5分钟阅读
终于!数字人还是活了
最近设计小站又迷上了数字人,原因是发现腾讯的两个开源项目,一个是MuseV,一个是MuseTalk,一个可以让图片动起来,另一个可以让人开口说话。而且,这两个开源项目都有ComfyUI的插件。另外。还有一个项目,就是ComfyUI-GPT_SoVITS,这三者结合起来,在ComfyUI文生图的基础上,就可以做成一个数字人流程了! 说干就干,小编马上安装了这些插件,然后窜了起来,做了一个ComfyUI的工作流。
先看看效果
这是文生图的原图

MuseV效果
可以通过提示词方式,让图片做出各种表情。




完整视频看这里
跑完整个工作流,可以看到可以为图片配音,口型同步。
—视频号链接—
大家是不是觉得这个数字人感觉活了起来一样呢?哈哈😄。 下面教大家工作流的搭建。
技术介绍
再进行之前,还是对几个关键技术简单介绍一下
MuseV
项目地址:https://github.com/TMElyralab/MuseV。
由腾讯团队开发,是基于扩散模型的虚拟人视频生成框架,具有以下特点:
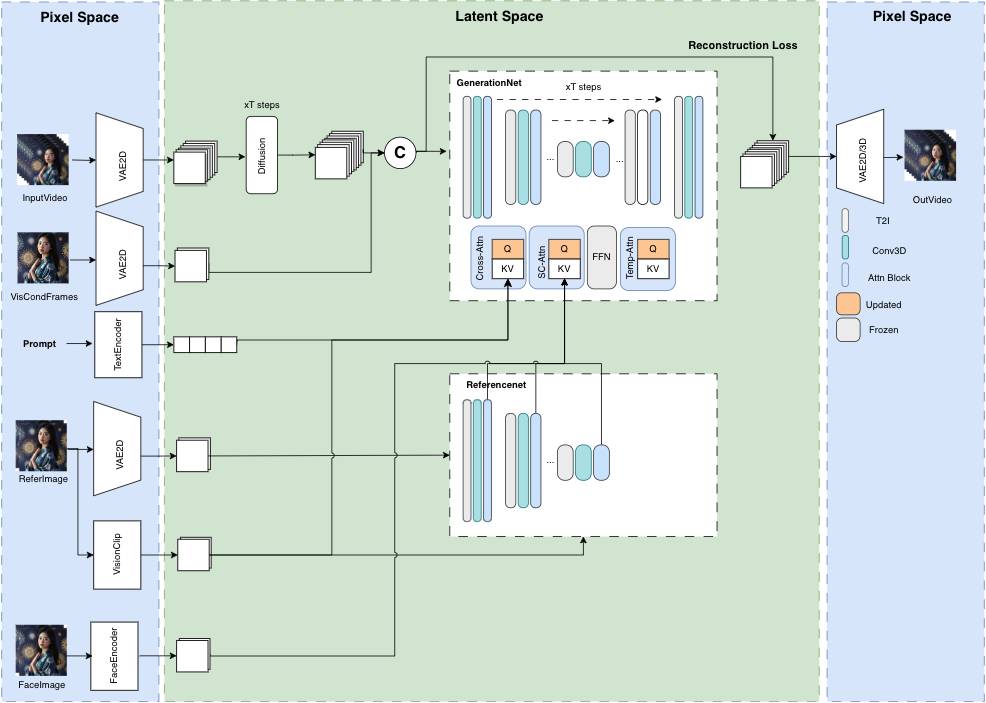
- 支持使用新颖的视觉条件并行去噪方案进行无限长度生成,不会再有误差累计的问题,尤其适用于固定相机位的场景。
- 提供了基于人物类型数据集训练的虚拟人视频生成预训练模型。
- 支持图像到视频、文本到图像到视频、视频到视频的生成。
- 兼容
Stable Diffusion 文图生成生态系统,包括base_model、lora、controlnet等。 - 支持多参考图像技术,包括
IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID。 - 我们后面也会推出训练代码。
并行去噪算法示意图
MuseTalk
项目地址:https://github.com/TMElyralab/MuseTalk
跟MuseV是同一作者,一种实时高质量口型同步模型(在 NVIDIA Tesla V100 上为 30fps+)。 MuseTalk 可以与输入视频一起应用,例如由MuseV生成的视频,作为完整的虚拟人解决方案。
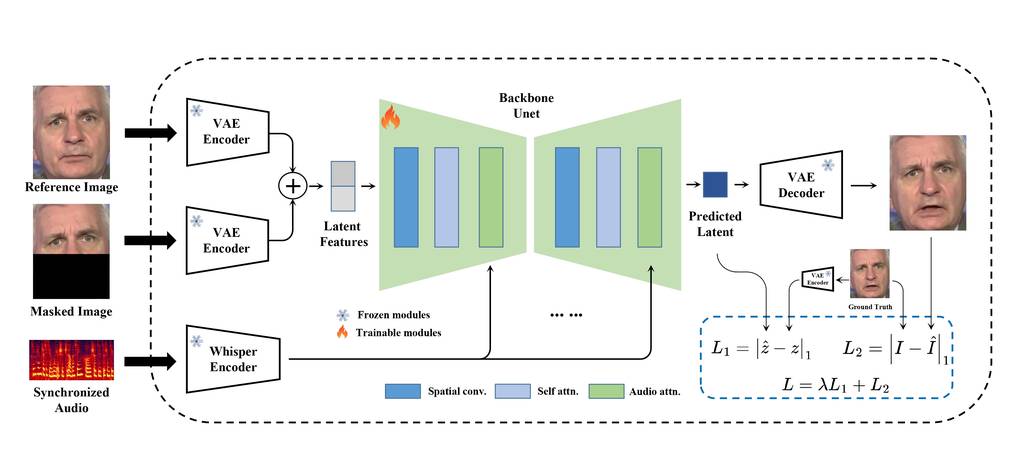
MuseTalk 在潜在空间中进行训练,其中图像由冻结的 VAE 进行编码。音频由冻结whisper-tiny模型编码。生成网络的架构借鉴了UNet stable-diffusion-v1-4,其中音频嵌入通过交叉注意力融合到图像嵌入。
请注意,虽然我们使用与稳定扩散非常相似的架构,但 MuseTalk 的不同之处在于它不是扩散模型。相反,MuseTalk 通过一步修复潜在空间来进行操作。
GPT-SoVITS
项目地址:https://github.com/RVC-Boss/GPT-SoVITS
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
- WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
工作流解释
插件准备
正如上面所说,这里用到了三个插件:
- ComfyUI-MuseV:
https://github.com/chaojie/ComfyUI-MuseV - ComfyUI-MuseTalk:
https://github.com/chaojie/ComfyUI-MuseTalk - ComfyUI-GPT_SoVITS:
https://github.com/AIFSH/ComfyUI-GPT_SoVITS
工作流步骤
文生图模块
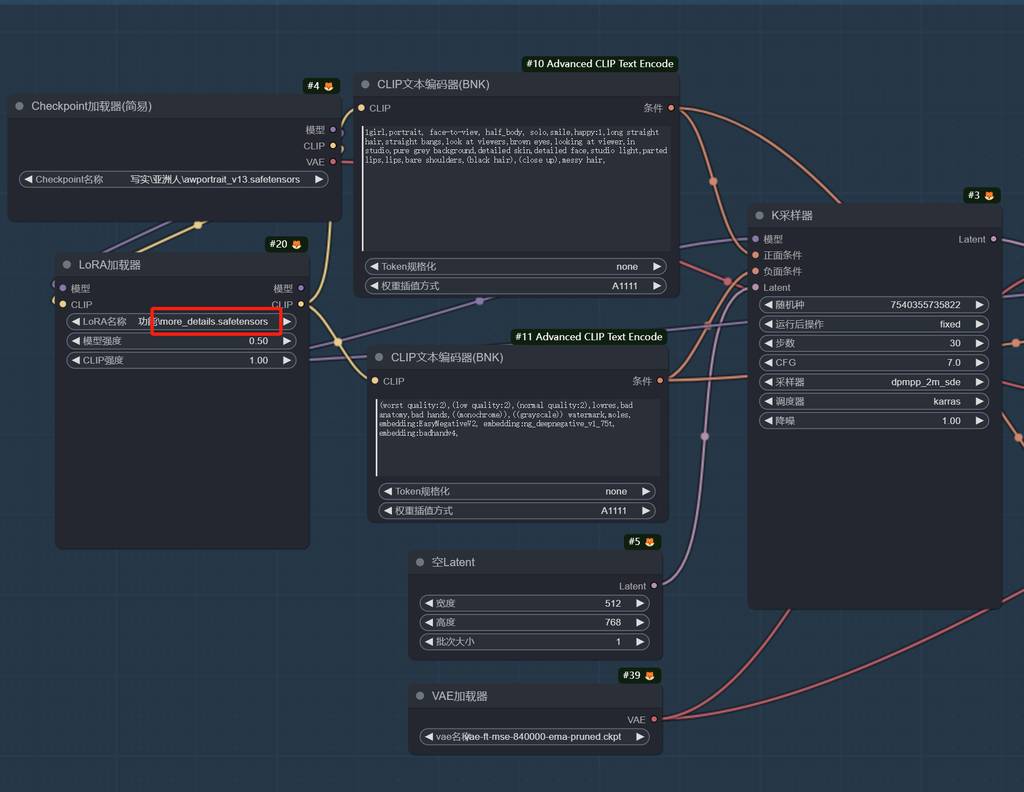
为了获得更好的人物肖像,我用到了DynamicWang大佬训练的AWPortrait模型。
这个模型对中国人的表现会比较到位,符合国人审美。为了增加点细节,还加了detail类型的LoRA。
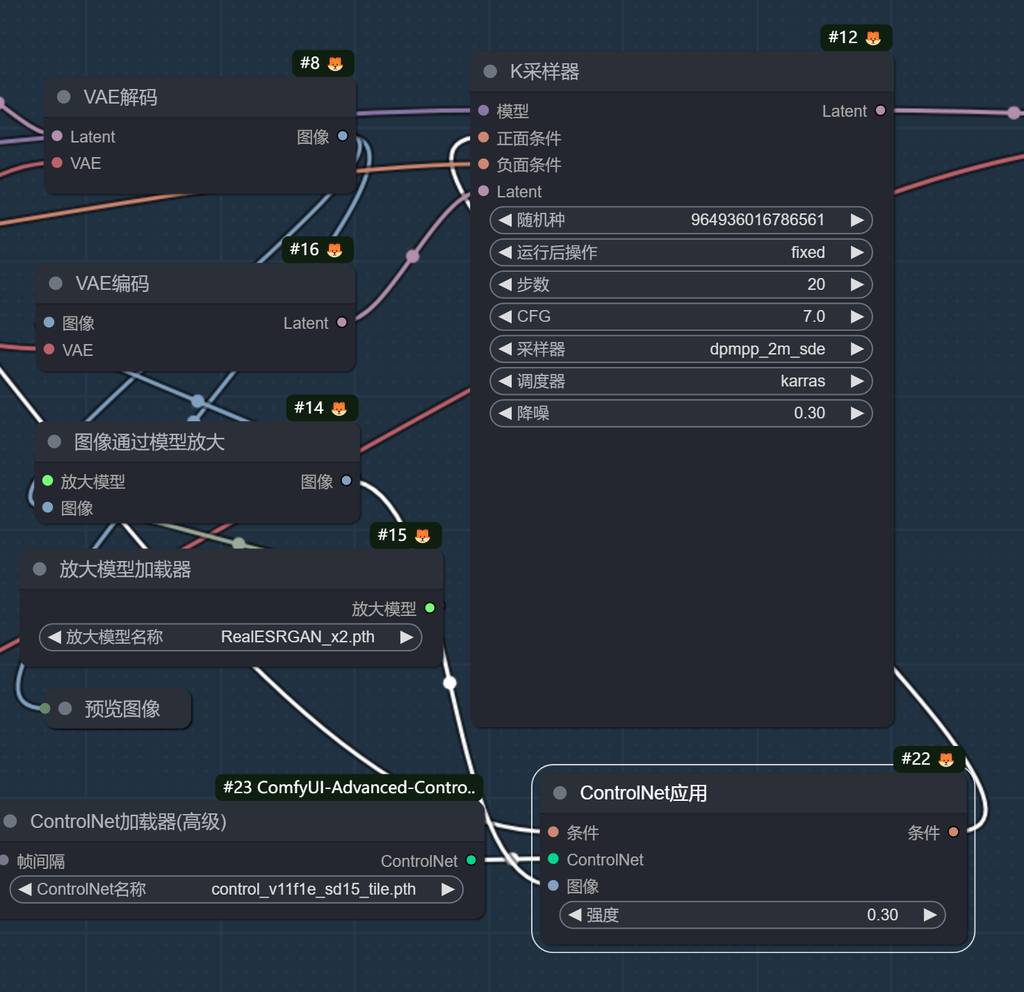
放大,为了获得更丰富的细节,加入了tile的controlnet模型,然后进行第二采样处理。
正向提示词:
1girl,portrait, face-to-view, half_body, solo,smile,happy:1,long straight hair,straight bangs,look at viewers,brown eyes,looking at viewer,in studio,pure grey background,detailed skin,detailed face,studio light,parted lips,lips,bare shoulders,(black hair),(close up),messy hair,
负向提示词:
(worst quality:2),(low quality:2),(normal quality:2),lowres,bad anatomy,bad hands,((monochrome)),((grayscale)) watermark,moles,
embedding:EasyNegativeV2, embedding:ng_deepnegative_v1_75t, embedding:badhandv4,
生成动态视频
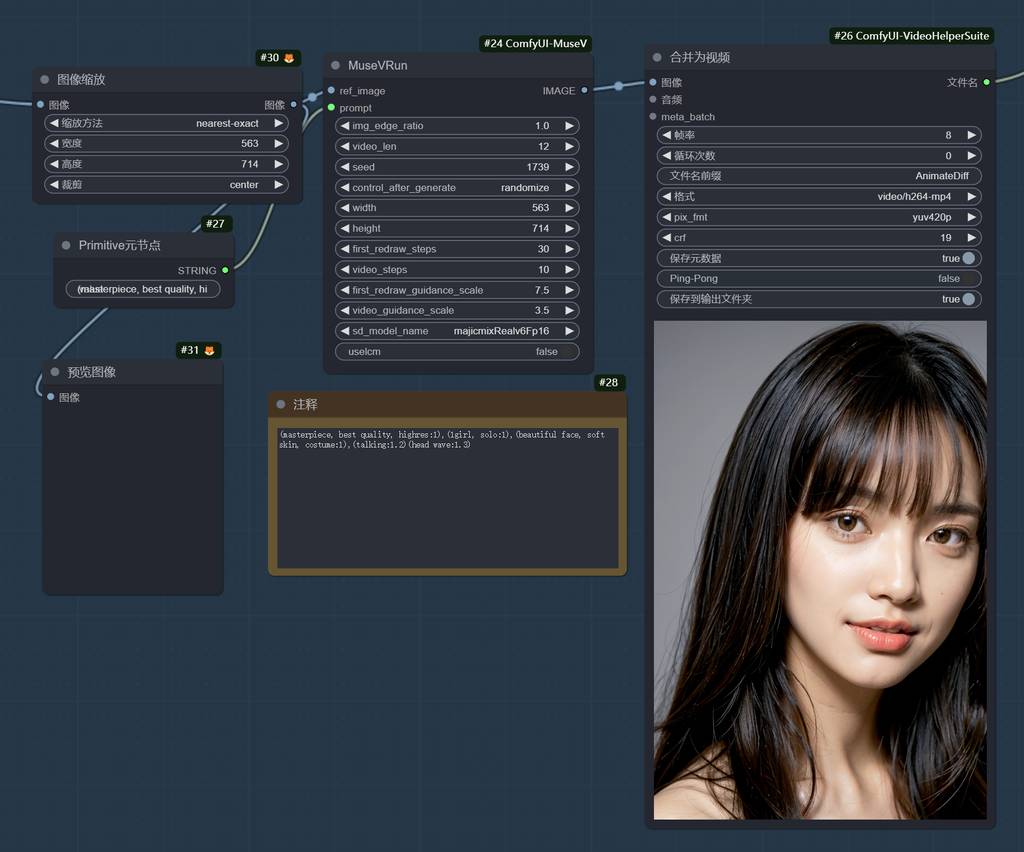
直接用了节点作者提供的工作流,大家看看。注意,这里要对图片进行缩放,不然出的视频比例跟预想的会不一致,当然,你也可以改MuseV的默认尺寸,但建议还是用默认的更好。
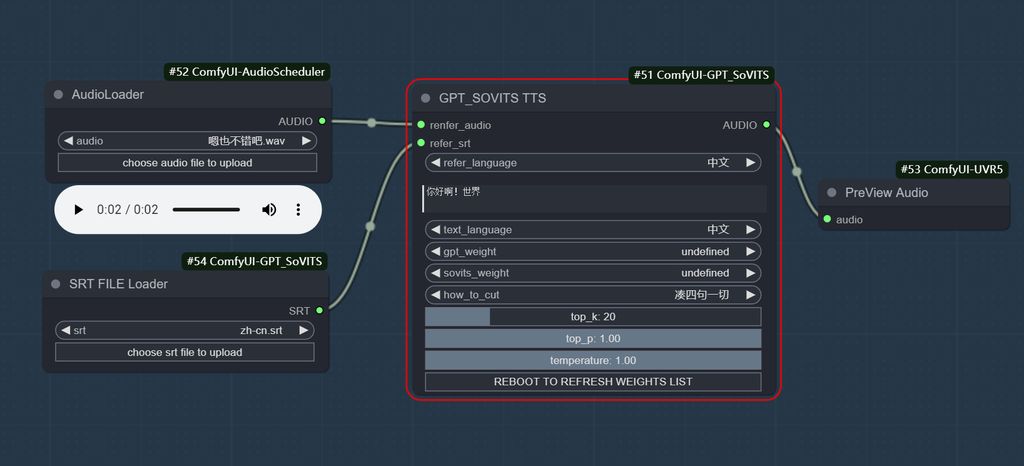
语音生成节点
这里参考语音是使用微软的Azure的最新xiaoxiao合成,作为参考,传入到,SoVITS中,然后输出的语音保存到指定路径。
口型同步
最后就是口型同步,Audio载入之前生成的语音路径,即可传入进行口型同步了,工作流是官方的,这里就不做更多解释了。
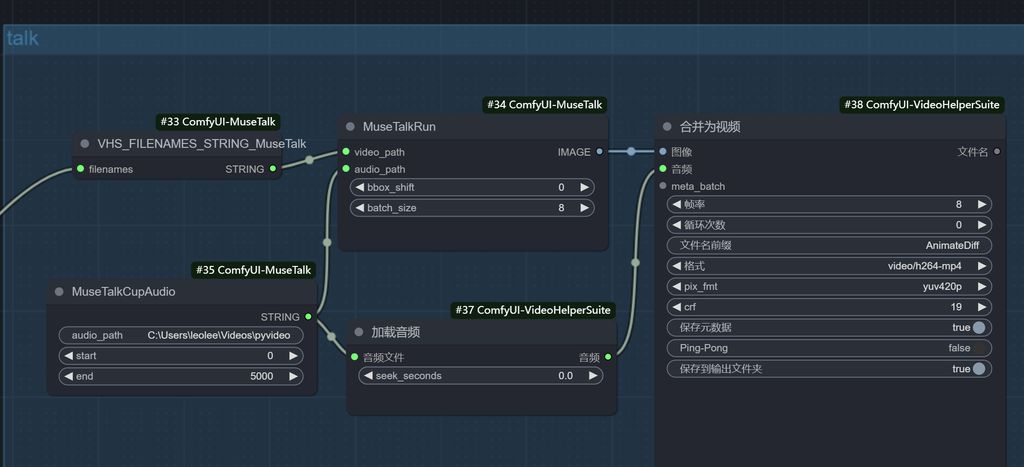
最后提醒一下大家哦,这个工作流对显存要求非常、非常、非常高!4090都卡得动不了,希望官方再优化吧,可以一流程过!
好了,关于的分享介绍就到这里,有什么疑问或者问题,可以留言交流哦~
关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。