5分钟阅读
AI设计前沿速递:从精准视频编辑到单图LoRA训练
AI设计前沿速递:从精准视频编辑到单图LoRA训练
本期聚焦三大AI研究进展:Z-Image LoRA训练工具更新、MotionV2V视频运动编辑、Qwen-Image-i2L单图风格提取。这些技术正在降低创意工作的技术门槛,为设计师带来更高效、更可控的创作工具。
前言
对于设计师而言,AI不仅是效率工具,更是创意的延伸与思维的碰撞。从静态图像到动态视频,AI生成技术正以前所未有的速度进化,其核心挑战始终围绕“控制力”——如何让技术精准地服务于创意构想。本期精选的几项前沿研究,分别从模型训练、视频运动编辑和风格提取三个维度,展示了AI在提升创意可控性方面的最新突破,为设计工作流注入新的可能性。
一、Z-Image LoRA训练脚本更新
核心摘要: 开源工具Musubi Tuner近日更新了其文档,详细说明了如何利用AI Toolkit贡献者ostris提供的 De-Turbo模型 或 LoRA训练适配器 来训练Z-Image-Turbo模型。这为社区提供了更稳定、更高效的训练起点。
关键点:
- 背景:Z-Image-Turbo作为蒸馏模型,直接训练可能不稳定。ostris发布的De-Turbo模型解决了这一问题。
- 使用方法:用户可选择下载De-Turbo模型作为基础DiT模型,或使用训练适配器配合原版Turbo模型进行训练。
- 致谢:特别感谢ostris对开源社区的贡献。
编者注:Z-Image的实力已有目共睹,随着此类训练工具和生态的不断完善,预计将涌现更多生产力工具,进一步惠及开源社区和广大创作者。
二、MotionV2V:精准编辑视频中的物体运动

一句话概括:这项研究通过一个运动条件视频扩散模型,允许用户通过修改视频中稀疏的运动轨迹,来对现有视频进行极其精准和自然的编辑。
研究亮点:
- 新范式:不同于从头生成视频,它专注于编辑现有视频的运动。用户只需绘制或修改物体(如汽车、人物)的关键运动路径。
- 核心技术:研究者构建了一个包含“运动反事实”(内容相同、运动不同的视频对)的数据集,并在此基础上微调模型,使其学会理解和响应运动编辑指令。
- 效果卓越:在四向盲测用户研究中,该方法以超过65%的偏好度领先于此前的工作。
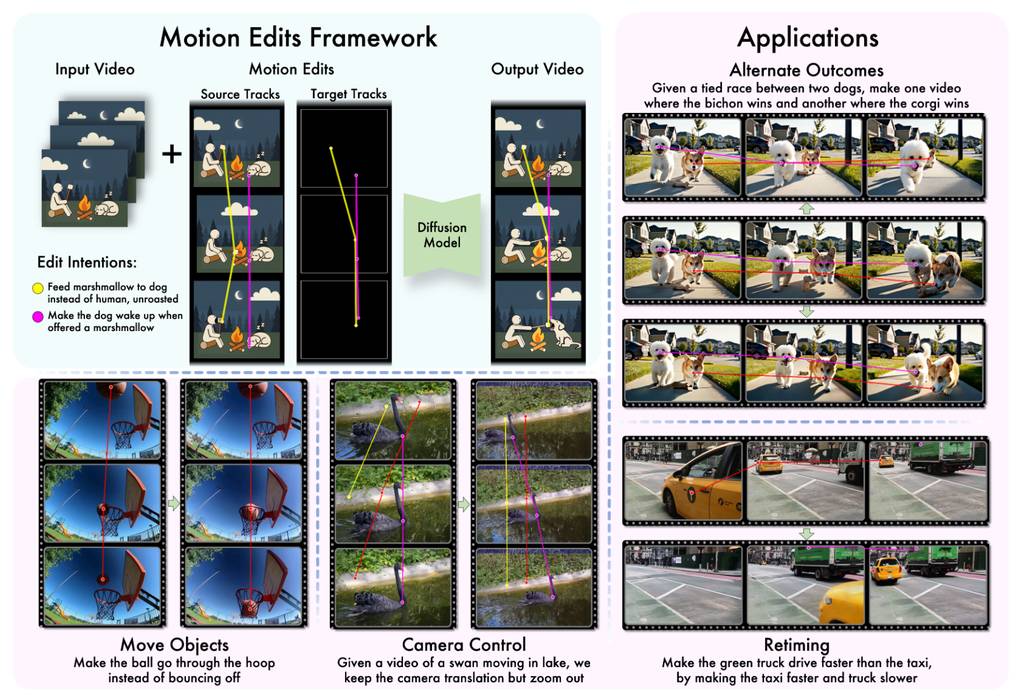 模型根据输入视频和编辑后的轨迹,生成运动被修改的新视频。
模型根据输入视频和编辑后的轨迹,生成运动被修改的新视频。
 修改船只航行方向、调整人物行走路径等。
修改船只航行方向、调整人物行走路径等。
项目主页: https://ryanndagreat.github.io/MotionV2V
编者注:对设计师的收益 这项技术为动态视觉设计、视频广告、创意短片制作打开了新的大门。设计师可以:
- 快速修正:无需复杂逐帧重拍或合成,即可调整视频中物体的运动速度、方向或轨迹。
- 创意实验:轻松尝试多种运动叙事方案(如让飞鸟改变队形、让车辆走不同路线),极大提升创意迭代效率。
- 增强可控性:将视频编辑的精度从“镜头级”提升到“物体运动轨迹级”,让创意执行更贴近初衷。
三、Qwen-Image-i2L:单图即可生成定制化LoRA
核心突破:只需一张参考图,就能快速训练出一个捕获其风格或内容的LoRA模型,极大降低了风格复刻的门槛。

提供的四种“风味”模型:
- 🎨 风格提取 (2.4B):专注于提取图像的纯粹美学风格。
- 🧩 粗粒度提取 (7.9B):同时捕获图像的内容和风格。
- ✨ 细粒度增强 (7.6B):专为1024x1024高分辨率设计,需与“粗粒度”模型搭配使用,以增强细节。
- ⚖️ 偏差对齐 (30M):一个小型适配器,用于使输出更符合Qwen-Image模型的原生风格倾向。
技术基础:融合了SigLIP-2、DINOv3和Qwen-VL等先进视觉模型的能力。
资源链接:
- 模型下载 (ModelScope):https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-i2L/summary
- 示例代码:https://github.com/modelscope/DiffSynth-Studio/blob/main/examples/qwen_image/model_inference_low_vram/Qwen-Image-i2L.py
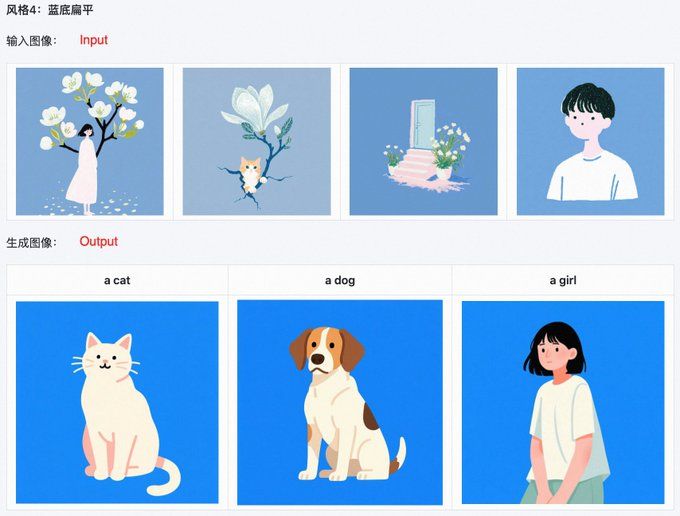 单图风格提取与生成效果。
单图风格提取与生成效果。
编者注:对设计师的收益 这可能是对设计师最“普惠”的工具之一:
- 极速风格化:看到心仪的插画、摄影或设计稿,几分钟内即可获得其风格LoRA,并应用于自己的创作中。
- 品牌风格统一:快速为品牌主视觉(如IP形象、特定色调与质感)创建定制化生成模型,确保营销物料风格高度一致。
- 降低技术依赖:将复杂的LoRA训练过程简化为“上传一张图”,让设计师能更专注于创意本身,而非技术调试。
写在最后
本期介绍的三个方向,清晰地勾勒出AI生成技术发展的趋势:更强的可控性、更低的使用门槛、更细的编辑粒度。无论是通过改进训练方式释放模型潜力(Z-Image),还是直接赋予用户编辑视频运动轨迹的能力(MotionV2V),抑或是将风格提取简化到极致(Qwen-Image-i2L),其最终目标都是让技术更好地成为创意的“副驾驶”。
对于设计师而言,主动了解并尝试这些工具,并非为了取代自身,而是为了拓展创意的边界,将重复性、技术性的工作交由AI高效完成,从而更专注于策略、审美与情感表达等核心价值。未来已来,唯有用好工具者,方能引领变革。
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。