5分钟阅读
看看两个非主流生图模型

前言
我们都知道,目前主流生图模型就以下几个,包括开源与不开源的:
- 黑森林实验室(Black Forest Labs)Flux. 1家族
- 阿里QWEN-image系列
- Stability AI的SDXL、SD3系列
- gpt-4o-image
- google nano banan
- 字节的seedream4.0 以上是大家公认的“主流”生图模型。除了主流模型外,有些独立开发者或组织,也打造了一些更为专注的不错的模型。今天介绍了两款值得关注的模型。
分别是:
- Stable Diffusion 3.5 Flash。移动设备可用轻量级高质量生图模型
- Chroma1-Radiance 像素直男模型,直出高分辨率开源模型
感兴趣的朋友可以下载试试。
Stable Diffusion 3.5 Flash
ntroducing Stable Diffusion 3.5 Flash , a state of the art distilled image generation model that is best in class for all compute budgets. Project page: https://hmrishavbandy.github.io/sd35flash/ Authors:
,
, Jim Scott, Reshinth Adithyan,
,
We present SD3.5-Flash, a few-step distillation framework that enables high-quality rectified flow generation on consumer hardware. While rectified flow models achieve exceptional quality through extensive multi-step refinement, their computational demands render advanced generative AI largely inaccessible. Our approach addresses fundamental challenges of adapting distribution matching distillation to flow models in few-step regimes, where standard re-noising processes create unstable gradients that systematically degrade quality. We introduce timestep sharing, which computes distribution objectives using intermediate trajectory samples rather than corrupted re-noised versions, providing stable gradients essential for robust few-step training. Our split-timestep fine-tuning technique resolves the capacity-quality tradeoff by temporarily expanding model capacity during training through specialized timestep branches. Combined with comprehensive pipeline optimizations including text encoder restructuring and intelligent quantization, our system generates high-resolution images in under one second while operating within 8GB memory constraints. Through extensive evaluation including large-scale user studies, we demonstrate that SD3.5-Flash consistently outperforms existing few-step methods while maintaining teacher model quality standards, making advanced generative AI truly accessible for practical deployment.

SD3.5-Flash is distilled from SD3.5-Medium using a modified Distribution Matching Distillation that improves both aesthetic quality and prompt-image alignment. When compared head to head with other models in blind user studies, we consistently turn up at the top of the ELO ladder
Performance Comparison
We introduce the SD3.5-Flash suite of models, preferred by users over all other models at a variety of consumer compute budgets while offering comparable latency and memory requirements. Bubble size indicates VRAM occupied and pipeline size on disk for gpus and mobile devices respectively. We compute ELO ratings by assessing generated image quality via human rankings for different models.
Inference Latency
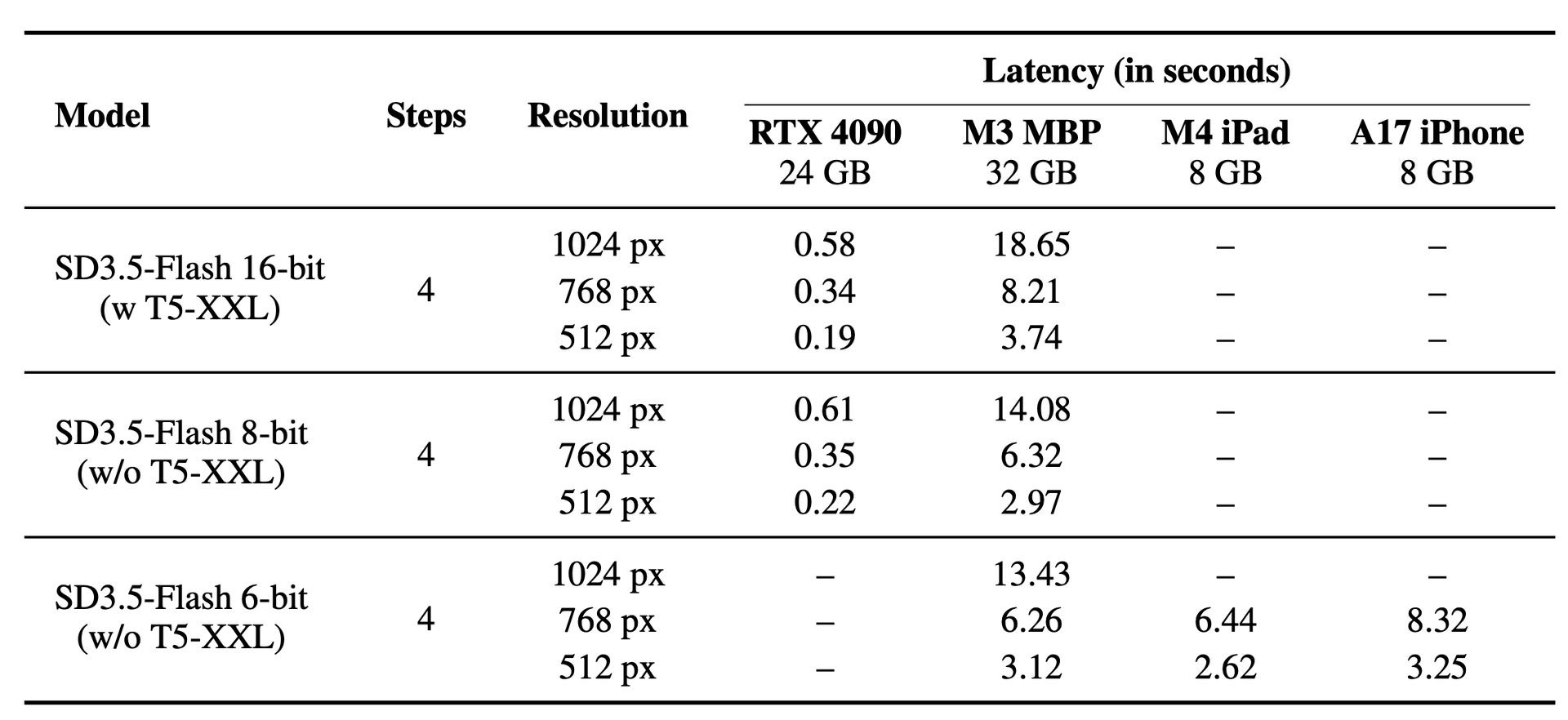
Comparing inference latency of SD3.5-Flash models for different devices with VRAM / unified memory below device names.
With quantization and encoder-dropout pre-training, we can make the model run on an iPhone, generating images in just 3.25 seconds. Here is the real-time screen capture of the model running on an iPhone:
User Studies

Results from user studies (124 annotators, 507 prompts, 4 seeds) comparing SD3.5-Flash models against other state-of-the-art few-step generation methods. Results show consistent preference for SD3.5-Flash across different evaluation criteria.
On-Device Demo
Real time iPhone (A17) demo for 512px image generation. Demonstrates the speed and efficiency of SD3.5-Flash on mobile hardware with live screen recording.
Model is now available via API access: https://platform.stability.ai/docs/api-reference#tag/Generate/paths/1v2beta1stable-image1generate1sd3/post Visit the project page (https://hmrishavbandy.github.io/sd35flash/) for more details such as technical report (https://arxiv.org/abs/2509.21318), summary video (https://youtube.com/watch?v=bFNIg-tqvLw), API Usage etc.
Qualitative Comparisons


Chroma1-Radiance
Chroma1-Radiance is a text-to-image model by the
team. It can generate images directly in pixel space, which means no VAE model is needed and there are fewer visual mistakes.

gonna continue tomorrow for the rest of the impl but GPU POOR rejoice! your CPU RAM is now VRAM. Peak GPU mem: 16,139 → 1,736 MB (on dummy mlp forward pass) Speed ratio: 0.99× (compute & comms perfectly interleaved)
Tinkering with fine-tuning
‘s Chroma Radiance pixel space model today with my musician character. The model is still in early development, but is one of the most exciting things happening in the space right now, in my opinion. No more VAE!
 Chroma1-Radiance update it’s getting good but i think to make the details converge i need to train it for 10x longer but hey atleast we have a true end to end pixel space model
Chroma1-Radiance update it’s getting good but i think to make the details converge i need to train it for 10x longer but hey atleast we have a true end to end pixel space model

在ComfyUI中介绍和使用
Getting started: 1. Update ComfyUI to 0.3.60 2. Download workflow from our blog:
Chroma1-Radiance is a text-to-image model by @LodestoneRock team.
This model is Apache-2.0 licensed, so it is commercially viable.
Normal models use latent space to generate images and VAE to encode/decode images between latent space to/from pixel space. Radiance generates the image directly in pixel space. This means that no VAE model is needed. VAE models estimate what image should look like when decoding, which means there is an inevitable loss. With pixel space generation this is not a thing. Live previews will also be way more accurate as the image is generated.

Prompt: This is a nature documentary close-up photograph of the right side of the face of a tiger. The photograph is centered on it’s highly detailed and speckled eye surrounded by intricately detailed fur. Overlaid at the center of the image is a title text that says “RADIANCE” in a large white 3D letters. Amateur photography. Unfiltered. Real life. Natural light. Subtle shadows.

Prompt: Hyperrealistic macro photograph of a team of tiny bakers—each precisely 2 inches tall—collaborating on an enormous, golden-brown croissant with flaky, layered textures. The bakers are engaged in dynamic, detailed actions: one uses a miniature wooden bucket to spread rich, creamy butter between the croissant’s layers, another climbs a thin rope ladder to evenly pipe smooth, glossy chocolate filling onto the top, and a third brushes a light egg wash with a tiny pastry brush. The scene is bathed in warm, soft kitchen lighting with cinematic depth—subtle highlights on the croissant’s golden crust, gentle shadows that emphasize texture, and a soft glow from overhead pendant lights. Floating flour dust particles catch the light, adding a sense of movement and realism, while tiny details like the bakers’ stitched cloth aprons, smudged flour on their faces, the rough wood of the worktable, and the slight sheen of melted butter on the croissant are rendered with ultra-precision. Ultra-detailed, 8K resolution, photorealistic textures, sharp focus on the bakers and croissant, shallow depth of field to blur the background slightly, rich warm color palette, lifelike proportions, and a cozy, whimsical atmosphere that balances realism with charm.

Prompt: A hyperrealistic, close-up portrait of a young woman with a solemn and direct gaze. She has striking, luminous amber-orange eyes, thick dark eyebrows, and a pale complexion with a prominent dusting of freckles across her nose and cheeks. Her dark brown hair is arranged in an intricate braided updo, with two thick braids falling over her shoulders, all interwoven with shimmering gold and copper-orange fabric and foil. A delicate gold chain with an ornate, dark metal, spearhead-shaped charm rests on her forehead. She is adorned with long, dangling, intricate gold earrings. She wears a high-collared, regal garment of black fabric, heavily embellished with rich gold and orange brocade-style embroidery. The lighting is soft and warm, highlighting the textures of her skin and the intricate details of her attire against a simple, muted grey-blue background.

Prompt: A surreal, high-contrast macro photograph of a small cluster of delicate, slightly withered flowers against a solid black background. Thin, green-brown stems rise from the bottom, presenting blossoms with papery, off-white and brown petals. The most striking feature is the ethereal, rainbow-colored light that emanates from the flowers like gentle flames or an aura. This translucent, iridescent glow is most prominent around the intricate, golden-tipped stamens and contains vibrant hues of purple, blue, green, yellow, and orange, creating a magical and mesmerizing effect.
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。