5分钟阅读
IBM Granite 40:超高效、高性能的企业级混合架构大模型

核心信息速览
IBM 正式发布新一代语言模型 Granite 4.0,其核心亮点可概括为以下三点:
- 创新混合架构:采用全新 Mamba/Transformer 混合架构,在不牺牲性能的前提下大幅降低内存需求,可在成本更低的 GPU 上运行,相比传统大模型(LLM)显著降低使用成本。
- 安全合规与开源:基于 Apache 2.0 协议开源,是全球首个获得 ISO 42001 认证 的开源模型;同时通过加密签名验证,确保符合国际公认的安全、治理与透明度最佳实践。
- 多平台便捷获取:目前已在 IBM watsonx. ai 上线,同时通过多家平台合作伙伴提供服务(按字母顺序排列):Dell Technologies(Dell Pro AI Studio 与 Dell Enterprise Hub)、Docker Hub、Hugging Face、Kaggle、LM Studio、NVIDIA NIM、Ollama、OPAQUE、Replicate;后续还将陆续支持 Amazon SageMaker JumpStart 与 Microsoft Azure AI Foundry。
Granite 4.0 的发布,标志着 IBM 企业级大模型家族进入新纪元。该模型借助创新架构优势,聚焦“轻量高效型语言模型”——在降低成本与延迟的同时,保持具有竞争力的性能。其研发重点针对智能体工作流(agentic workflows)的核心任务,既可独立部署,也能作为低成本构建模块,与更大型推理模型协同组成复杂系统。
一、Granite 4.0 模型家族:多尺寸适配不同硬件需求
为满足各类硬件约束下的最优生产部署需求,Granite 4.0 系列包含多种尺寸与架构类型的模型,具体如下:
| 模型名称 | 架构类型 | 参数规模 | 核心特点与适用场景 |
|---|---|---|---|
| Granite-4.0-H-Small | 混合专家模型(MoE) | 总参数 320 亿(激活 90 亿) | 企业级工作流“主力模型”,兼顾性能与成本,适用于多工具智能体、客户支持自动化等场景 |
| Granite-4.0-H-Tiny | 混合专家模型(MoE) | 总参数 70 亿(激活 10 亿) | 低延迟模型,适用于边缘设备、本地部署,也可作为大型智能体工作流的构建模块(如函数调用) |
| Granite-4.0-H-Micro | 密集型混合模型 | 30 亿参数 | 轻量密集型混合架构,平衡效率与基础性能 |
| Granite-4.0-Micro | 传统 Transformer 架构 | 30 亿参数 | 采用传统注意力驱动架构,适配暂不支持混合架构的平台与社区 |
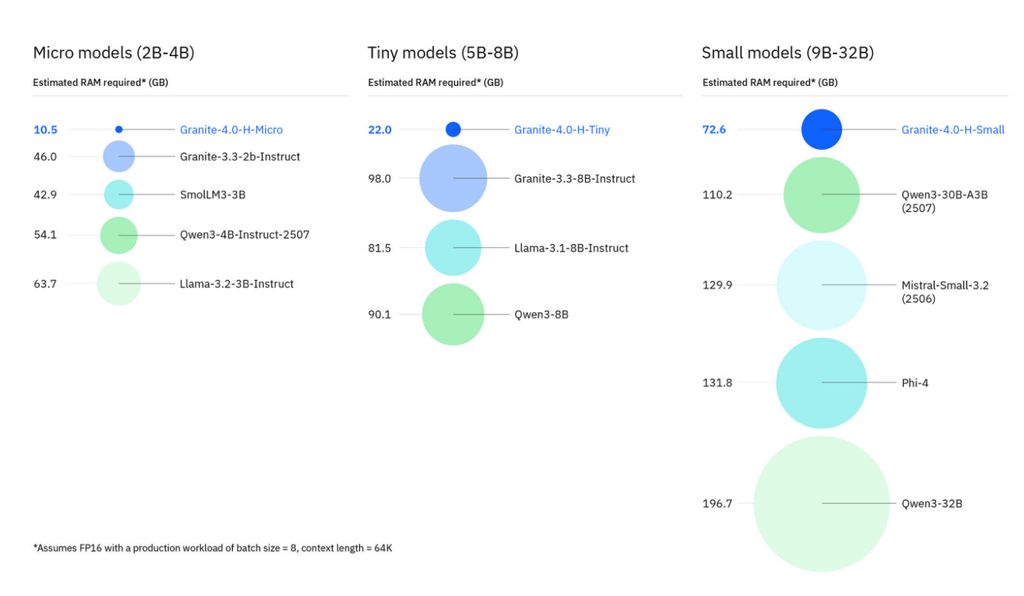
从基准测试表现来看,Granite 4.0 全系列模型相较上一代有显著提升——即便最小的 Granite 4.0 模型(如 30 亿参数的 Micro 版),也能超越上一代 80 亿参数的 Granite 3.3,且参数规模还不到后者的一半。其最突出的优势在于 推理效率的大幅提升:相比传统大模型,Granite 4.0 混合架构模型运行所需内存显著减少,尤其在处理“长上下文任务”(如读取大型代码库、长文档)与“多会话并发”(如客服智能体同时处理多个用户咨询)时,优势更为明显。
更重要的是,内存需求的降低直接带来硬件成本的下降——无论是企业还是开源开发者,都能以更低成本获取性能竞争力强劲的大模型,大幅降低了企业级大模型的应用门槛。
二、安全与透明度:企业级信任基石
IBM 在追求“全硬件适配的实用推理效率”的同时,同样重视模型生态的安全、合规与透明度。经过数月的外部审计,IBM Granite 成为目前 唯一获得 ISO 42001 认证的开源语言模型家族——该认证是全球首个针对 AI 管理系统(AIMS)的国际标准,涵盖问责制、可解释性、数据隐私与可靠性等核心维度。
为进一步强化信任基础,IBM 还采取了两项关键措施:
- 与 HackerOne 合作推出 Granite 漏洞赏金计划,鼓励开发者发现模型潜在风险;
- 对 Hugging Face 平台上所有 4.0 版本模型 checkpoint 进行 加密签名,开发者与企业可通过签名验证模型的来源与真实性,确保未被篡改。
目前,EY、洛克希德·马丁(Lockheed Martin)等企业合作伙伴已提前获得 Granite 4.0 的大规模测试权限,其反馈与开源社区的建议将用于后续模型优化。本次发布的模型包含 Micro、Tiny、Small 三个尺寸的 Base 版(基础模型) 与 Instruct 版(指令微调模型);2025 年底前,IBM 还计划推出更多尺寸(包括更大与更小参数模型)及支持显式推理功能的模型变体。
三、Granite 4.0 推理效率:混合架构的核心优势
Granite 4.0 混合架构模型的推理速度与内存效率,显著优于同等参数规模的传统 Transformer 架构模型。其核心设计逻辑是:将少量传统 Transformer 注意力层 与大量 Mamba 层(更具体地说是 Mamba-2 层)结合——Mamba 处理语言的方式与传统大模型完全不同,且效率远超后者。
1. 内存占用:长上下文与并发场景的突破
传统大模型的 GPU 内存需求,通常仅以“加载模型权重所需内存”为衡量标准;但企业级场景(如大规模部署、复杂环境下的智能体 AI、检索增强生成(RAG)系统)往往需要处理“长上下文”“批量并发推理”,或两者兼具。IBM 在研发 Granite 4.0 时,充分考虑了这些企业实际需求,重点优化了长上下文与多会话并发能力。
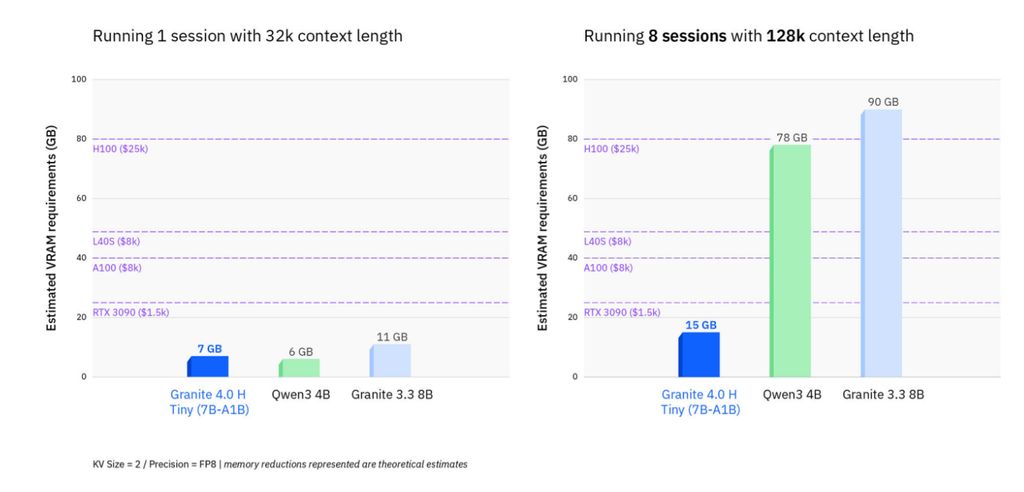
相比传统 Transformer 模型,Granite 4.0-H 处理“长输入+多并发批次”时,内存需求可降低 70% 以上。
此外,Granite 4.0 混合架构模型兼容 AMD Instinct™ MI-300X GPU,可进一步减少内存占用。
2. 推理速度:高负载下的持续高效
传统大模型的问题在于:随着上下文长度或批次规模增加,吞吐量会显著下降;而 Granite 4.0 混合架构模型即便在“其他模型变慢甚至超出硬件承载能力”的高负载场景下,仍能保持输出加速——任务复杂度越高,其效率优势越明显。
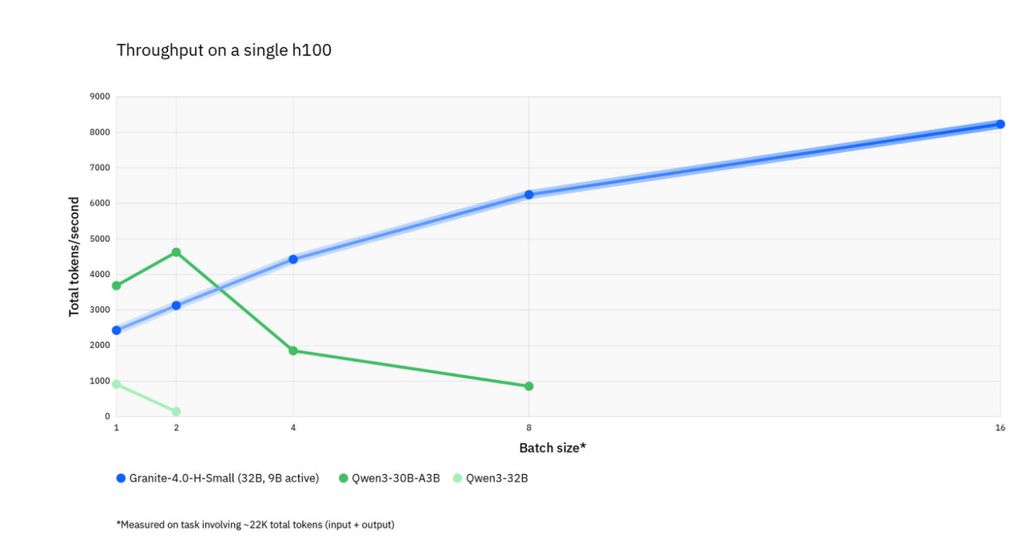
不同工作负载下的模型吞吐量对比,线条终止处表示模型内存需求超出 H100 GPU 承载能力
为进一步优化端侧部署速度,IBM 还与高通(Qualcomm Technologies, Inc.)、Nexa AI 合作,确保 Granite 4.0 兼容 Hexagon™ NPU,可在智能手机、PC 等设备上实现高效的本地推理。
四、Granite 4.0 性能:效率与质量兼得
效率优势的核心价值,最终需通过“模型输出质量”来体现——Granite 4.0 在同参数规模模型中性能竞争力强劲,尤其在“智能体 AI 关键任务”(如指令遵循、函数调用)的基准测试中表现突出。
1. 跨维度性能提升
Granite 4.0 全系列模型相较上一代 Granite 模型,实现了全维度性能提升。其中,混合架构主要贡献“效率与训练效能”,而 模型准确率的提升 则源于两方面:
- 训练(及训练后优化)方法的改进;
- Granite 训练数据集的持续扩充与精细化。
这也是为何即便采用“与上一代类似的传统 Transformer 架构”的 Granite 4.0-Micro,也能显著超越 Granite 3.3 8B 模型。
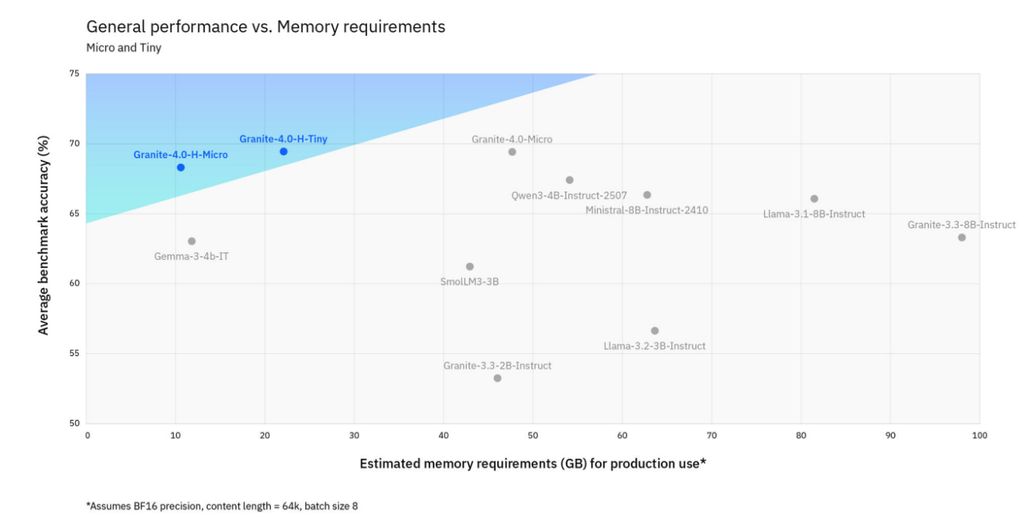
生产级内存需求与多基准测试(MMLU、BigBenchHard、GSM8K、GSM8K-Symbolic、CruxEval-O、EvalPlus)平均性能对比,阴影区域表示“性能/内存性价比”更优区间
2. 企业场景核心任务表现突出
在企业级场景与智能体工作流关键任务中,Granite 4.0 表现尤为亮眼:
- 指令遵循(IFEval):通过斯坦福 HELM 评估,Granite-4.0-H-Small 在 IFEval 基准测试(衡量模型遵循明确指令能力的主流指标)中,超越了所有开源权重模型(仅落后于参数规模达 4020 亿、是其 12 倍以上的 Llama 4 Maverick);
- 函数调用(BFCLv3):在伯克利函数调用排行榜 v3(BFCLv3)中,Granite-4.0-H-Small 可与更大型的开源/闭源模型比肩,且成本远低于同性能竞品;
- 复杂 RAG 任务(MTRAG):在 MTRAG 基准测试(衡量多轮对话、不可回答问题、非独立问题、跨领域信息处理等复杂 RAG 能力)中表现优异。
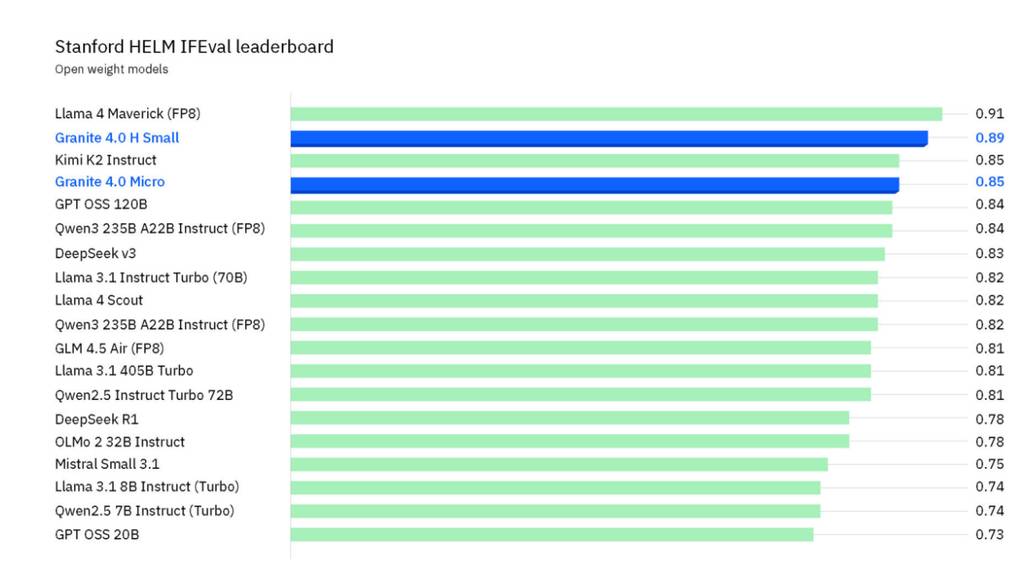
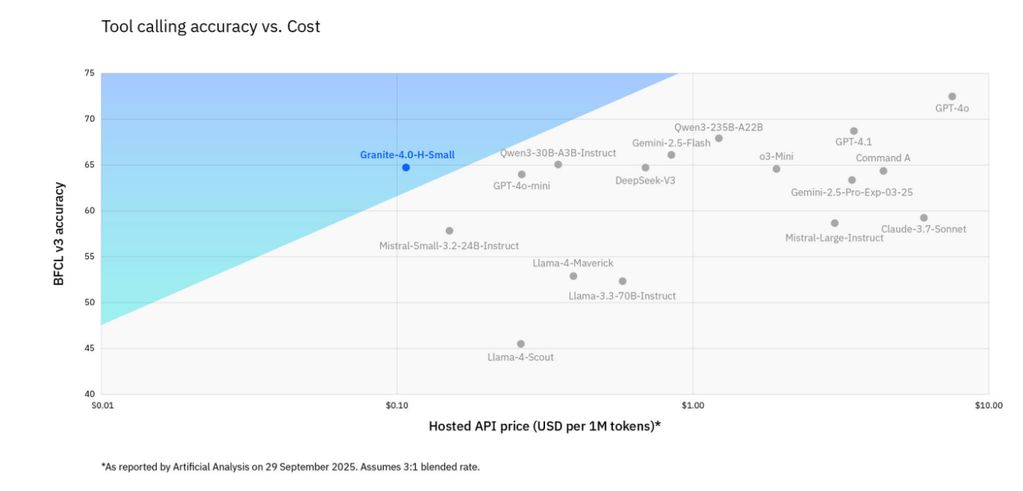
BFCLv3 函数调用基准测试性能对比,蓝色区域表示“性能/成本性价比”更优区间
更多评估指标可参考 Granite 4.0 的 Hugging Face 模型卡片。
五、为何探索 Mamba 模型?Transformer 的效率瓶颈与 Mamba 的突破
尽管 Transformer 模型优势显著,但存在一个核心缺陷:计算需求随序列长度呈二次方增长——若上下文长度翻倍,Transformer 需执行的计算量(及内存存储量)会变为原来的 4 倍。这种“二次方瓶颈”会导致上下文越长,模型速度越慢、成本越高,甚至会耗尽高端消费级 GPU 的内存。
而 Mamba 模型采用完全不同的 选择性机制(selectivity mechanism),天生具备更高效率:其计算需求随序列长度呈 线性增长——上下文翻倍时,计算量仅翻倍(而非 4 倍);更重要的是,Mamba 的内存需求不随序列长度变化,始终保持恒定。任务复杂度越高,Mamba 相对 Transformer 的优势越明显。
不过,Transformer 及其自注意力机制在部分场景(如上下文学习,例如少样本提示(few-shot prompting))中仍有优势。因此,将两者结合的“混合架构”可实现“优势互补”,兼顾效率与特定任务性能。更多细节可参考此前发布的 Granite-4.0-Tiny-Preview 前瞻内容。
六、Granite 4 架构:Mamba 与 Transformer 的协同设计
Granite 4.0-H-Micro、Granite 4.0-H-Tiny、Granite 4.0-H-Small 采用的混合架构,将 Mamba-2 层 与传统 Transformer 块 按 9:1 的比例顺序组合——核心逻辑是:
- Mamba-2 块高效处理全局上下文;
- 定期将上下文信息传递给 Transformer 块,通过自注意力实现对局部上下文的精细解析;
- 解析后的信息再传递给下一组 Mamba-2 层,持续处理后续内容。
1. 生态适配与专家混合(MoE)优化
目前多数大模型部署基础设施是为“纯 Transformer 模型”设计的。因此,在本次正式发布前,IBM 已通过今年早些时候的 Granite 4.0-Tiny-Preview 实验性发布,与生态伙伴深度协作,确保混合架构在主流推理框架中获得支持,包括 vLLM、llama. cpp、NexaML、MLX 等。
其中,Granite-4.0-H-Tiny 与 Granite-4.0-H-Small 还将每个 Mamba-2 块与 Transformer 块的输出传递给“细粒度专家混合(MoE)块”(其参数规格较 Granite 4.0-Tiny-Preview 略有调整)。值得注意的是,这两款模型首次采用了 共享专家(shared experts) 设计——共享专家始终处于激活状态,既提升了参数效率,也让其他“专家”能更专注于发展特定领域的专业能力(IBM 自 2024 年发布 Granite 3.0 以来,一直致力于细粒度 MoE 的研究)。
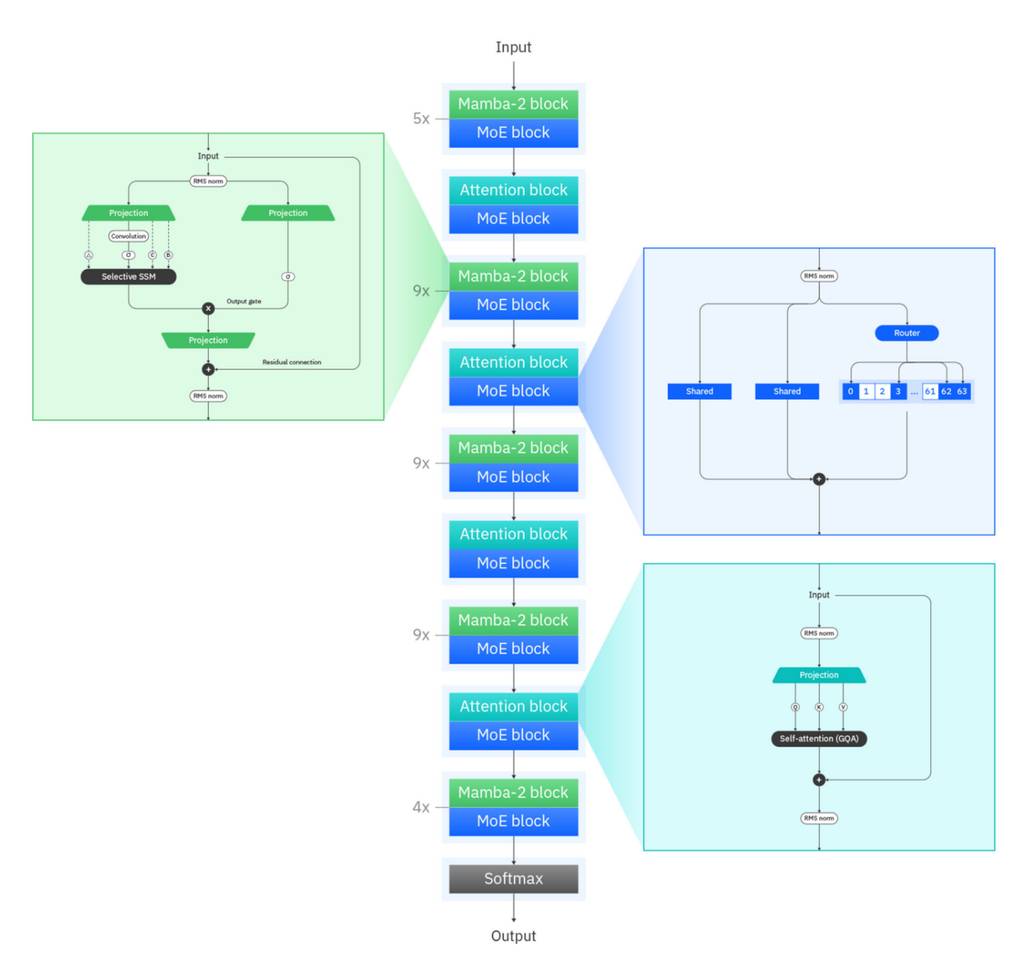
Granite-4.0-H-Tiny 采用的混合架构示意图
而 Granite 4.0-H-Micro 则用传统密集型前馈层替代了 MoE 块,其他架构设计与 Tiny、Small 保持一致。
2. 无约束上下文长度:无需位置编码的突破
基于状态空间模型(SSM)的语言模型(如 Mamba),一个极具吸引力的潜力是“处理无限长序列”。Granite 4.0 全系列模型均在“上下文长度达 512K tokens 的数据样本”上完成训练,且已在“128K tokens 上下文任务”中验证了性能;理论上,其上下文长度还可进一步扩展。
传统 Transformer 模型的最大上下文窗口,受限于 位置编码(positional encoding, PE)——由于 Transformer 的自注意力机制会同时处理所有 token。,无法保留 token 的顺序信息,因此需要通过位置编码补充这一关键信息。但现有研究表明,采用旋转位置编码(RoPE)等主流技术的模型,在处理“超出训练阶段所见长度”的序列时,性能会明显下降。
而 Granite 4.0-H 架构完全不依赖位置编码(NoPE)。究其原因,Mamba 模型本身会以“顺序读取”的方式处理 token,天然具备保留序列顺序信息的能力,因此无需额外的位置编码辅助。
七、Granite 4.0 的训练:企业级数据与精细化流程
尽管架构存在差异,所有 Granite 4.0 模型的训练均基于同一套精心构建的资源与流程,确保性能与企业场景适配性:
- 训练数据:从包含 22 万亿 token 的企业级语料库中采样,涵盖 DataComp-LM(DCLM)、GneissWeb、TxT360 子集、维基百科及其他企业相关数据源,确保内容的专业性与合规性;
- 训练工具:所有训练数据集均通过开源框架 Data Prep Kit 处理,保障数据质量与一致性;
- 精细化优化:在预训练基础上,通过“合成数据+开源数据”结合的方式进行post-training(训练后优化),重点强化语言理解、代码生成、数学计算、推理、多语言处理、安全合规、工具调用、RAG、网络安全等企业核心任务能力。
与上一代 Granite 模型相比,本次训练有一个关键调整:将 post-training 后的模型拆分为 Instruct 版(指令微调模型) 与 Thinking 版(推理模型)。IBM 表示,这一调整源于行业最新研究结论——拆分训练可让 Instruct 模型在“指令遵循”任务上表现更优,Thinking 模型在“复杂逻辑推理”任务上更具优势,同时还能简化两类模型的对话模板设计。目前已发布 Instruct 版,Thinking 版计划于今年秋季推出。
八、IBM Granite 的未来规划
Granite 4.0 的发布并非终点,IBM 已明确后续发展路线,持续完善模型生态:
- 秋季更新:推出 Granite 4.0 各尺寸模型的“Thinking 版”,进一步强化复杂推理能力;
- 年底前扩展:新增更多模型尺寸,既包括面向中高负载场景的 Granite 4.0 Medium,也包括专为边缘设备设计的轻量级模型 Granite 4.0 Nano,覆盖更广泛的部署需求。
九、快速上手 Granite 4.0
目前,Granite 4.0 已通过多平台与框架开放使用,无论是独立部署还是集成到复杂工作流中,都能实现高效落地:
- 体验入口:可直接在 Granite Playground 在线试用模型功能;
- 框架支持:混合架构在 vLLM 0.10.2 与 Hugging Face Transformers 中已实现“全功能优化支持”,在 llama. cpp 与 MLX 中也已支持基础功能(吞吐量优化仍在推进中);
- 平台与工具适配:
- 企业级平台:IBM watsonx. ai(IBM 旗下集成 AI 开发平台,支持模型快速规模化部署)已上线 Instruct 版;
- 第三方平台:通过 Dell Technologies(Dell Pro AI Studio、Dell Enterprise Hub)、Docker Hub、Hugging Face、Kaggle、LM Studio、NVIDIA NIM、Ollama、OPAQUE、Replicate 等平台可获取 Instruct 版,Base 版可通过 Hugging Face 下载;
- 微调与开发工具:支持通过 Unsloth 进行“快速、低内存消耗”的微调,也可集成到 Continue 工具中,打造定制化 AI 编码助手。
如需详细部署指南与实践方案,可参考 Granite Docs 官方文档。
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。