5分钟阅读
更适合艺术家或艺术家用的模型?Playground v25模型发布

设计小站观点:在当前AI领域的激烈竞争中,新技术和创新思维不断涌现,成为这个领域的标志性特征。AI创业者面临的挑战是如何在众多竞争者中脱颖而出,这需要他们进行深入的思考。专注于特定细分市场或领域可能是一种策略。例如,Playground通过从艺术家的视角出发,对文生图模型进行深入研究和训练,并采用非传统的数据呈现方式来展示其成果,这种方法展现了其独特的风格和创新的思路。
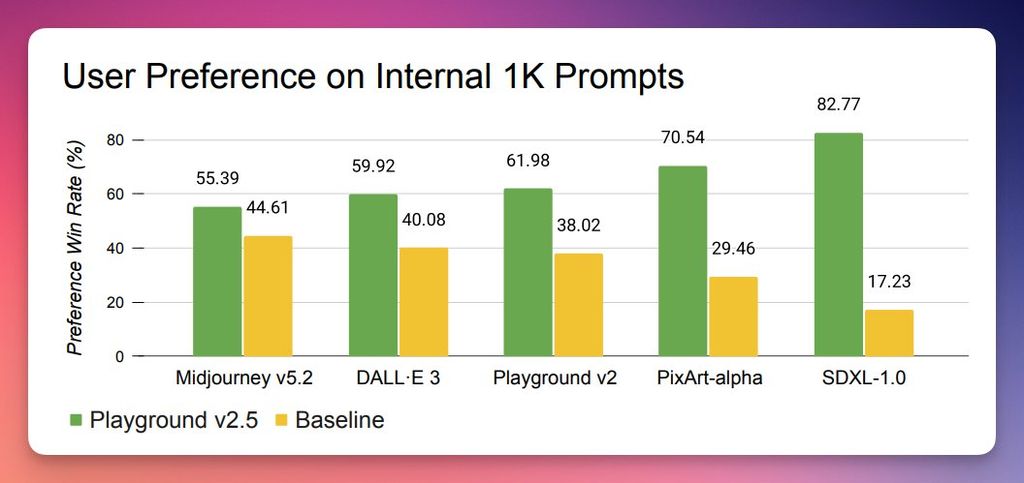
Playground 模型是基于SD训练的文生图模型,其主要特点是经过风格和艺术化处理,官方权威发布:根据20,000 名用户研究反馈,v2.5版本在性能上实现了对SDXL、PixArt-α、DALL·E 3以及Midjourney v5.2的全面超越! 此次升级大幅提高了图像的美学效果,特别是在颜色饱和度和对比度方面进行了深度优化,同时改善了多比例图像的生成能力,使得人像细节更加栩栩如生。
Playground v2.5的显著优势:
- 卓越的图像美学:针对潜在扩散模型在生成鲜艳色彩和对比度上的难题,v2.5采用了Karras等人提出的EDM框架进行全新训练,大幅提升了图像的视觉吸引力和艺术品质。
- 多比例图像生成的突破:v2.5版本针对多比例图像生成进行了深度优化,使模型能够灵活应对不同尺寸的图像需求,更好地适应多样化的实际应用场景。
- 人像细节的精细化处理:为解决生成图像中人物特征(如手、脸、身体)的常见错误,v2.5采用了创新的对齐技术,大幅减少了视觉瑕疵,显著提升了人像品质。专注于优化人脸细节、眼睛形状与神态、头发纹理,以及整体的光照效果、色彩饱和度和景深,力求为人像图像带来更为逼真的视觉效果。
美学显著提升
Playground v2.5 在色彩与对比度、多方面宽高比以及美学方面进行了显著提升,力求在不对社区构建工具所依赖的模型架构进行调整的前提下,尽可能提高图像质量。

测试严格
这些模型进行了严格的基准测试,并与实际用户进行了对比,结果显示这些模型超越了多项现有最先进的技术。

模型已经开放
链接:https://huggingface.co/playgroundai/playground-v2.5-1024px-aesthetic 我们迫不及待想看到社区将创造出什么样的作品和成果。

其他更新
此外,在其官网上的官方web应用,还更新了以下内容:
实时预览
写提示词的时候可以实时看到图像预览,调整提示词。估计用了SDXL turbo或者技术,让生成速度更快。相关知识:# 【AI辅助设计】就在刚刚!字节发布SDXL-lightning!没有最快只有更快!
提示词扩展功能
帮你自动修正和完善你的提示词,你只需要输入简单要求即可。这个功能应该是调用了gpt的大语言模型自动补全提示词功能,这个功能有点像我之前自己搭建的gpt生图工作流呢。# 【AI辅助设计】小孩子才做选择,语言大模型我全都要!

如何使用?
可以通过以下途径使用该模型。
官方
使用 🧨 Diffusers 与模型配合使用
首先,安装不低于0.27.0版本的diffusers及其相关依赖。目前,您需要从GitHub上的diffusers主分支进行安装,直到新的版本在PyPi发布。
pip install git+https://github.com/huggingface/diffusers.git
pip install transformers accelerate safetensors
注意事项:
- 管道默认使用EDMDPMSolverMultistepScheduler调度器,以获得更清晰的细节。这是DPM++ 2M Karras调度器的EDM公式。对于这个调度器,guidance_scale=3.0是一个不错的默认值。
- 管道还支持EDMEulerScheduler调度器。这是Euler调度器的EDM公式。对于这个调度器,guidance_scale=5.0是一个不错的默认值。
然后,运行以下代码片段:
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"playgroundai/playground-v2.5-1024px-aesthetic",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# # 可选:使用DPM++ 2M Karras调度器以获得更清晰的细节
# from diffusers import EDMDPMSolverMultistepScheduler
# pipe.scheduler = EDMDPMSolverMultistepScheduler()
prompt = "宇航员在丛林中,冷色调,柔和的色彩,详细,8k"
image = pipe(prompt=prompt, num_inference_steps=50, guidance_scale=3).images[0]
使用 Automatic1111/ComfyUI 与模型配合使用
支持功能即将推出。准备好后,我们将更新此模型卡片以提供操作指南。
使用webui和comfyui的朋友需要再等等哦~
好了,今天的分享就到这里。 关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。