5分钟阅读
值得关注的几个AI信息
今天为大家捋捋最近一周的AI动效,覆盖了AI生成3D、AI视频等领域。
- 英伟达发布 L4GM。直接生成会动的3D模型
- 可以直接生成海报(包含文字)的
Glyph-ByT5技术 - Neural Gaffer:通过扩散重新照明任何对象
英伟达发布 L4GM

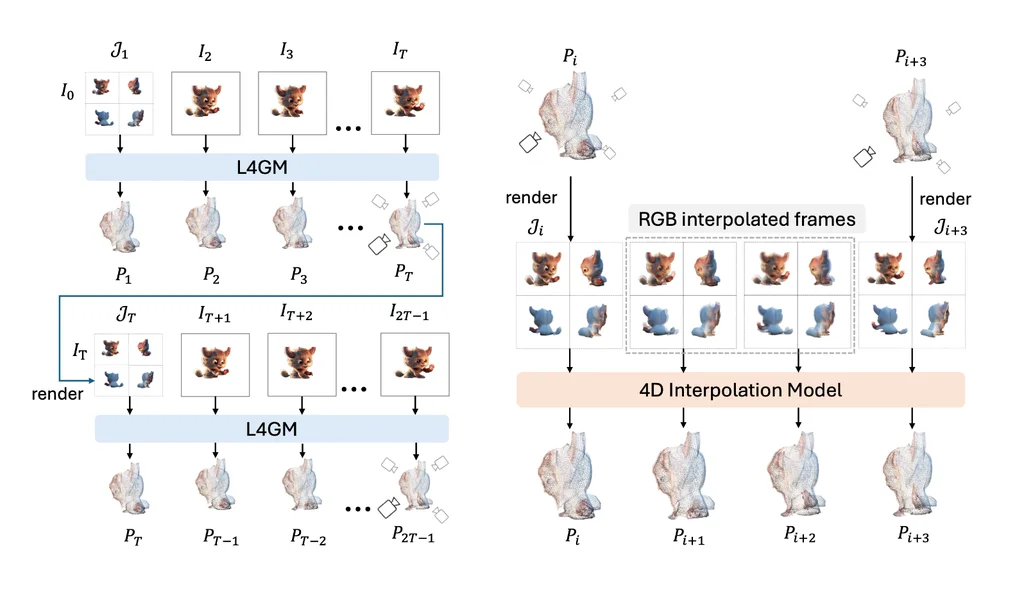
英伟达的L4GM技术,标志着4D对象重建领域的重大突破。这一创新模型能够直接从单一视角的视频输入中快速生成4D重建,为视觉计算带来了革命性的速度和效率。
-
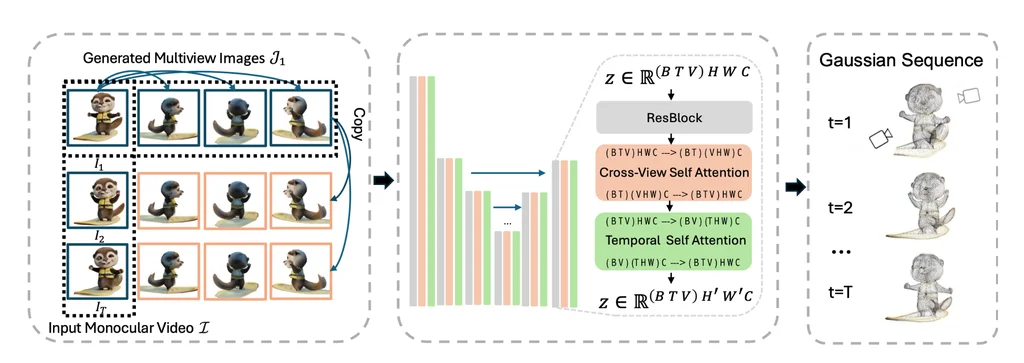
多视角视频数据集的丰富性:L4GM的训练基于一个庞大的多视角视频数据集,该数据集涵盖了Objaverse提供的4.4万个独特对象和11万个动态动画。这些动画在48个不同的视角下被渲染,累积产生了1200万个视频,包含超过3亿帧的丰富视觉信息。
-
模型架构的先进性:L4GM模型架构继承自LGM,这是一个预训练的3D大规模重建模型。L4GM能够从多视角图像输入中智能生成3D高斯椭球,为对象的形状和体积提供了更为精确的描述。
-
时间自注意力层的创新:L4GM引入了时间自注意力层,这一创新技术使得模型能够学习视频中时间序列上的一致性,确保动态对象在时间推移中的连贯性和稳定性。
-
多视角渲染损失的精准训练:通过在每个时间步采用多视角渲染损失的训练方法,L4GM确保了在生成动画时的高一致性,进一步提升了重建结果的真实性和可靠性。
L4GM技术的问世,不仅展示了英伟达在图形处理和机器学习领域的深厚实力,也为未来的多媒体内容创作、虚拟现实和增强现实体验提供了无限可能。随着技术的不断进步,我们有理由相信,L4GM将引领我们进入一个全新的4D视觉时代。
论文地址:https://research.nvidia.com/labs/toronto-ai/l4gm/
可以直接生成海报(包含文字)的Glyph-ByT5技术

好家伙,前天我刚研究了一个工作流(传送门:# 【AI辅助设计】把ComfyUI当成PS用!一键制作简单海报!)用于生成海报,这个技术就发布出来了,从模型根本上解决海报的生成问题。
视觉文本渲染增强与Glyph-SDXL

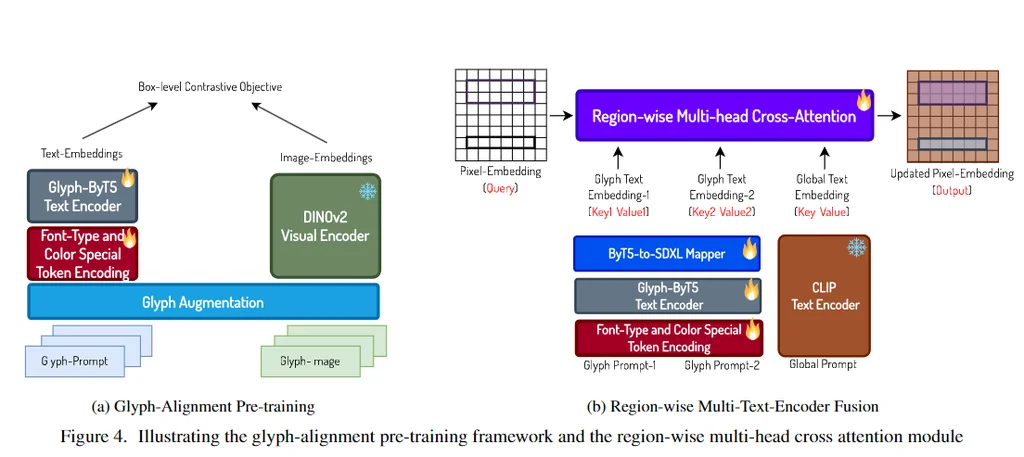
在文本到图像生成模型中实现准确的视觉文本渲染一直是一个重大挑战,这主要归因于文本编码器的不足。为了解决这个问题,我们确定了并实现了两个高级文本编码器的基本要求:字符意识和与字形对齐。
文本编码器的关键要求
- 字符意识:编码器识别和解释单个字符的能力。
- 与字形对齐:确保编码器的输出与文本的视觉表现形式精确对齐。
我们的解决方案:Glyph-ByT5
我们开发了一系列定制的文本编码器,命名为Glyph-ByT5,通过对具有字符意识的ByT5编码器进行微调,使用了精心策划的字形-文本配对数据集来提升编码器的能力。

与SDXL的集成
我们提出了一种有效的方法,将Glyph-ByT5与SDXL集成,从而创建了Glyph-SDXL模型。该模型专门设计用于生成具有准确文本渲染的图像。
结果
- 文本渲染准确性:在我们的设计图像基准测试中,准确率从不到20%提高到近90%。
- 文本段落渲染:Glyph-SDXL展示了渲染文本段落的能力,能够在自动化多行布局中实现数十到数百个字符的高拼写准确性。
通过微调增强
通过对Glyph-SDXL进行微调,使用一小组高质量的、具有视觉文本的真实感图像,我们在开放领域真实图像的场景文本渲染能力上取得了显著改进。

结论
这些引人注目的成果旨在鼓励在设计定制文本编码器方面进行进一步探索,以应对多样化和具有挑战性的任务。Glyph-SDXL所带来的进步不仅增强了当前文本到图像生成模型的状态,而且为该领域未来的发展开辟了新的可能性。
一句话:canvas这类低门槛设计工具,应该开始居安思危了~
论文地址:https://arxiv.org/pdf/2403.09622
抱脸地址:https://huggingface.co/papers/2403.09622
Neural Gaffer:通过扩散重新照明任何对象

大家还记得我之前写过关于重新打光的几篇文章吗?
今天又出来了一个新的技术,更加强大。
背景介绍
单图像重新照明是一项具有挑战性的任务,需要推理几何、材料和照明之间的复杂相互作用。现有方法存在以下局限:
- 类别限制:仅支持特定类别的图像(如肖像)。
- 特殊条件:需要特殊的拍摄条件(如使用手电筒)。
- 场景分解:显式地将场景分解为内在组件(如法线和BRDF),但这些方法可能不准确或表达不足。
方法概述
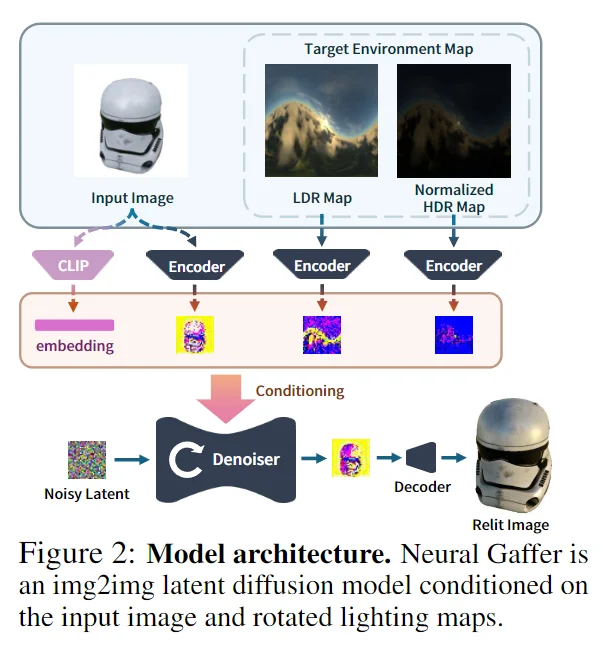
我们提出了一种新颖的端到端2D重新照明扩散模型,称为 Neural Gaffer。该模型具有以下特点:
- 输入:任意物体的单张图像。
- 输出:在任何新的环境光照条件下生成准确、高质量的重新照明图像。
- 无需显式场景分解:通过将图像生成器条件化在目标环境图上实现。
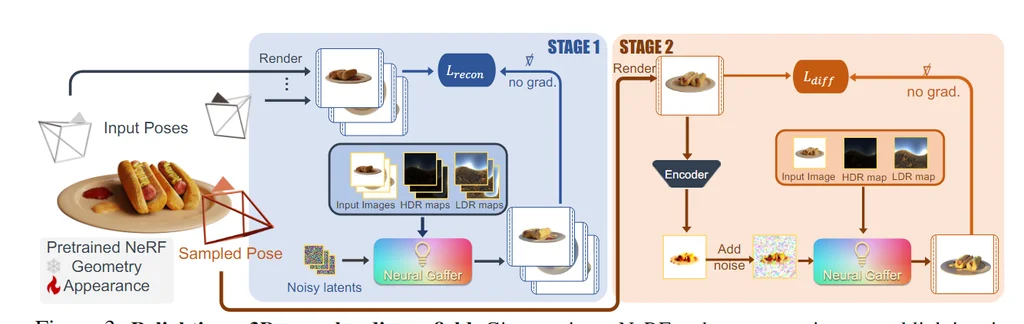
技术细节
- 预训练模型:基于一个预训练的扩散模型。
- 微调数据集:在一个合成重新照明数据集上进行微调。
- 照明理解:揭示并利用扩散模型中固有的照明理解能力。

评估与优势

我们在以下数据集上对模型进行了评估:
- 合成图像
- 实际互联网图像
评估结果展示了模型在泛化和准确性方面的优势。
下游任务
通过与其他生成方法结合,Neural Gaffer 能够实现许多下游的2D任务,包括:
- 基于文本的重新照明
- 物体插入
此外,模型还可以作为3D任务(如重新照明辐射场)的强大重新照明先验。
一句话:AI模拟物理世界,又进了一步了。
论文地址:https://arxiv.org/pdf/2406.07520
好了,今天的介绍就到这里,有什么疑问或者问题,可以留言交流哦~ 关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。