5分钟阅读
聊一下Sora的设计应用场景以及争议点

最近陪家人外出旅游了两天,度过了一段美妙的时光。然而,当我回来后,我被人工智能的发展所震撼,仿佛进入了一个全新的世界。在这短短的时间里,涌现出了几个令人瞠目结舌的重磅消息,让我感到自己仿佛置身于时代的浪潮之中,无法跟随其变化。这种错觉让我不禁反思,人工智能的进步速度已经超出了我的想象,我需要更加努力地跟上时代的步伐。
- OpenAI发布了视频生成模型Sora,可生成高质量的1分钟长视频,支持从图像和文本生成视频,并具有扩展和编辑功能。
- 谷歌发布了Gemini 1.5 Pro和Ultra 1.0语言模型,具备长达100万字的上下文理解能力,并推出了Gemini Advanced付费会员计划。
- Stability AI发布了基于扩散模型的图片生成模型Stable Cascade,支持图像变化和生成。 其中尤其以Openai的Sora文生视频模型最为震惊业界。
Sora强在哪里
给大家复盘一下Sora到底强在哪里,博主Poonam Soni 对Sora和Runway Gen2进行了对比。
Prompt: two dogs playing with snow

Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick.

Prompt: An instructional cooking session for homemade gnocchi hosted by a grandmother social media influencer set in a rustic Tuscan country kitchen with cinematic lighting

Prompt: A futuristic drone race at sunset on the planet Mars

Prompt: A young man at his 20s is sitting on a piece of cloud in the sky, reading a book.

Prompt: Photorealistic closeup video of two pirate ships battling each other as they sail inside a cup of coffee.

可以直观感受到,Sora相对Runway Gen2已经拉开了一个身位。视频生成领域的当红炸子鸡Runway Gen2只能望其项背,Sora才能算得上真正意义上的视频,而Runway Gen2只能是“会动的图片而已”。 Sora的强,在于:
- 对物理世界的理解。场景的物体关系,穿插效果接近物理世界
- 视频的变化幅度。能理解输入的语义,输出符合意图的视频。
- 视频时长。时长60秒,且保持一致性。
- 视频画面的比例。可以输出各种视频比例。
Sora影响哪些行业
大佬们对Sora的判断,大多集中在视频,如短视频、电影制作行业,甚至有人说替代好莱坞模式。但是个人认为,谈替代还是言之尚早,反而作为一个设计师们的提效工具,在当下确实有实际意义的。 以下是我觉得设计师们必须关注的Sora应用点:
- 视频生成3D
- 创意包装
视频生成3D
对于游戏概念设计或者建筑设计行业又或者产品设计师们,可以利用Sora的强大的能力,生成建筑的360环视图,再利用高斯溅射,生成三维模型。关于高斯溅射,可以见《 【AI辅助设计】本地部署一套高斯溅射生成流程》
X 上的博主,jin就尝试了这个创作流程。
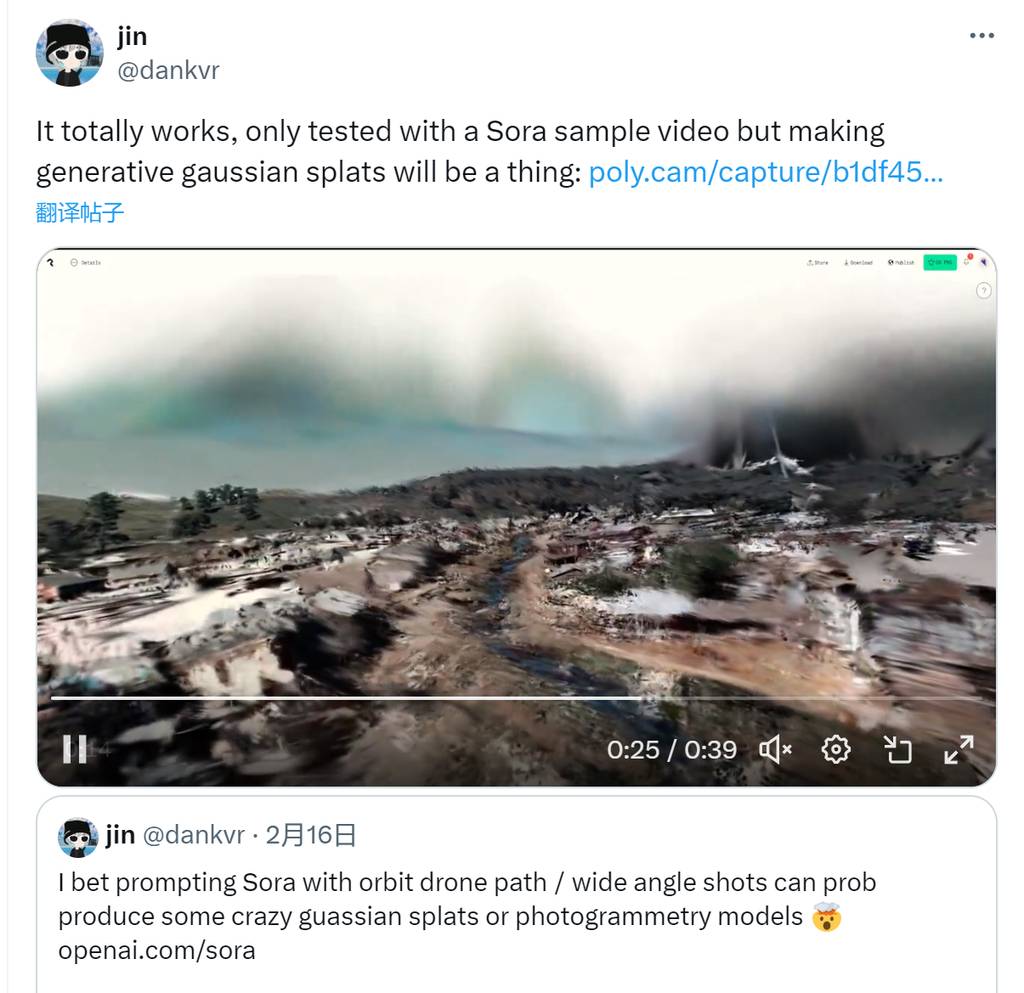
他找到一个Sora生成的场景视频
 然后通过在线生成高斯溅射模型的平台polycam和luma,把视频上传后生成模型。
polycam生成效果
然后通过在线生成高斯溅射模型的平台polycam和luma,把视频上传后生成模型。
polycam生成效果

luma生成效果,质量比polycam好不少。

创意包装
创意包装既包括设计师对创意的表达,也包括面向甲方进行创意包装的实际项目。我们都知道,一个好的视频对于表现优秀创意至关重要,因为人类是视觉驱动的。
让我们想象一下未来的场景:设计师完成了一个设计,输入一段文字,然后就能生成相应设计的视频。这无疑会极大地增强创意的表达和传播效果,同时节省大量的人力和物力资源。
之前我提到的设计师Sergiy Dvornytskyy,他在《设计师Sergiy Dvornytskyy作品欣赏》中展示了他出色的创意表达。为了实现这样的创意,他使用了UE(虚幻引擎)和AE(Adobe After Effects)等软件。然而,未来,您也可以通过类似的方式创作视频,而无需学习复杂的软件。


然而,我们也要注意,在这个过程中,设计师的专业知识和审美判断仍然是不可或缺的。技术工具只是辅助手段,真正优秀的创意仍然需要设计师的独特思维和艺术触觉来实现。
因此,未来的创意包装将是技术与人类创造力的完美结合。通过利用先进的技术工具,设计师们可以更好地表达他们的创意,并将其传达给观众和客户。这将为创意产业带来新的发展机遇,并推动创意包装的创新和进步。
关于Sora的争议点
Sora一经发布,网络上便开始流传一系列引人注目的标题,如”真实的世界不存在了”、“我们都是虚拟的…”等。然而,我认为这些标题不过是自媒体为了吸引眼球而采取的手段而已。目前来看,Sora并没有真正实现物理模拟的意义。从其原理来看,它与现有的人工智能模型类似,都是通过统计方法推导出视频生成的。
针对这个问题,社区中的一些专家进行了讨论,并摘录了其中的一些观点,我将它们分享给大家,并希望大家能以理性的态度来看待Sora。
这些讨论中,专家们指出了Sora目前的局限性和不足之处。尽管Sora在视频生成方面取得了一定的成果,但它仍然依赖于大量的统计数据和算法推导,无法真正模拟出完全准确的物理现象。此外,Sora也无法进行因果推理和假设,与科学推理的过程有着根本性的不同。
因此,我们应该对Sora持有理性的态度。虽然Sora在某些方面展示了潜力,但我们不能过分夸大其能力,并将其视为完全代替真实世界的虚拟构造。我们需要保持清醒的头脑,认识到Sora目前仍处于发展的初级阶段,并且在应用和技术上还存在许多挑战和限制。
Nvdia科学家Jim Fan认为Sora 是一个数据驱动的物理引擎。
 Jim Fan:
Jim Fan:
如果你认为OpenAI Sora就像DALLE一样是一个创意玩具,那么请重新考虑。Sora是一个数据驱动的物理引擎,它是许多真实或幻想世界的模拟。该模拟器通过一些去噪和梯度数学来学习复杂的渲染、“直观”的物理、长期推理和语义基础。
如果Sora是使用Unreal Engine 5在大量合成数据上进行训练的,我不会感到惊讶。它一定是这样!
让我们分解一下以下视频。提示:“在一杯咖啡中,两艘海盗船激烈对战的逼真特写视频。”
- 模拟器实例化了两个精美的3D资源:装饰不同的海盗船。Sora必须在其潜在空间中隐式解决文本到3D的问题。
- 这些3D物体在航行过程中始终保持动画,并避免彼此的路径。
- 咖啡的流体动力学,甚至是围绕船只形成的泡沫。流体模拟是计算机图形学的一个完整子领域,传统上需要非常复杂的算法和方程。
- 几乎像光线追踪一样逼真的渲染。
- 模拟器考虑到杯子相对于海洋的小尺寸,并应用倾斜移轴摄影来给人一种”微小”的感觉。
- 场景的语义在现实世界中并不存在,但引擎仍然实现了我们所期望的正确物理规则。
接下来:增加更多的模态和条件,然后我们将拥有一个完整的数据驱动的UE,可以取代所有手工设计的图形流水线。
对此,Geometric Intelligence CEO Gary Marcus发出质疑。 Gary Marcus:
嗯,什么样的物理引擎会在场景中产生不一致的视图(除了棘手的遮挡等)?标准做法是表示一个三维空间,然后从一个视点渲染它。这显然是不同的。
@jbaert说得对。这严重削弱了来自@DrJimFan和OpenAI的将Sora视为传统物理模拟器的论点。
你为什么会相信第二种说法?从所有的错误和同时的多功能性来看,我确定是第一种情况。
不对。它输出像ChatGPT输出单词序列一样的像素集合序列(帧)。
同样,机器学习领域的行家Chomba Bupe 也发出类似的质疑声音。 Chomba Bupe:
以下是OpenAI的Sora被称为数据驱动物理引擎的说法是多么愚蠢:这就像收集有关行星运动的数据,将其输入模型以预测行星的位置,并得出模型在内部恢复了广义相对论的结论。
爱因斯坦花了多年时间推导出引力理论的方程。如果有人认为随机梯度下降(SGD)+反向传播就像一个小爱因斯坦在模型训练过程中发现问题,那么你对机器学习的理解是可疑的。
我不在乎你是否拥有博士学位、学士学位或其他学历,如果你认为SGD + 反向传播就像一个小爱因斯坦,能够仅通过输入输出对来找出所有答案,那么你对机器学习的理解是不足的。
爱因斯坦在推导出引力理论时,需要对现实做出许多假设——光速恒定、时空是可弯曲的弹性物质,然后推导出导致重大发现(如黑洞、引力波等)的微分方程解。
他运用因果推理将不同的概念组合在一起。SGD + 反向传播并不具备这种能力,它只是将信息压缩到模型权重中,没有推理能力,只是更新并朝着具有最低误差的参数配置移动。
机器学习中的统计学习过程可能会陷入低误差盆地,即无法探索不同的概念,因为由于陷入低误差盆地或局部最小值,重新开始的行为是不可能的。
因此,SGD + 反向传播会发现脆弱的捷径解决方案,看起来似乎有效,但容易崩溃。这就是为什么深度学习系统不可靠且难以实际训练的原因,因为你必须不断更新和重新训练它们,这是繁琐的。
梯度下降的工作原理就像苍蝇找到气味源一样,苍蝇沿着空气中的化学浓度梯度向下移动,从而接近气味源,但如果仅依赖于这一点,它很容易陷入困境或迷失方向。
在机器学习中,模型的可调参数就是”苍蝇”,训练数据是气味源,由目标函数测量的误差就是气味。模型权重被调整以朝着气味源移动(在这种情况下,低误差等同于更强的气味)。
认为一个机器学习模型仅通过训练行星运动的视频就能在内部学习到广义相对论是更加荒谬的。这是对机器学习工作原理的严重误解。
面对大家的反对声音,Jim Fan再次发言。 Jim Fan:
我看到有人提出了一些异议:“Sora并没有学习物理,它只是在二维像素上进行操作。”
我对这种简化的观点持有不同意见。这就好像说“GPT-4并没有学习编程,它只是对字符串进行采样”一样。嗯,transformer只是在操作一系列整数(标记ID)。神经网络只是在操作浮点数。这不是正确的论点。
当你大规模扩展文本到视频训练时,Sora的软物理模拟是一种 emergent property( emergent property 是指在系统的组成部分之间相互作用的结果中出现的新特性)。
- GPT-4必须在内部学习某种形式的语法、语义和数据结构,以生成可执行的Python代码。GPT-4并没有明确存储Python语法树。
- 同样地,为了尽可能准确地建模视频像素,Sora必须学习一些_隐式_的文本到3D、3D变换、光线追踪渲染和物理规则。它必须学习游戏引擎的概念来满足目标。
- 如果我们不考虑交互作用,UE5只是一个(非常复杂的)生成视频像素的过程。Sora也是一个生成视频像素的过程,但是基于端到端的transformer。它们处于相同的抽象层次。
- 不同之处在于,UE5是手工制作的和精确的,而Sora纯粹是通过数据和”直观”学习的。
Sora会取代游戏引擎开发人员吗?绝对不会。它的 emergent physics( emergent physics 是指通过大规模训练产生的物理理解)理解是脆弱的,远非完美。它仍然会产生与我们的物理常识不兼容的幻觉。它还没有很好地掌握物体之间的相互作用 - 可以在下面的视频中看到一个奇怪的错误。
Sora就像是GPT-3时代的产物。回到2020年,GPT-3是一个相当糟糕的模型,需要大量的提示工程和监督。但它是首个令人信服的在上下文学习作为 emergent property 的引人注目的演示。
未来尚未来,拭目以待吧
在这个讨论中,专家们就这个议题存在着分歧。作为普通人、普通设计师,我们或许无法直接参与这些物理引擎的创造,但我们可以在应用它们的过程中发挥自己的创造力。
我们不必过分夸大Sora的影响力,也不必过早地认为未来已经来临,世界已经完全由虚拟构造而成。然而,我们不能忽视人工智能已经在改变世界的事实,它正在改变我们的生产方式、工作方式以及与技术的互动方式。因此,我们必须积极拥抱人工智能,以不被时代的浪潮所淘汰。
正如任何技术一样,人工智能并非完美无缺。它可能存在局限性和不确定性,但正是这些挑战激发了我们寻找创新解决方案的动力。作为设计师,我们应该善于思考如何将人工智能融入到我们的工作中,以更好地释放我们的创造力,提升设计的表达力。
同时,我们也要保持清醒的头脑。拥抱人工智能并不意味着盲目追随,而是理性地应用它的优势,同时保持对其潜在风险和伦理问题的敏感。只有在充分了解和掌握人工智能的基本原理和应用场景的基础上,我们才能更好地发挥它的潜力,避免被技术的潮流所淹没。
在这个快速变化的时代,我们需要保持灵活性和学习的态度。通过学习和不断探索,我们可以与时俱进,不断提升自己的技能和能力,以应对未来的挑战和机遇。
因此,作为普通的设计师,我们的责任不仅仅是追求技术的发展,更是要思考如何将技术与人类的情感、价值和美学相结合,创造出更具内涵和意义的设计作品。只有这样,我们才能真正发挥人工智能的潜力,为人类社会的进步和发展做出积极的贡献。