5分钟阅读
年度最强图片到3D的AI生成技术

前言
3D 一直是 AI 技术待攻克的领域,图片到 3D 模型生成,开源的和闭源的技术都有。但之前的结果都是差强人意,主要是模型的精度和贴图精度都不够高。最近,微软终于出手了,开源了 3D 模型生成技术-TRELLIS,可能大家都已经了解过了,今天我后知后觉得也整理一下,看过的朋友权当回顾一下。
项目简介

技术总结就是 :
一种新颖且通用的高质量 3D 资产生成方法。其核心在于一个名为 结构化潜在表示 (Structured LATent representation, SLAT) 的统一表示,它可以解码成多种不同的输出格式,包括神经辐射场 (Radiance Fields) 、3D 高斯 (3D Gaussians) 和网格 (meshes) 。
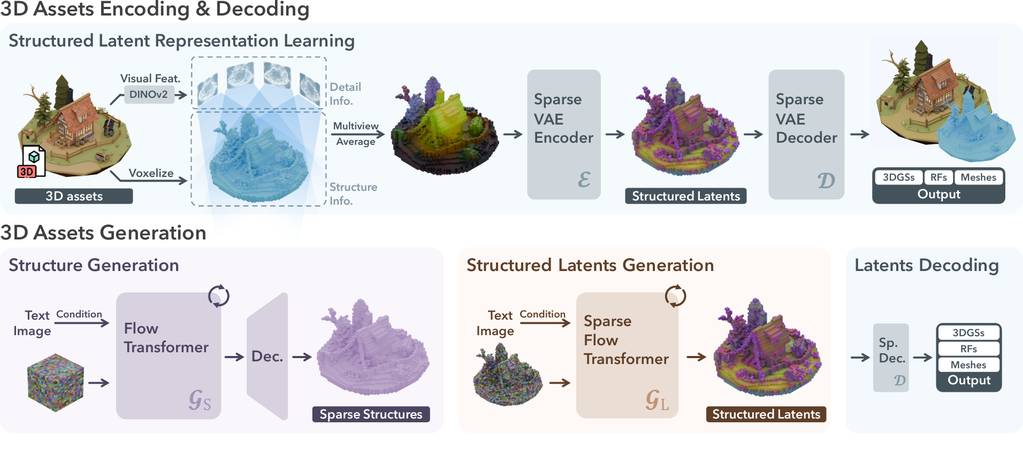
大白话就是 (可能不太准🥱):
我们用乐高来类比:
1. 编码过程 (Encoding): 从乐高模型到“乐高密码”
- DINOv2(像一个非常细心的观察员) : 想象一下,这个观察员会从各个角度仔细观察你的乐高模型 (多视角),并拍下很多照片。他特别擅长识别不同乐高积木的种类和颜色,就像他能看穿积木的本质 (特征提取)。
- 体素化(像把模型拆分成小方块) : 想象一下,我们把复杂的乐高模型拆分成一个个更小的、统一规格的小立方体 (体素)。这样,复杂的模型就变成了一个由小方块组成的 3D 网格,更容易分析。
- 多视角平均(像把多张照片合成一张) : 观察员从不同角度拍了很多照片,我们需要把这些照片的信息综合起来,得到一个对每个小方块最全面的描述。就像把多张照片重叠起来,看得更清楚。
- 稀疏变分自编码器 (VAE)(像一个聪明的密码学家) : 这位密码学家很厉害,他能把这些关于小方块的信息 (颜色、位置、种类) 压缩成一个简短的、只有他自己能懂的“乐高密码” (潜变量)。
- 稀疏性: 这意味着这个密码非常高效,它只记录最重要的信息,就像用最少的词语描述一个乐高积木。
- 变分: 这意味着这个密码学家还有一些“创造力”,他可以根据这个密码稍微做一些改动,创造出一些相似但不完全一样的乐高模型。
- 自编码器: 这意味着这位密码学家既能创造密码 (编码),也能解读密码 (解码),把密码还原成原来的乐高信息。
2. 解码过程 (Decoding): 从“乐高密码”到乐高模型
- 结构生成 (像搭骨架的建筑师) : 这位建筑师会根据你的文字描述或图片,先用一些关键的“乐高密码”搭出一个大致的框架,就像你先用一些核心积木拼出一个房子的地基和主要结构。这个框架虽然简单,但已经确定了模型的大致形状和布局。
- 结构化潜变量生成 (像精细装修的室内设计师) : 这位室内设计师会根据用户更详细的描述,在“乐高密码”上添加更多细节。比如,用户说“我想要一个红色的屋顶”,设计师就会把代表红色屋顶的“密码”加到框架的对应位置。这就像在房子里装修房间,添加家具和装饰品,让整个模型更加丰富和具体。
- 潜变量解码 (像拥有超能力的建造者) : 最后,这位拥有超能力的建造者根据最终的、详细的“乐高密码”(包含了骨架和所有细节),就能“嗖”的一下变出一个完整的 3D 乐高模型。更厉害的是,通过稍微调整“乐高密码”,他还能创造出多个类似的、但细节略有不同的模型供你选择!
这个过程就像一个团队合作:
- 细心观察员 (DINOv2) 负责观察和分析乐高模型。
- 拆解专家 (体素化) 把模型拆解成小方块。
- 信息整合员 (多视角平均) 整合所有信息。
- 聪明的密码学家 (VAE) 创造和解读 “乐高密码”。
- 建筑师 (结构生成) 搭建初始框架。
- 室内设计师 (结构化潜变量生成) 添加细节。
- 超能力建造者 (潜变量解码) 最终生成 3D 模型。
通过这样的比喻,它巧妙地结合了“观察”、“拆解”、“编码”、“解码”、“搭建框架”和“添加细节”等多个步骤,最终实现了从现实物体或文字/图片描述到 3D 模型的转换。
这样是不是好懂一些?
如果难懂就不要懂了,作为设计师,知道其效果一流就可以了😂。

我看看看官方的效果:

随便找几个官方案例看看:



无论从模型的准确性、精细度、贴图的还原程度,都绝对是开源模型的 NO 1 了🐂🍺
如何使用?
官方抱脸地址
Huggingface 在线体验地址 https://huggingface.co/spaces/JeffreyXiang/TRELLIS,需要等候排队,页面加载也好慢🥱。
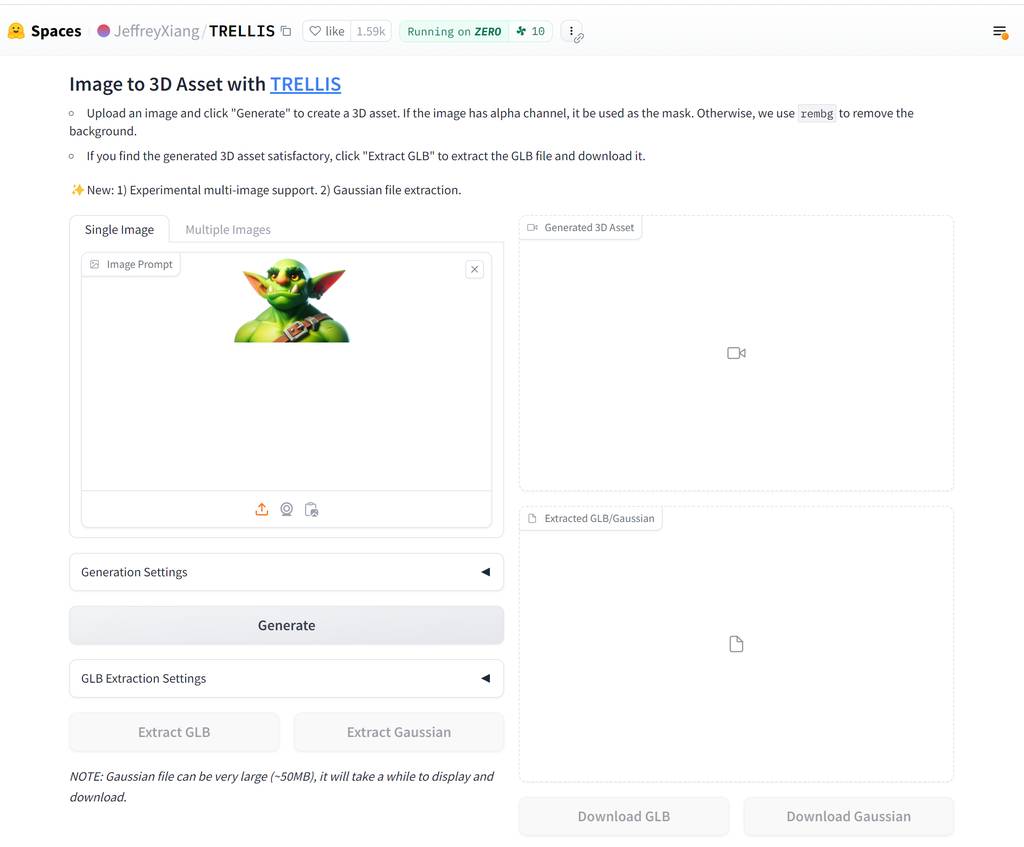
自部署
官方也详细提供了安装指引,有技术和有硬件的伙伴(显存需要 16 G 以上)可以动手试试。
📦 安装
先决条件
- 系统: 目前代码仅在 Linux 系统上进行了测试。对于 Windows 系统的设置,您可以参考 #3 (尚未完全测试)。
- 硬件: 需要至少具有 16 GB 显存的 NVIDIA GPU。代码已在 NVIDIA A 100 和 A 6000 GPU 上进行了验证。
- 软件:
- 编译某些子模块需要 CUDA Toolkit。代码已在 CUDA 11.8 和 12.2 版本上进行了测试。
- 建议使用 Conda 管理依赖项。
- 需要 Python 3.8 或更高版本。
安装步骤
-
克隆仓库:
git clone --recurse-submodules https://github.com/microsoft/TRELLIS.git cd TRELLIS -
安装依赖项:
在运行以下命令之前,需要注意以下几点:
- 添加
--new-env标志将创建一个名为trellis的新 conda 环境。如果您想使用现有的 conda 环境,请删除此标志。 - 默认情况下,
trellis环境将使用 PyTorch 2.4.0 和 CUDA 11.8。如果您想使用不同版本的 CUDA (例如,如果您安装了 CUDA Toolkit 12.2 并且不想为子模块编译安装另一个 11.8 版本),您可以删除--new-env标志并手动安装所需的依赖项。请参考 PyTorch 获取安装命令。 - 如果您安装了多个 CUDA Toolkit 版本,在运行命令之前应将
PATH设置为正确的版本。例如,如果您安装了 CUDA Toolkit 11.8 和 12.2,则应在运行命令之前运行export PATH=/usr/local/cuda-11.8/bin:$PATH。 - 默认情况下,代码使用
flash-attn后端进行注意力计算。对于不支持flash-attn的 GPU (例如 NVIDIA V 100),您可以删除--flash-attn标志仅安装xformers,并在运行代码之前将ATTN_BACKEND环境变量设置为xformers。有关更多详细信息,请参见最小示例 。 - 由于依赖项较多,安装过程可能需要一段时间。请耐心等待。如果您遇到任何问题,可以尝试逐个安装依赖项,每次指定一个标志。
- 如果在安装过程中遇到任何问题,请随时提出 issue 或联系我们。
创建一个名为
trellis的新 conda 环境并安装依赖项:. ./setup.sh --new-env --basic --xformers --flash-attn --diffoctreerast --spconv --mipgaussian --kaolin --nvdiffrastsetup.sh的详细用法可以通过运行. ./setup.sh --help查看。Usage: setup.sh [OPTIONS] Options: -h, --help Display this help message --new-env Create a new conda environment --basic Install basic dependencies --xformers Install xformers --flash-attn Install flash-attn --diffoctreerast Install diffoctreerast --vox2seq Install vox2seq --spconv Install spconv --mipgaussian Install mip-splatting --kaolin Install kaolin --nvdiffrast Install nvdiffrast --demo Install all dependencies for demo - 添加
🤖 预训练模型
我们提供以下预训练模型:
| 模型 | 描述 | 参数量 | 下载 |
|---|---|---|---|
| TRELLIS-image-large | 大型图像到 3 D 模型 | 1.2 B | 下载 |
| TRELLIS-text-base | 基础文本到 3 D 模型 | 342 M | 即将推出 |
| TRELLIS-text-large | 大型文本到 3 D 模型 | 1.1 B | 即将推出 |
| TRELLIS-text-xlarge | 超大型文本到 3 D 模型 | 2.0 B | 即将推出 |
这些模型托管在 Hugging Face 上。您可以在代码中使用它们的仓库名称直接加载模型:
TrellisImageTo3DPipeline.from_pretrained("JeffreyXiang/TRELLIS-image-large")
如果您更喜欢从本地加载模型,您可以从上面的链接下载模型文件并使用文件夹路径加载模型 (应保持文件夹结构):
TrellisImageTo3DPipeline.from_pretrained("/path/to/TRELLIS-image-large")
我的测试
我代大家测试一下,我是在 wsl 2 中部署的,流程跟官方的来,也挺顺利的。
安装
先运行 steup. Sh

我是用 conda 原来的环境安装,所以需要单独安装一下 pytorch:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
还需要装一下 gradio
pip install gradio==4.44.1 gradio_litmodel3d==0.0.1
运行:
python app.py
开始下载模型了,激动😂

效果
用一个小女孩先试试,原图:

结果出来了,还是挺经验的!
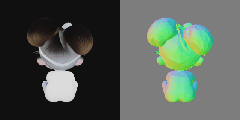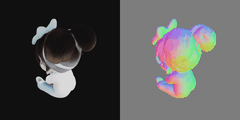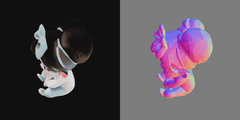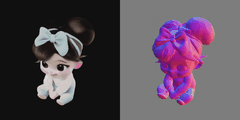
导入 blender 面也挺合理的。


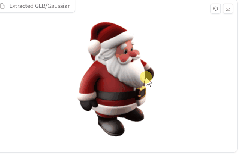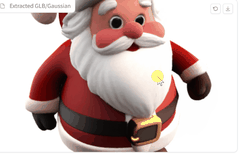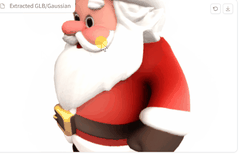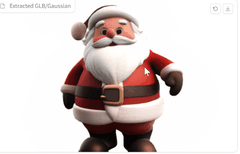
再来个圣诞老人。

效果也不错啊~
更多 AI 辅助设计和设计灵感趋势,请关注公众号(设计小站):sjxz 00。