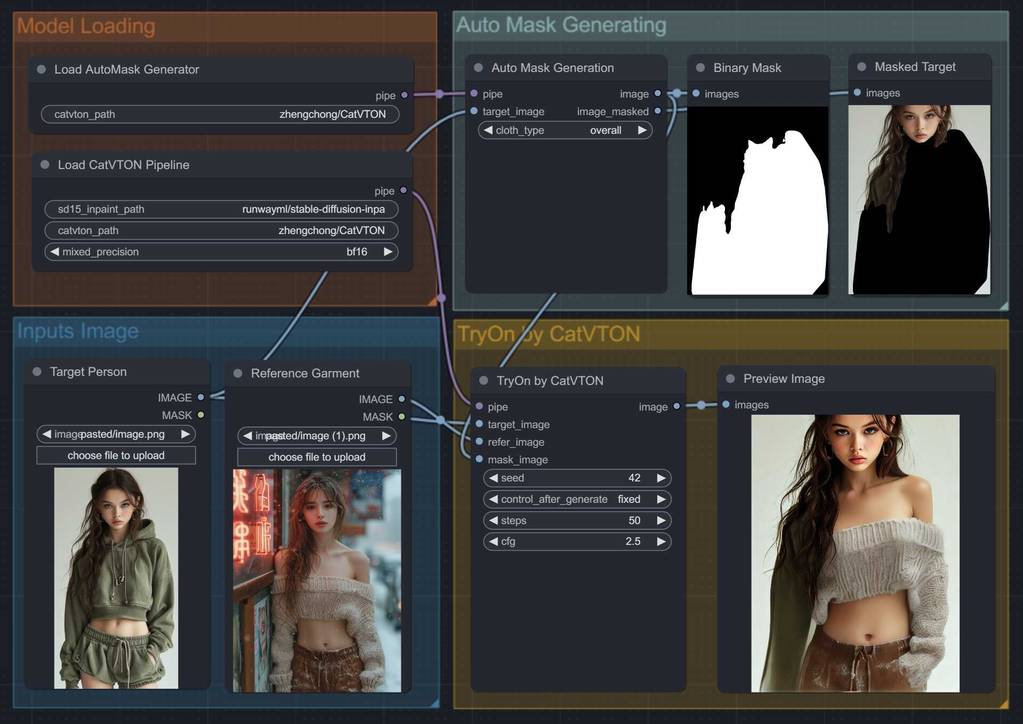
选图
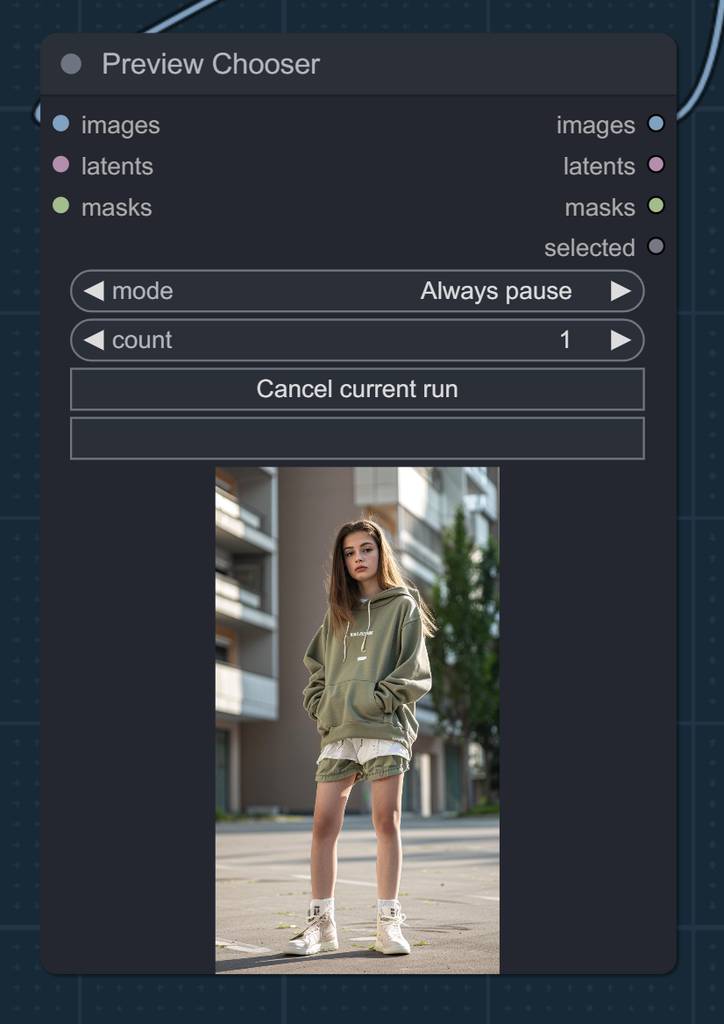
最后看看效果

为了省事和对比,以下就固定模特了~






总结
总得来说,这套方案性价比还是挺高的,但是也存在抽卡情况,然后毕竟是基于SD1.5的底模,图片尺寸不会太大,作为快速看效果,还是可以的。电商服装的设计师或老板,可以试试~💪⛽️。
今天的介绍就到这里,有什么疑问或者问题,可以留言交流哦~ 关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。