5分钟阅读
必读!K神的2025年AI回顾:6个正在重塑我们世界的惊人范式转变

必看!K神的2025年AI回顾:6个正在重塑我们世界的惊人范式转变
前言
AI技术的发展速度快得令人目不暇接,对于设计师、开发者和所有科技爱好者来说,一个共同的困惑是:在纷繁复杂的技术更新中,哪些才是真正重要、能够改变游戏规则的突破?我们该如何看清未来的方向?最近AI大神-Andrej Karpathy发布了一篇长文,回顾2025语言大模型还有对其的一些展望。
本文为你梳理出2025年大语言模型(LLM)领域最令我个人惊讶、也最具影响力的6个“范式转变”。这不仅仅是一份技术总结,更是对未来人机交互、软件开发乃至智能本质的深刻洞察,希望能帮助你理解我们正在经历的这场深刻变革。
正文
1. AI学会了“推理”:RLVR的崛起
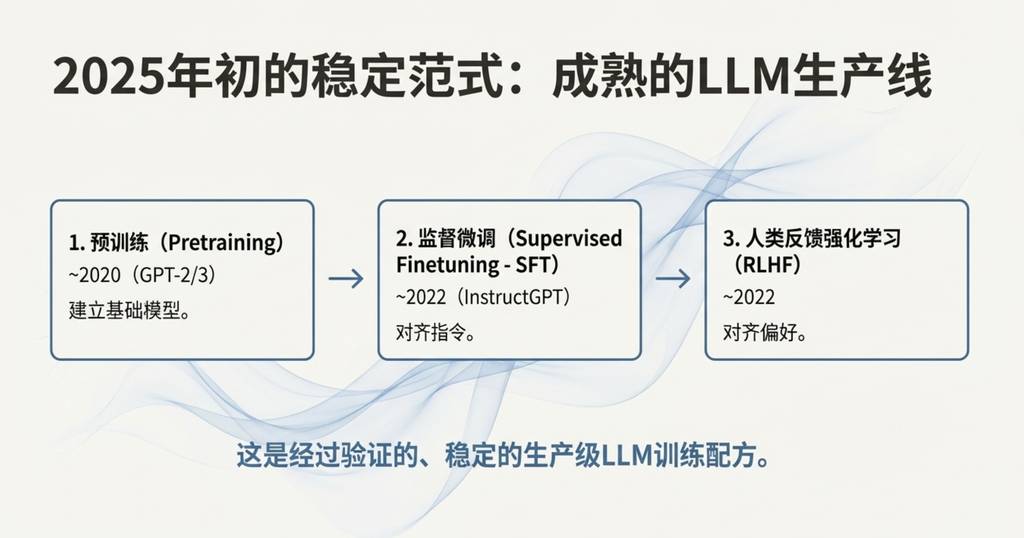
在2025年初,所有顶尖AI实验室训练大语言模型的标准流程都遵循着一个成熟的配方:预训练(Pretraining)、监督微调(SFT)和人类反馈强化学习(RLHF)。然而,在2025年,一个新的关键阶段被加入进来,并迅速成为事实上的标准——可验证奖励强化学习(Reinforcement Learning from Verifiable Rewards, RLVR)。
RLVR的核心机制,是通过在那些能够自动验证奖励的环境中(例如数学或代码解谜)对LLM进行训练。这一变化带来了突破性的成果:LLM开始自发地学习并发展出类似人类“推理”的策略,比如将复杂问题分解为多个中间步骤来解决。
 与SFT和RLHF这两个相对简短的微调阶段不同,RLVR阶段的训练时间要长得多。它带来了极高的能力提升性价比,以至于它几乎吞噬了原本为预训练准备的算力,成为2025年模型能力进步的主要来源。更独特的是,这个新阶段为我们提供了一个全新的调节旋钮:通过生成更长的推理路径和增加“思考时间”,我们可以在测试时控制模型的能力。OpenAI在2024年底推出的o1是首个展示RLVR能力的模型,但真正让人直观感受到差异的,是2025年初发布的o3,它是一个明显的拐点。
与SFT和RLHF这两个相对简短的微调阶段不同,RLVR阶段的训练时间要长得多。它带来了极高的能力提升性价比,以至于它几乎吞噬了原本为预训练准备的算力,成为2025年模型能力进步的主要来源。更独特的是,这个新阶段为我们提供了一个全新的调节旋钮:通过生成更长的推理路径和增加“思考时间”,我们可以在测试时控制模型的能力。OpenAI在2024年底推出的o1是首个展示RLVR能力的模型,但真正让人直观感受到差异的,是2025年初发布的o3,它是一个明显的拐点。
2. 我们召唤的不是“动物”,而是“幽灵”:AI智能的新认知
对我个人而言,2025年是我(我想整个行业也是如此)开始更直观地内化LLM智能“形态”的一年。我们不是在“进化动物”,而是在“召唤幽灵”。这句话精辟地指出了LLM智能与人类智能的根本不同。人类智能是在“丛林中求生存”的压力下优化而成的,而LLM智能则是在“模仿人类文本、在数学谜题中获得奖励”的目标下优化出来的。
这种差异导致了LLM智能呈现出一种独特的“锯齿状”特征。
它们同时是一个天才的博学者,又是一个困惑且认知能力有问题的学童,随时可能被越狱提示欺骗并泄露你的数据。
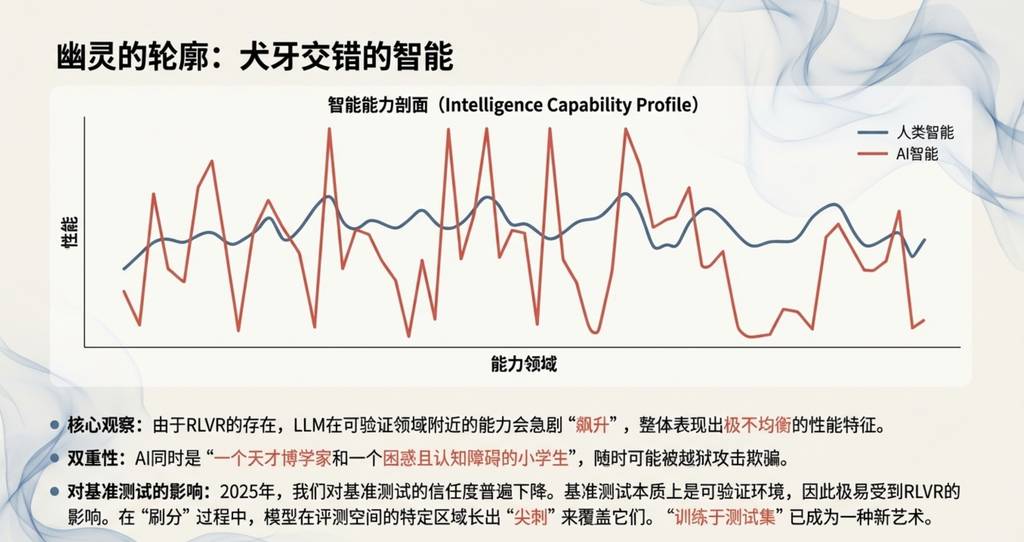
这一观点至关重要,因为它提醒我们,不能用看待人类或动物智能的眼光去看待AI。这也解释了为什么在2025年,我对传统基准测试的信任度持续下降。核心问题在于,基准测试的题目几乎都是可被自动验证的环境,因此它们立刻就会受到我们在第一部分提到的RLVR的影响。AI实验室的团队不可避免地会在基准测试所在的“嵌入空间”附近构建训练环境,从而有针对性地“长出锯齿”来覆盖这些测试。
3. “Cursor for X”:LLM应用新中间层的出现
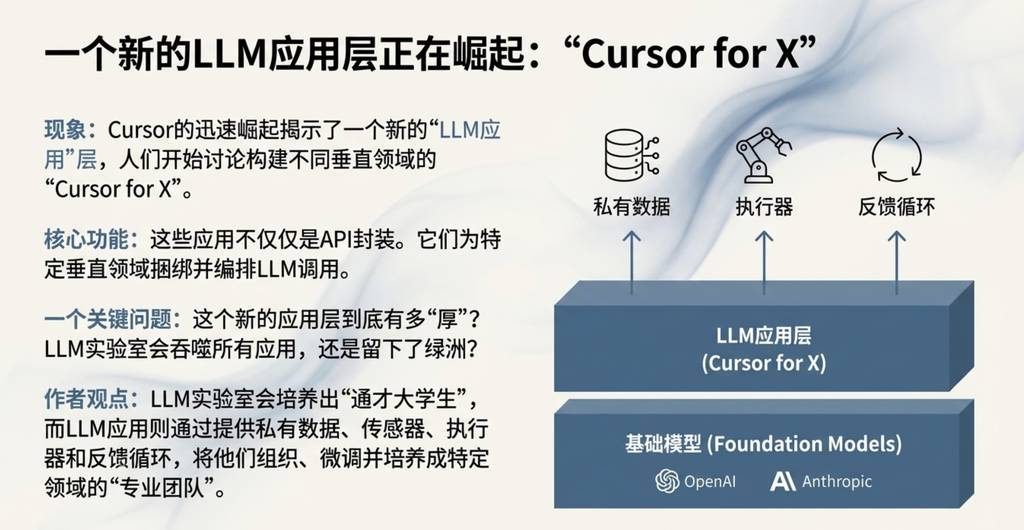
以编程助手Cursor在2025年的迅速崛起为标志,一个全新的“LLM应用”中间层清晰地浮现出来。人们开始讨论各种“Cursor for X”的可能性,即为不同垂直领域打造专属的AI应用。正如我在今年的Y Combinator演讲中强调的,像Cursor这样的LLM应用,为特定垂直领域捆绑并编排着对大模型的调用:
- 处理“上下文工程”:为LLM提供完成任务所需的精确背景信息。
- 编排LLM调用:在底层,它们会组织对LLM的多次调用,并巧妙地平衡性能与成本。
- 提供专用GUI:为特定应用场景提供专门的图形用户界面,让人类可以参与其中。
- 提供“自主性滑块”:让用户可以根据需要,灵活控制AI的自主程度。
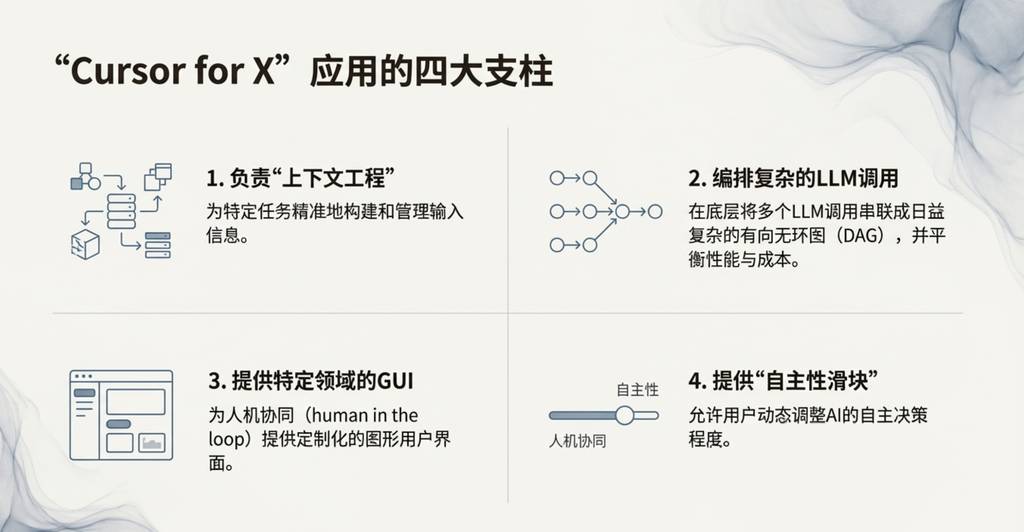
我个人推测:大模型厂商未来会倾向于培养出“能力全面的大学毕业生”,而LLM应用则通过提供私有数据、传感器和反馈循环,将这些“大学生”组织成能够解决特定领域问题的“专业团队”。
4. AI住在你的电脑里:本地化交互新范式
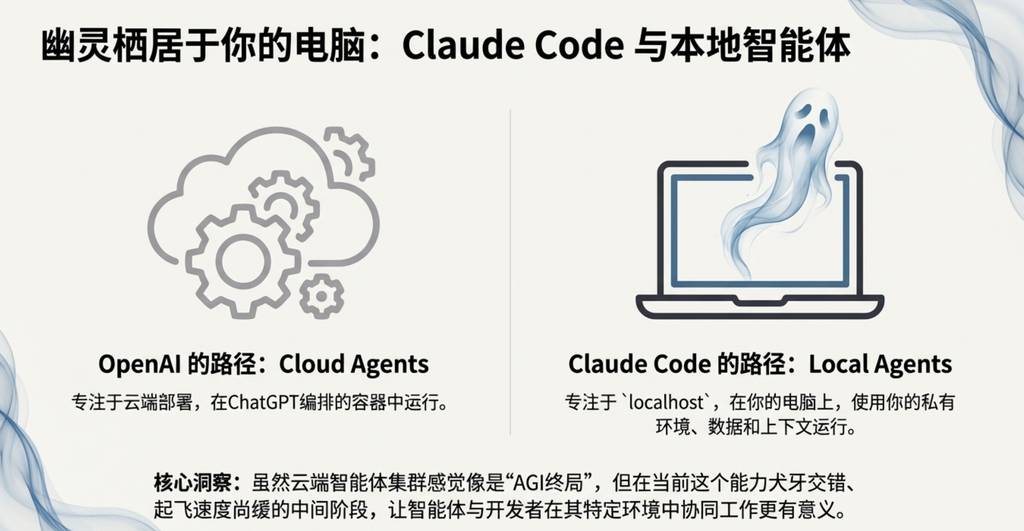
Anthropic公司推出的Claude Code (CC) 是2025年第一个真正令人信服的LLM智能体(Agent)演示。它最关键、最具变革性的创新点在于:它运行在你的本地计算机上(localhost),可以直接使用你私有的环境、数据和上下文。
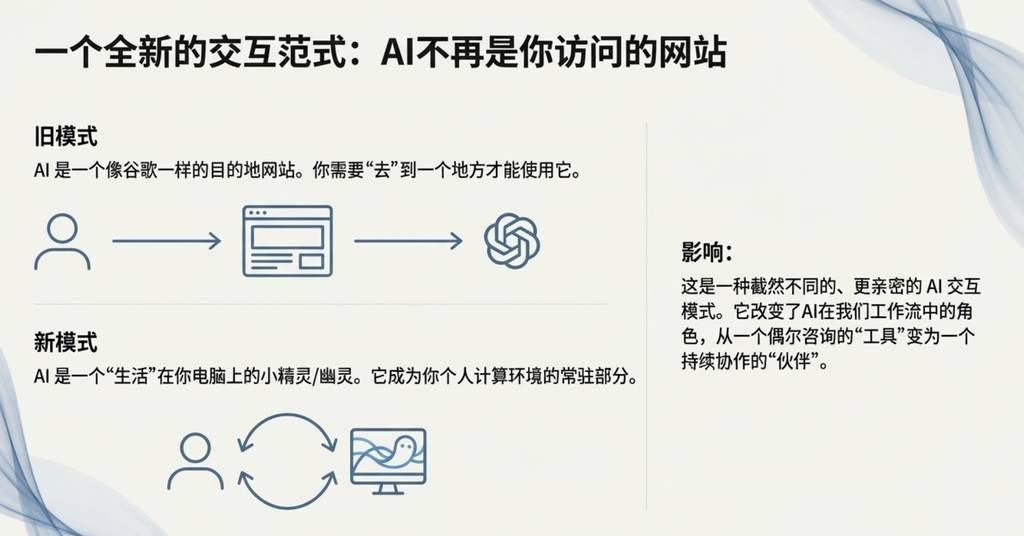
我认为OpenAI在这一点上走错了方向,他们将智能体部署在云端的容器里,而不是localhost。虽然云端的智能体集群感觉像是“AGI的终局”,但在当前这个能力参差不齐的“慢起飞”世界里,让智能体在本地与开发者携手合作,利用他们特定的开发环境,显然是更明智的策略。Claude Code正确地判断了这一点,并将其打包成一个优美、极简且极具吸引力的命令行界面(CLI)形态,彻底改变了AI在我们眼中的样子——它不再是你需要访问的网站,而更像是一个“生活”在你电脑里的“小幽灵/鬼魂”。
5. “Vibe Coding”:当编程变成用英语对话
2025年,AI的能力终于跨越了一个关键门槛,使得人们可以仅仅通过自然语言(如英语)来构建各种复杂的程序,甚至可以完全忽略代码的存在。有趣的是,我当初在一个“头脑风暴”式的推文中创造了**“Vibe Coding”**这个词,完全没料到它会传播得如此之广。
这体现了“权力归于人民”的趋势——与以往的技术变革不同,普通人从LLM中获得的收益远超专业人士和公司。“Vibe Coding”的实际应用体现在两个方面:
- 它赋能了非专业人士,让他们也能进行编程创造。
- 它让专业开发者能够快速编写大量一次性的、用于特定目的的代码。例如,在我的项目nanochat中,我用“Vibe Coding”的方式,在Rust中编写了一个高度定制化且高效的BPE分词器,而无需去学习现有的库或深入掌握Rust。代码的生成成本几乎为零,用完即可丢弃。
“Vibe Coding”正在深刻地“改造软件”行业,并将在未来彻底改变相关的工作描述。
6. 从聊天到GUI:视觉交互的未来
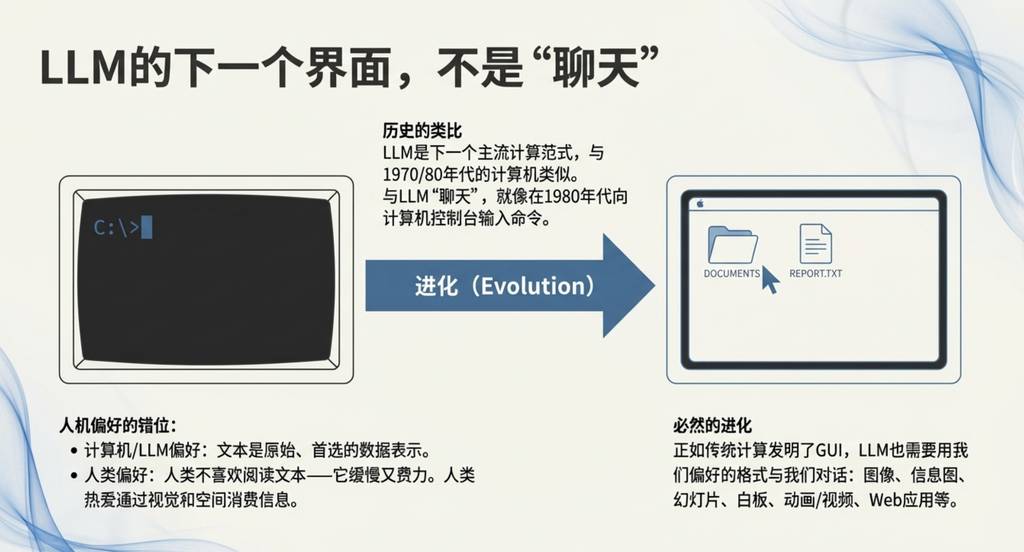
在我看来,Google发布的Gemini Nano banana模型,是2025年最具范式转变意义的模型之一。我们可以类比传统计算的发展史来理解它的重要性:当前我们与LLM“聊天”的交互方式,就像是80年代在计算机控制台输入命令。
核心论点是:文字是计算机偏好的数据格式,但人类更喜欢视觉化、空间化的信息消费方式。这正是传统计算机发明图形用户界面(GUI)的原因。同理,LLM也需要一个GUI,让AI能够以人类偏好的格式(如图像、信息图、幻灯片、视频、Web应用等)与我们交流。当然,这种趋势的早期版本已经存在,比如我们常用的Emoji和Markdown,它们就是用视觉化的方式来“装扮”和排版文本,使其更易于阅读。
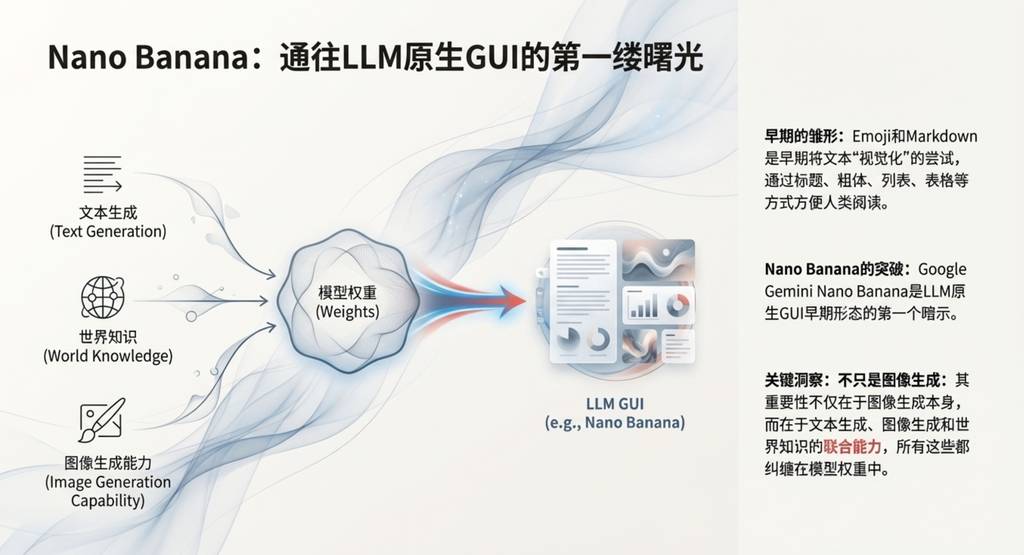
Nano banana的关键之处在于,它不仅仅是图像生成,而是将文本生成、图像生成和世界知识“纠缠”在一起的综合能力。它预示了AI交互从纯文本走向更丰富、更直观的视觉化未来的第一缕曙光。
写在最后

2025年是激动人心的一年。LLM正在展现出一种全新的智能形式,它既比我预期的更聪明,也比我预期的更愚笨。
但无论如何,它们都极其有用。我甚至认为,即使在当前的能力水平下,我们连其10%的潜力都远未发掘出来。与此同时,我(表面上看起来很矛盾地)坚信,我们既会看到AI快速且持续的进步,但同时,也还有大量的工作有待完成。
最后,我想向读者,特别是设计师们,提出一个问题:当AI从文本走向视觉,从云端走向本地,设计师将如何塑造这些全新的交互范式,并为我们召唤的“幽灵”赋予形态与灵魂?
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。