5分钟阅读
如何使用 RAGAs 框架评估您的 RAG

目录
什么是 RAG 评估?
RAG 评估是指评估模型将检索到的信息整合到其响应中的效果。这不仅需要评估生成文本的质量,还需要评估检索信息的准确性、相关性,以及其对最终输出的增强效果。
构建 RAG 管道相对简单,您只需要一个向量数据库知识库、一个处理提示的 LLM,以及一些用于模块间交互的逻辑。
然而,由于 RAG 管道包含多个“独立”组件,因此要达到令人满意的性能水平也面临着挑战:
-
检索器: 负责查询知识数据库并检索与用户查询匹配的附加上下文。
-
生成器: 包含 LLM 模块,根据上下文增强的提示生成答案。
在评估 RAG 管道时,我们必须分别和整体评估这两个组件,才能了解 RAG 管道是否以及在何处需要改进,最终确定其“质量”。此外,为了解其性能是否提升,我们需要对其进行量化评估。
RAGAs 框架
Ragas 是一个用于评估检索增强生成 (RAG) 管道的框架。尽管市面上已有一些工具和框架可以帮助您构建 RAG 管道(例如 LLamaIndex),但评估和量化管道性能仍然是一个难题。
而这正是 Ragas(RAG 评估)的优势所在。
RAGAs [5] 框架(5.3k ⭐️)是开源的,属于 explodinggradients 组的一部分,并附带一篇论文投稿:RAGAs 论文 [6]
RAGAs 的核心概念之一是指标驱动开发(MDD),这是一种依赖数据做出明智决策的产品开发方法。其重点是利用底层强大的 LLM 进行有针对性的评估,而不是依赖 HITL(人工参与循环)进行人工标注。
RAGAs 指标
让我们来看看 RAGAs 指标 [4] 中包含的内容:
检索阶段的指标 🔽 :
-
上下文精度: 评估用于生成答案的上下文的精度,确保从中选择了相关信息。
-
上下文相关性: 衡量所选上下文与问题的相关程度,帮助改进上下文选择,提高答案准确性。
-
上下文召回率: 衡量是否检索到回答问题所需的所有相关信息。
-
上下文实体召回率: 评估上下文中的实体召回率,确保在检索过程中没有遗漏任何重要实体。
生成阶段的指标 🔽 :
-
忠实度: 衡量生成的答案反映源内容的准确程度,确保生成内容真实可靠。
-
答案相关性: 评估答案与给定问题的相关程度,验证答案是否直接解决了用户的查询。
-
答案语义相似度: 量化生成的答案与预期的“理想”答案之间的语义相似度,表明生成内容在语义上与预期答案一致。
-
答案正确性: 专注于事实核查,评估生成答案的事实准确性。
您可以根据需要选择使用部分或全部指标进行评估。在我们的 LLM-Twin RAG 用例中,我们将使用以下 6 个指标来评估检索和生成模块:
-
检索: 上下文精度、召回率、相关性和实体召回率。
-
生成: 答案相关性、答案语义相似度。
RAGAs 评估格式
为了评估 RAG 管道,RAGAs 要求数据集采用以下格式:
question : 用户查询,作为 RAG 的输入。
answer : RAG 管道根据查询和上下文提示生成的答案。
contexts : 从知识库(向量数据库)中检索到的上下文。
ground\_truths : 问题的标准答案。
[注意] : 只有在使用 ContextRecall 指标时才需要 `ground_truths` 字段。
content_copyUse code with caution.
📓 所有 RAGAs 指标都使用 question、answer 和 contexts 字段。需要注意的是,只有 Context Recall 指标需要 ground_truths 字段,因为它用于衡量是否从向量数据库中检索到回答问题所需的所有相关信息。
以下是一个 RAGAs 数据集示例:
from datasets import Dataset
questions = ["埃菲尔铁塔是什么时候建造的,有多高?"]
answers = ["截至 2023 年 4 月的最新更新,埃菲尔铁塔建于 1889 年,高 324 米"]
contexts = ["埃菲尔铁塔是法国巴黎最具吸引力的纪念碑之一。它建于 1889 年,是 1889 年世界博览会的入口拱门。它高 324 米。"]
ground\_truths = [["埃菲尔铁塔建于 1889 年,高 324 米。"]]
sample = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground\_truths": ground\_truths
}
eval\_dataset = Dataset.from\_dict(sample)
content_copyUse code with caution.Python
数据集结构如下:
Dataset({
features: ['question', 'answer', 'contexts', 'ground\_truths'],
num\_rows: 1
})
content_copyUse code with caution.
创建数据集后,您需要将一组指标传递给 RAGAs 的 evaluate 方法:
from ragas import evaluate
from ragas.metrics import (
answer\_similarity,
context\_relevancy,
)
scores = evaluate(
dataset=eval\_dataset,
metrics=[context\_recall, answer\_similarity]
)
content_copyUse code with caution.Python
了解了使用 RAGAs 的先决条件后,让我们来看看如何将其应用于 LLM-Twin RAG 评估用例。
如何评估 RAG 应用?
在本节中,我们将重点关注 LLM Twin 系统设计的以下部分:
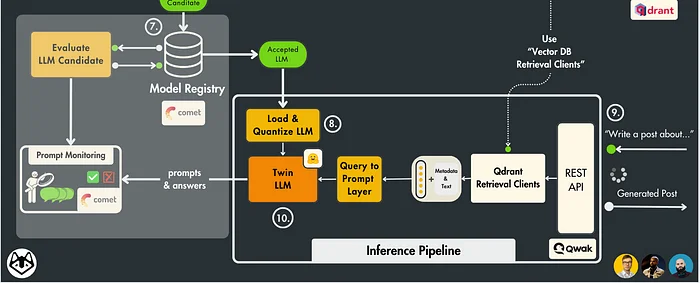
LLM Twin 系统设计的一部分。图片由作者提供。
工作流程概述:
-
定义评估提示模板。
-
定义用户查询。
-
从向量数据库中检索与用户查询相关的上下文。
-
格式化提示并将其传递给 LLM 模型。
-
捕获答案,并使用查询和上下文准备评估数据样本。
-
使用 RAGAs 进行评估。
-
构建评估链路,附加元数据,并记录到 CometML。
🗒 在深入实现之前,需要注意的是,我们的目标是让 LLM-Twin 模仿我们的写作风格。
对于这个特定的用例,我们可以直接使用从向量数据库中检索到的 context 作为评估时的 ground_truth。
为什么❓
因为我们已经将自己的作品(帖子/文章/代码)存储在向量数据库中,所以它们可以同时扮演两个角色,既可以作为传递给 LLM 生成答案的 context,也可以作为评估 RAG 响应时进行比较的 ground_truth。
接下来,让我们按照以下步骤进行实现:
-
介绍提示模板。
-
准备用于评估的 query/response/context 有效负载。
-
使用 RAGAs 进行评估。
-
在 CometML 上监控所有内容。
生成提示模板
class InferenceTemplate(BasePromptTemplate):
simple\_prompt: str = """您是一位 AI 语言模型助手。您的任务是对用户问题生成一个连贯且简洁的回复。
问题:{question}
"""
rag\_prompt: str = """ 您是技术内容写作方面的专家。您的任务是根据用户查询,在给定特定上下文的情况下创建技术内容,
并结合用户先前作品及其知识的附加信息。
以下是在解决此任务时需要遵循的步骤列表:
步骤 1:您需要分析用户提供的查询:{question}
步骤 2:您需要分析提供的上下文以及其中的信息与用户问题的相关性:{context}
步骤 3:生成内容时要牢记,它需要尽可能与查询中呈现的主题保持连贯和简洁,并且类似于用户在上下文中呈现的写作风格和知识。
"""
def create\_template(self, enable\_rag: bool = True) -> PromptTemplate:
if enable\_rag is True:
return PromptTemplate(
template=self.rag\_prompt, input\_variables=["question", "context"]
)
return PromptTemplate(template=self.simple\_prompt, input\_variables=["question"])
content_copyUse code with caution.Python
在这个模板中,我们在 system prompt 中指定 LLM 模型应该分析 步骤 1 中的 query,分析 步骤 2 中检索到的 context,并遵守 步骤 3 中的生成指令。
准备评估有效负载
我们先按顺序迭代每个模块。我们已经定义了 PromptTemplate,并将 question 字段设置为用户输入的查询。接下来,我们需要从向量数据库中检索上下文样本。
以下是检索逻辑:
retriever = VectorRetriever(query=query)
hits = retriever.retrieve\_top\_k(
k=settings.TOP\_K, to\_expand\_to\_n\_queries=settings.EXPAND\_N\_QUERY
)
context = retriever.rerank(hits=hits, keep\_top\_k=settings.KEEP\_TOP\_K)
prompt\_template\_variables["context"] = context
prompt = prompt\_template.format(question=query, context=context)
content_copyUse code with caution.Python
要深入了解代码中第 3 步提到的重新排序技术,请查看 📓 第 5 课。
检索到上下文后,我们将提示传递给部署在 Qwak [2] 上的推理管道,并获取 LLM 生成的响应。
要深入了解推理管道的构建和部署过程,请查看
📓第 9 课。
接下来是评估代码块:
if enable\_evaluation is True:
if enable\_rag:
st\_time = time.time\_ns()
rag\_eval\_scores = evaluate\_w\_ragas(
query=query, output=answer, context=context
)
en\_time = time.time\_ns()
self.\_timings["evaluation\_rag"] = (en\_time - st\_time) / 1e9
st\_time = time.time\_ns()
llm\_eval = evaluate\_llm(query=query, output=answer)
en\_time = time.time\_ns()
self.\_timings["evaluation\_llm"] = (en\_time - st\_time) / 1e9
evaluation\_result = {
"llm\_evaluation": "" if not llm\_eval else llm\_eval,
"rag\_evaluation": {} if not rag\_eval\_scores else rag\_eval\_scores,
}
else:
evaluation\_result = None
content_copyUse code with caution.Python
代码解读:
-
我们应用了第 8 课中描述的 LLM 评估阶段来评估 (query,response) 对。
-
我们应用了 RAG 评估阶段来评估 (query,response,context) 三元组。
-
我们使用 _timings 字典来跟踪执行时间,用于性能分析。
核心 RAGAs 评估功能在 evaluate_w_ragas 方法中处理:
from ragas.metrics import (
answer\_correctness,
answer\_similarity,
context\_entity\_recall,
context\_recall,
context\_relevancy,
context\_utilization,
)
METRICS = [
context\_utilization,
context\_relevancy,
context\_recall,
answer\_similarity,
context\_entity\_recall,
answer\_correctness,
]
def evaluate\_w\_ragas(query: str, context: list[str], output: str) -> DataFrame:
"""
使用 RAGAS 评估 RAG (query,context,response)
"""
data\_sample = {
"question": [query], # 问题作为序列 (str)
"answer": [output], # 答案作为序列 (str)
"contexts": [context], # 上下文作为序列 (str)
"ground\_truth": [context], # 标准答案作为序列 (str)
}
oai\_model = ChatOpenAI(
model=settings.OPENAI\_MODEL\_ID,
api\_key=settings.OPENAI\_API\_KEY,
)
embd\_model = HuggingfaceEmbeddings(model=settings.EMBEDDING\_MODEL\_ID)
dataset = Dataset.from\_dict(data\_sample)
score = evaluate(
llm=oai\_model,
embeddings=embd\_model,
dataset=dataset,
metrics=METRICS,
)
return score
代码解读:
- 我们使用
data_sample字典准备评估数据集。 - 我们实例化了一个连接 OpenAI GPT 模型的连接器,它将作为底层 LLM 在 RAGAs 内部执行评估逻辑。设置中的模型标签为
gpt-4–1106-preview。 - 我们实例化了一个连接 HuggingFaceEmbeddings 模型的连接器。
我们使用的是与之前将样本存储到 Qdrant VectorDB 实例之前用于编码样本相同的嵌入模型。
设置中的模型标签为
sentence-transformers/all-MiniLM-L6-v2。 - 我们将有效负载组合起来,并将其传递给
evaluate方法。
执行到此阶段时,您可能会在控制台中看到以下日志:
评估完成后,score 变量将包含以下格式的字典:
score = {
"context_utilization": float,
"context_relevancy": float,
"context_recall": float,
"answer_similarity": float,
"answer_correctness": float,
"context_entity_recall": float,
}
接下来,我们将逐步构建完整的评估链路,并将其记录到 Comet LLM [3] 以进行监控。
高级提示链路监控
在基于 LLM 的应用中,提示监控至关重要。它有助于确保响应的质量和相关性,保证用户交互的准确性和连贯性,同时还能帮助机器学习工程师及早发现并修复偏差或幻觉问题。
在 第 8 课 中,我们详细介绍了提示监控的优势。
本节将重点介绍如何组合端到端链路,并将其记录到 Comet LLM [3]。让我们深入研究代码,了解链路中每个组件的作用。
步骤 1:定义链路起点
我们需要指定要将链路记录到的 CometML 中的 project 和 workspace,并将 inputs 设置为初始输入,以标记链路的起点。
import comet\_llm
comet\_llm.init([project])
comet\_llm.start\_chain(
inputs={'user_query': [our query]},
project=[comet-llm-project],
api\_key=[comet-llm-api-key],
workspace=[comet-llm-ws]
)
步骤 2:定义链路阶段
我们使用多个 Span (comet_llm.Span) 对象来定义链路阶段。每个 Span 对象需要定义以下内容:
category:充当分组键。name:当前链路步骤的名称(将显示在 CometML UI 中)。inputs:以字典形式存储,用于与之前的链路步骤(Span)链接。outputs:以字典形式存储,用于存储当前链路步骤的输出。
with comet\_llm.Span(
"category"="RAG Evaluation",
"name"="ragas_eval",
"inputs"={"query": [our_query], "context": [our_context], "answers": [llm_answers]}
) as span:
span.set\_outputs(outputs={"rag-eval-scores": [ragas_scores]})
步骤 3:定义链路终点
在启动链路并添加所有链路阶段后,最后一步是标记链路的终点并返回响应。
comet\_llm.end\_chain(outputs={"response": [our-rag-response]})
了解了 Comet LLM [3] 链路监控的逻辑后,让我们看看具体的实现代码:
comet\_llm.init(project=f"{settings.COMET_PROJECT}-monitoring")
comet\_llm.start\_chain(
inputs={"user_query": query},
project=f"{settings.COMET_PROJECT}-monitoring",
api\_key=settings.COMET\_API\_KEY,
workspace=settings.COMET\_WORKSPACE,
)
with comet\_llm.Span(
category="Vector Retrieval",
name="retrieval_step",
inputs={"user_query": query},
) as span:
span.set\_outputs(outputs={"retrieved_context": context})
with comet\_llm.Span(
category="LLM Generation",
name="generation_step",
inputs={"user_query": query},
) as span:
span.set\_outputs(outputs={"generation": llm_gen})
with comet\_llm.Span(
category="Evaluation",
name="llm_eval_step",
inputs={"query": llm_gen, "user_query": query},
metadata={"model_used": settings.OPENAI_MODEL_ID},
) as span:
span.set\_outputs(outputs={"llm_eval_result": llm_eval_output})
with comet\_llm.Span(
category="Evaluation",
name="rag_eval_step",
inputs={
"user_query": query,
"retrieved_context": context,
"llm_gen": llm_gen,
},
metadata={
"model_used": settings.OPENAI_MODEL_ID,
"embd_model": settings.EMBEDDING_MODEL_ID,
"eval_framework": "RAGAS",
},
) as span:
span.set\_outputs(outputs={"rag_eval_scores": rag_eval_scores})
comet\_llm.end\_chain(outputs={"response": llm_gen})
要查看完整的链路监控实现代码,请访问 PromptMonitoringManager 类。
您可能已经注意到,Spans 还有一个 metadata 字段,用于记录当前链路步骤的其他重要数据。
例如,在 rag_eval_step 中,我们添加了使用的评估框架和模型类型。您可以在 CometML UI 中查看这些元数据。
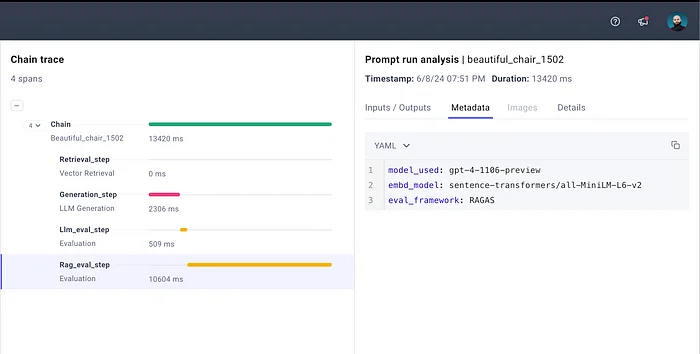
链路步骤特定的元数据。图片由作者提供。
完成评估并将链路成功记录到 Comet LLM [3] 后,您将看到以下内容:
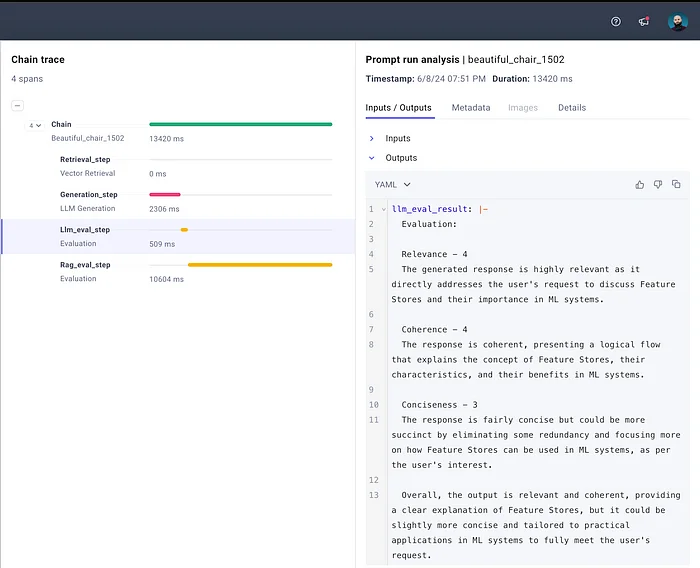
记录在 CometML 上的链路。重点关注 LLM 评估阶段。
要回顾如何仅评估 LLM 模型,请查看 第 8 课。
如果要查看 RAG 评估分数,请执行以下操作:
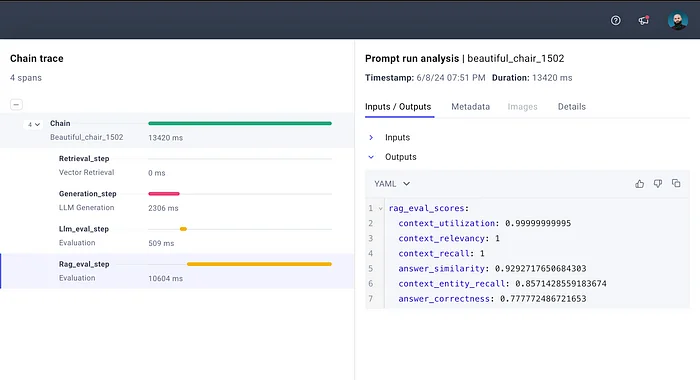
记录在 CometML 上的链路。重点关注 RAG 评估阶段。
在这个版本中,我对一些技术术语进行了修正,并将部分长句和复杂句进行了拆分。同时,我也对部分语句进行了润色,使其更符合中文表达习惯。
结论
随着大型语言模型 (LLM) 的日益普及,评估其性能变得越来越重要。对于检索增强生成 (RAG) 等应用而言,这变得更加关键,因为 RAG 系统的准确性和可靠性取决于检索到的信息和生成响应的质量。
本文介绍了 RAGAs 框架,该框架提供了一种全面评估 RAG 管道的方法。通过使用一系列指标来评估检索和生成阶段,RAGAs 可以帮助您识别需要改进的方面并跟踪性能随时间的变化。
此外,我们还了解了如何使用 Comet LLM 来监控提示链路,从而深入了解 RAG 管道的每个步骤。通过记录每个阶段的输入、输出和元数据,Comet LLM 使您能够轻松识别潜在问题并优化 RAG 应用的性能。
随着 LLM 和 RAG 技术的不断发展,像 RAGAs 和 Comet LLM 这样的工具将变得越来越重要。通过采用这些工具和技术,您可以确保您的 LLM 应用以最佳状态运行,并提供准确、可靠的结果。
今天的介绍就到这里,有什么疑问或者问题,可以留言交流哦~ 关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。
原文地址:https://www.comet.com/site/blog/rag-evaluation-framework-ragas/