5分钟阅读
记一次图标风格LoRA训练
前言
AIGC时代,除了算力,模型已然成为了生产力要素。试想一下,假如你拥有一个自己想要的大模型或者LoRA模型,就可以把想要的风格、画面元素(人物特征、事物特征)都固定下来,然后通过文生图、图生图等方式,快速复制,大大提升生产力。 现在也涌现出模型训练师,或者叫模型设计师,还有相关职位的招聘呢~😂。 关于LoRA训练,B站已经有很多大神的教程,也讲得很详细,本文只是记录一下过程,当然在某些环节,我加入了自己的方法,且过程当中有踩过的坑,与各位共勉。
看看效果
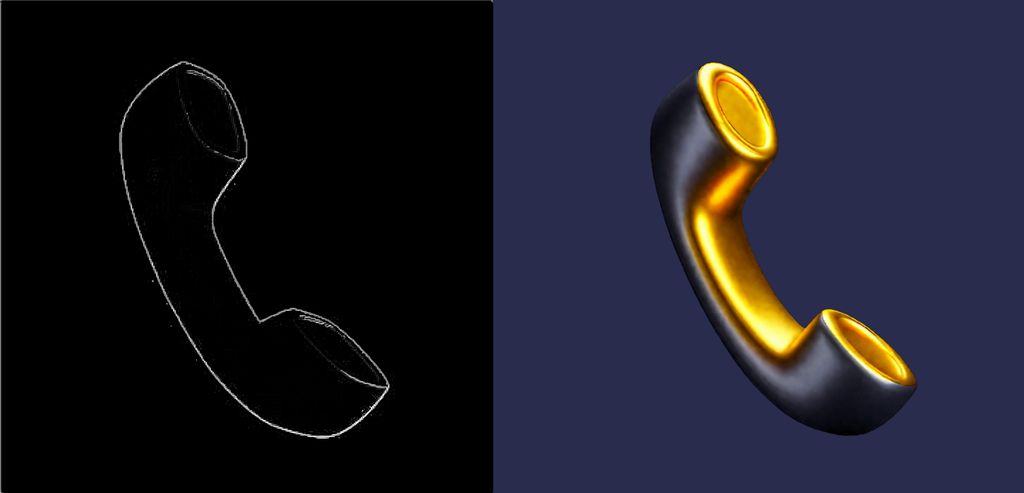
文生图
提示语:
solo,goldenicon,<图标名称>,gradient color,black background,45-degree angle

图生图
其实就是通过Controlnet控制,按需求出图。其实大部分场景应该就是这样使用,通过绘制图标线稿,生成相应的风格图标。






训练概述
今天的目标是训练一个图标风格的LoRA。我把训练的过程和用到的工具,列了张流程图。
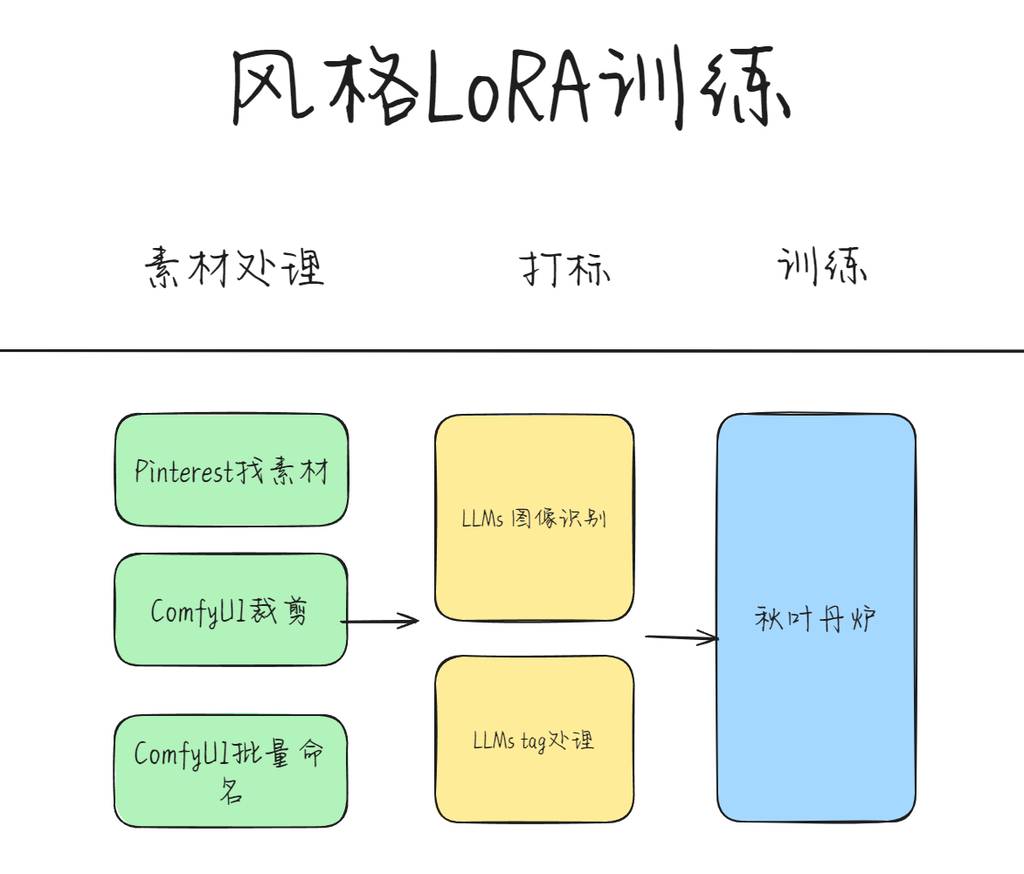
我是结合了多个工具的,其中主要是打标处理。如果使用WD 1.4 标签器,反推的tag有时候会不太好,所以我用ComfyUI搭了个工作流,利用在线的语言大模型进行打标,准确性更高。
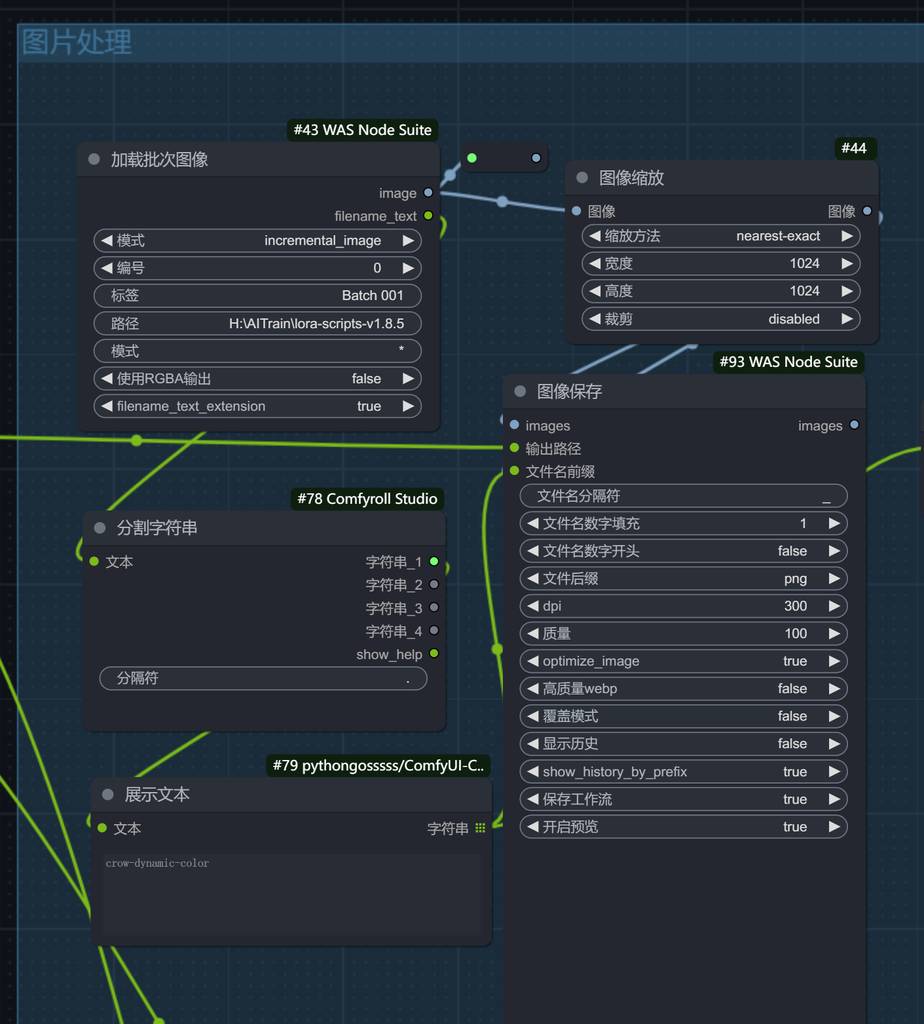
图片处理
图片处理模块,我也是使用ComfyUI的工作流,这次比较简单,只是缩放了一下尺寸,如果需要检测人脸,然后裁剪,也是可以搭建工作流方式实现的。
打标
如前面所述,我使用了在线的大模型进行批量打标和保存处理,提示词会更精准,当然也更费钱~🤦♂️。
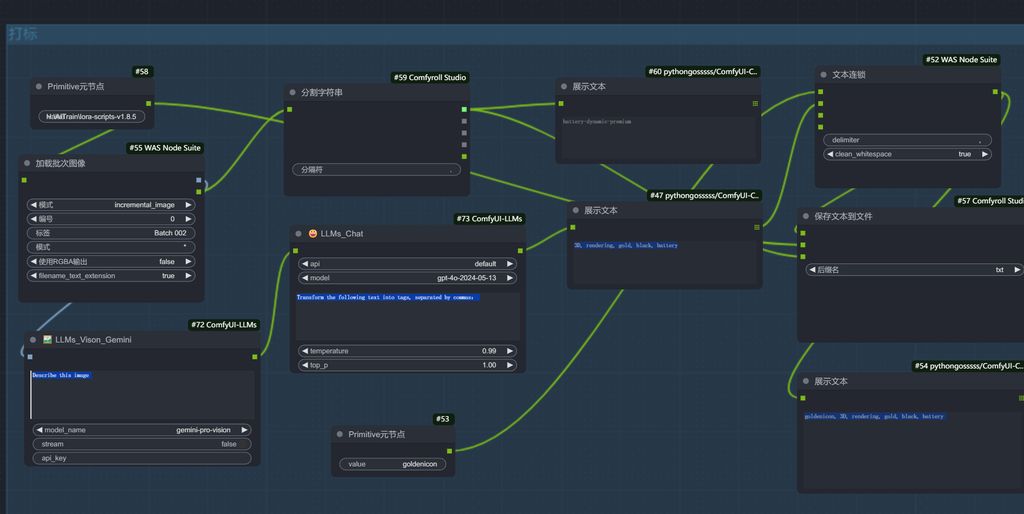
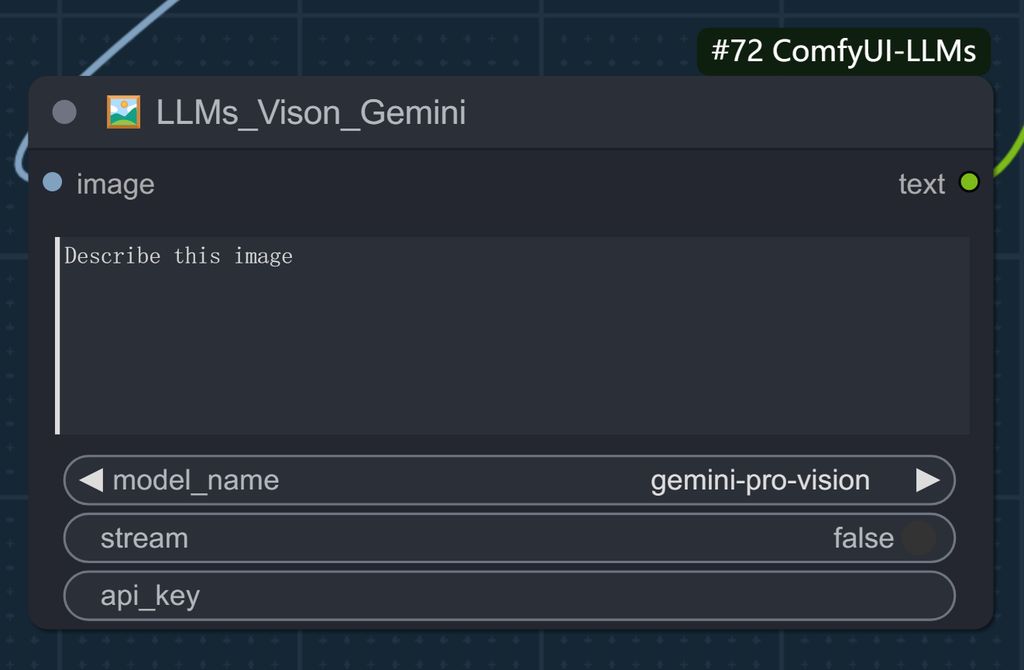
打标第一步
第一步是先让视觉模型识别出画面。
打标第二步
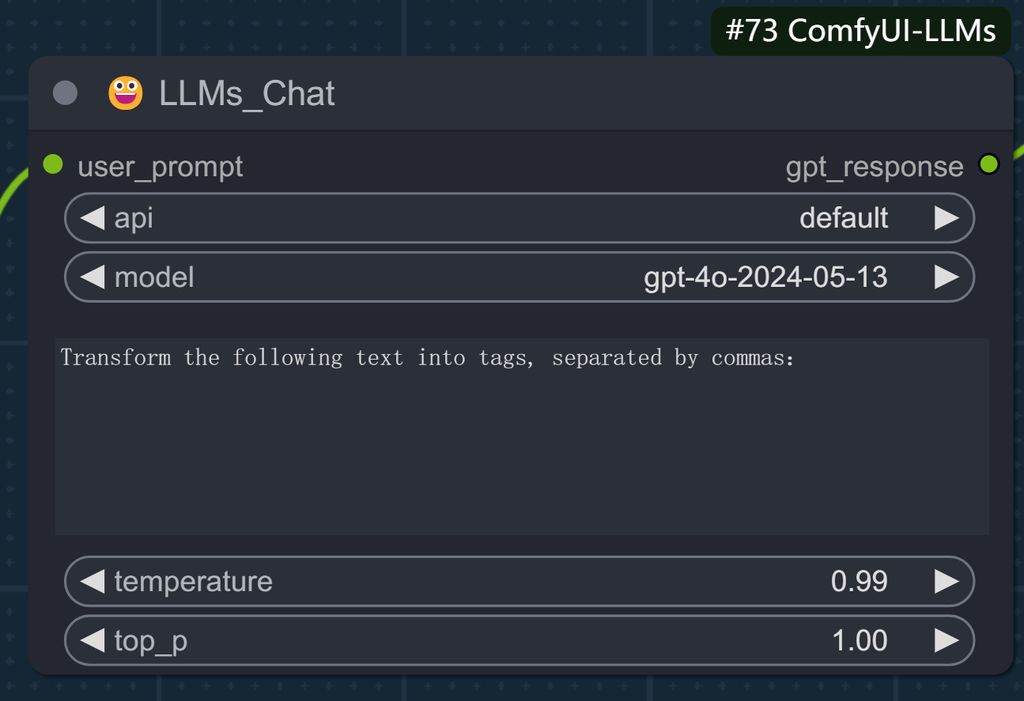
打标的第二步,是根据识别的内容,总结为标签tag。
打标第三步
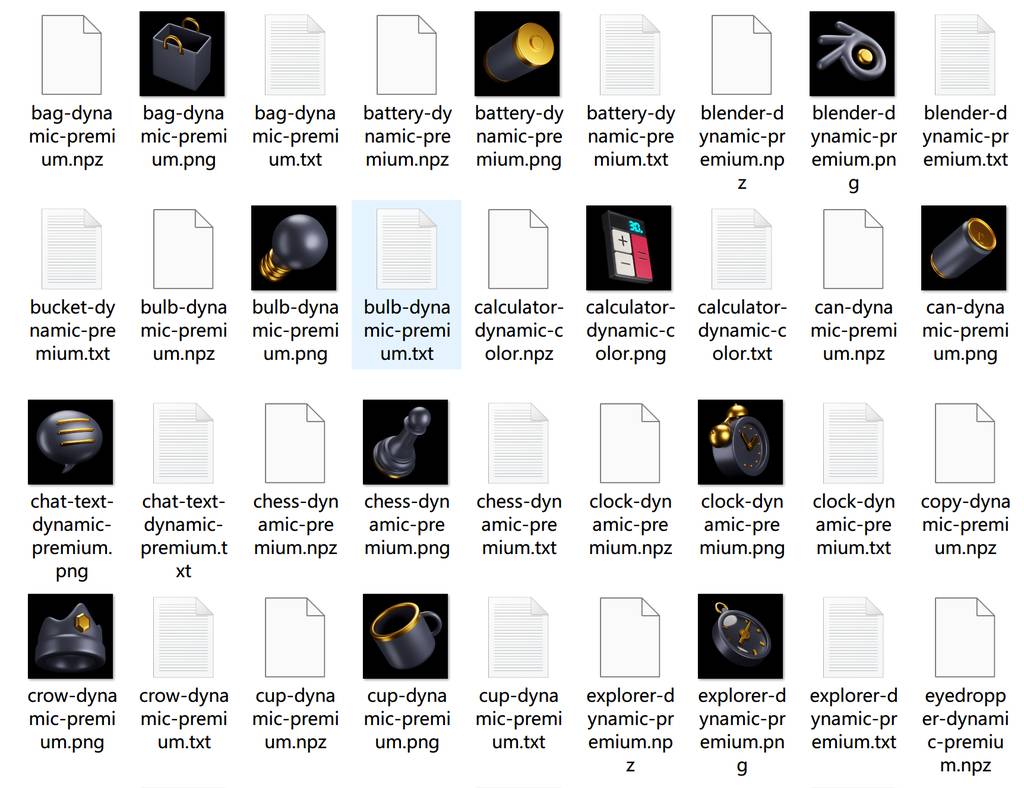
把触发词添加到tag文本中,然后保存,处理后,文件夹应该是这样的。
注意:npz是训练是生成的,忽略哈~
文件结构
处理后的素材,文件结构是这样的:
lora-scripts-v1.8.5
-- train
-- gold3dicon
-- 8_icons
注意最底层的目录8_为标准前缀,表示文件夹内的素材,每张图训练8次,你也可以调高这个数字,例如10,这样会增加整体训练步数。
关于训练步数,公式为:
【每张图训练次数x最大训练epoch(轮数)x 图片张数】/ 批量大小=总训练步数
开始训练
我们使用秋叶的web训练工具。为什么不用ComfyUI的训练节点呢?不知道为啥,我是跑不起来。因为秋叶大佬的训练工具也足够易用和直观,且功能齐全,所以还是觉得用秋叶大佬的工具进行训练。 训练的参数,我并非完全了解,这里只提一下我用到的几个参数。
我直接使用专家模式,新手跟专家其实差别不大,不懂还是不懂🤦♂️,而专家模式有些参数,新手模式没有。
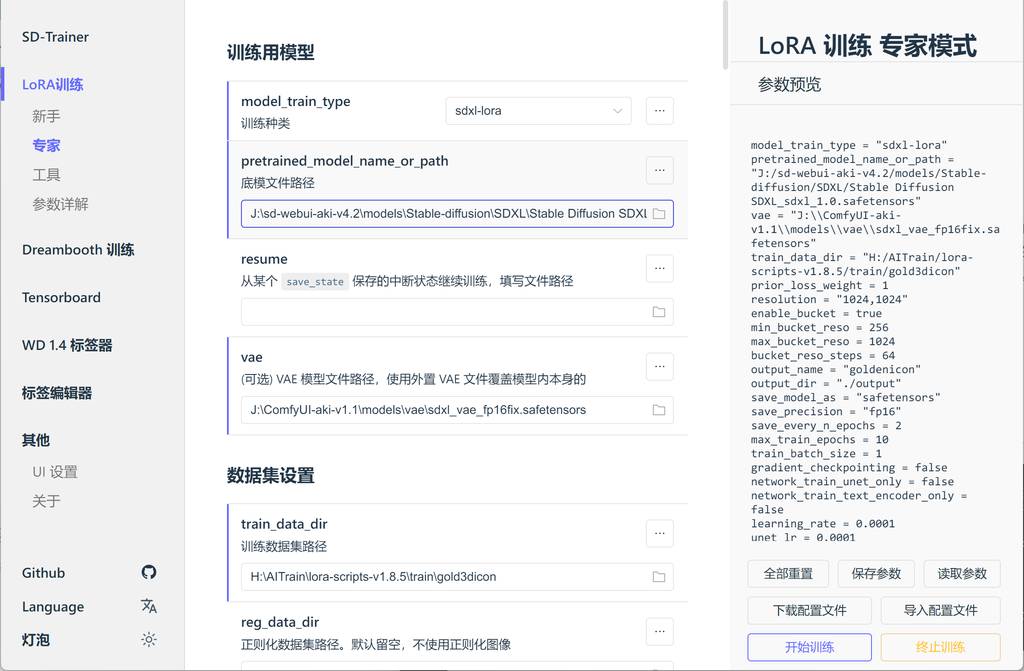
训练种类
SD1.5选sd-lora。SDXL选sdxl-lora。
底模
选择一个底模,我这里训练SDXL LoRA,所以要选择一个SDXL的模型,我直接使用了原生的了。
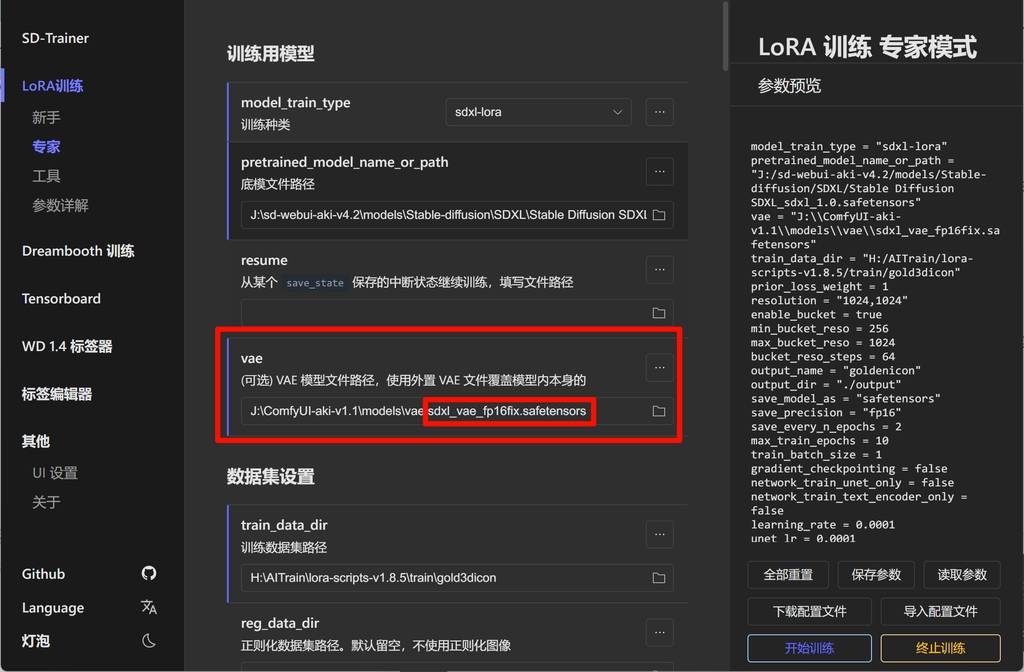
vae
这里要重点提一下,踩了一些坑,这里写的是可选,事实上对于某些底模,这里需要选一个适配的vae,而且是fp16的才行,不然会报错。
数据集
选择上面输出的目录即可。
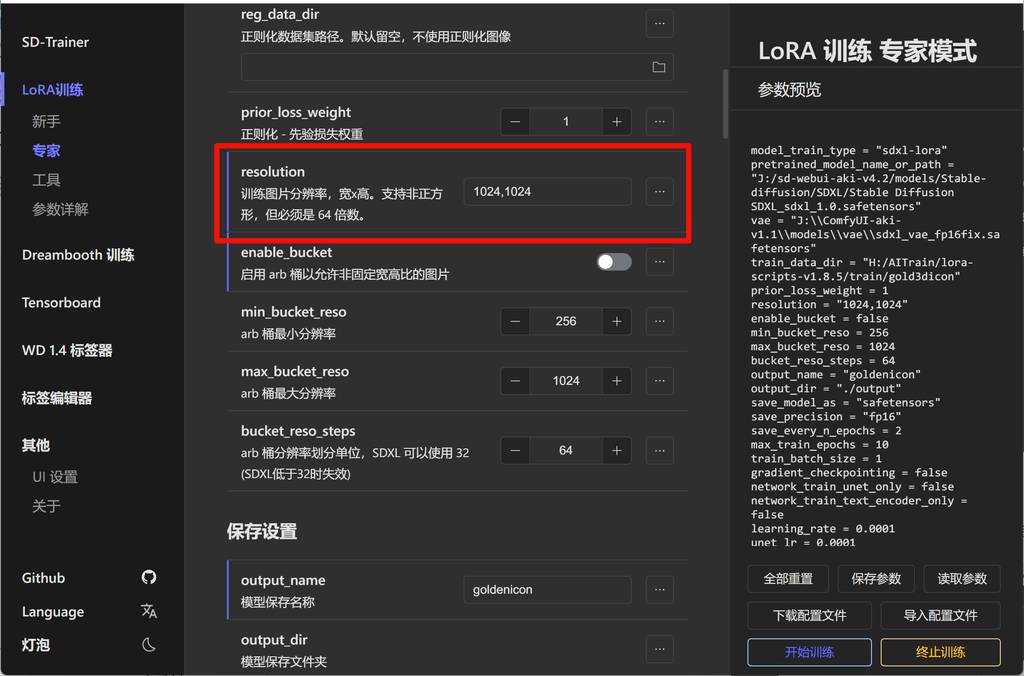
resolution
根据自己的训练集,这里也提示了规范。我的素材是1024x1024
其余参数我就没动了,需要深入训练的话,还可以对学习率这些进行微调和测试。 然后就是训练过程了,漫长的等待,显卡在燃烧~😂
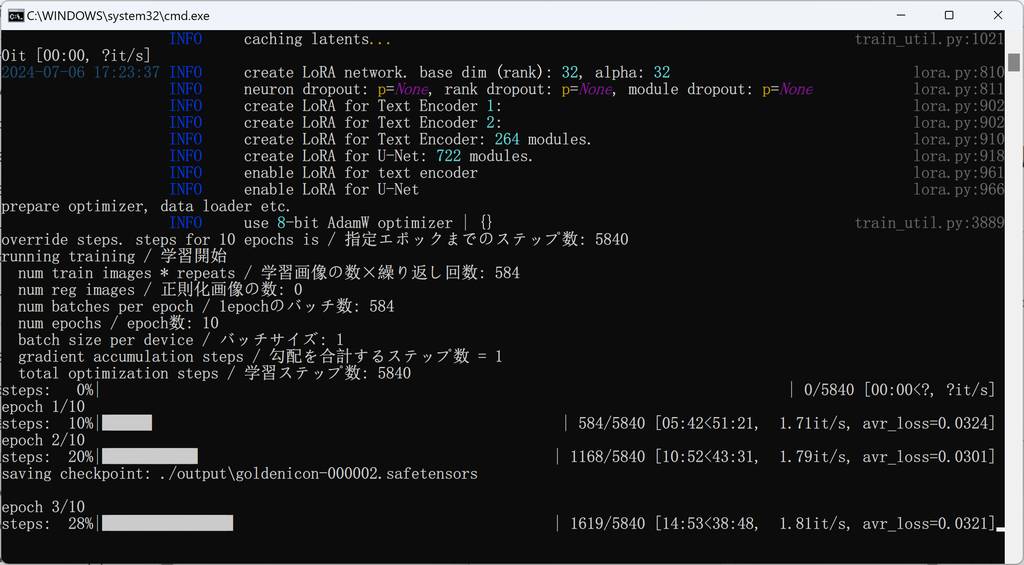
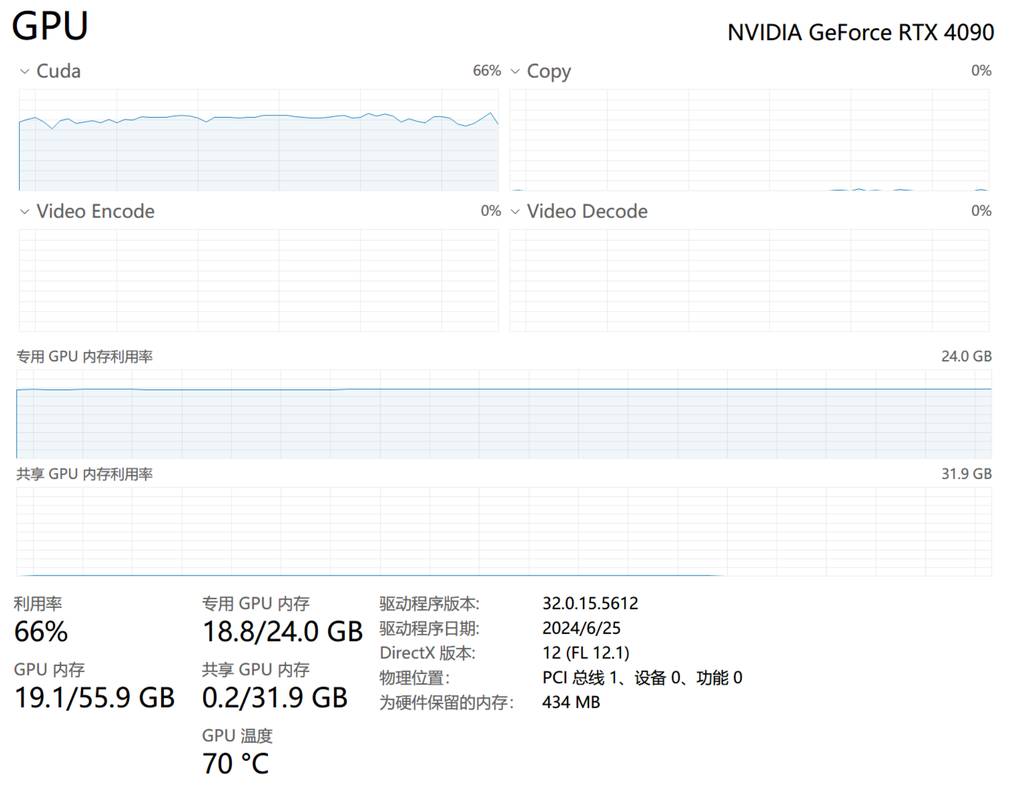
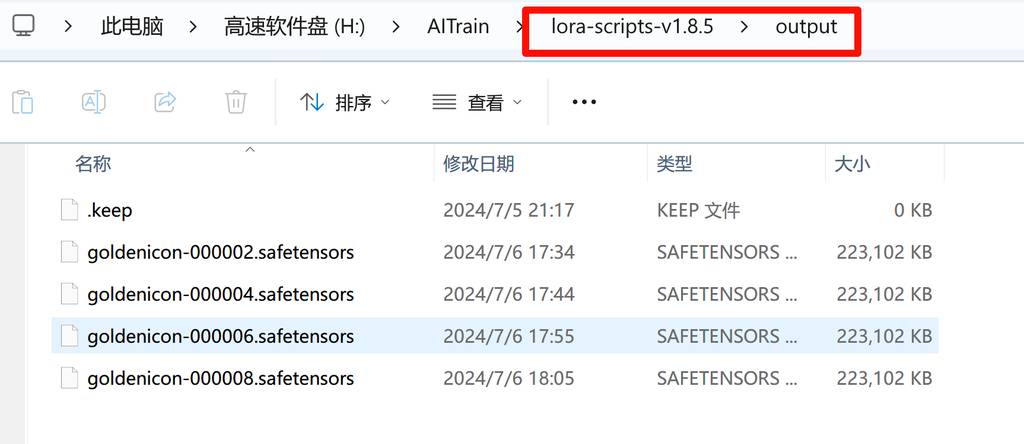
输出的模型会在刚才填写的目标文件中。
测试
需要搭建ComfyUI工作流,生成xy图表,方便测试和评估。我们把生成的LoRA模型,复制到ComfyUI的模型目录中。然后大家工作流,进行文生图评估。
评估工作流
大家可以看图。
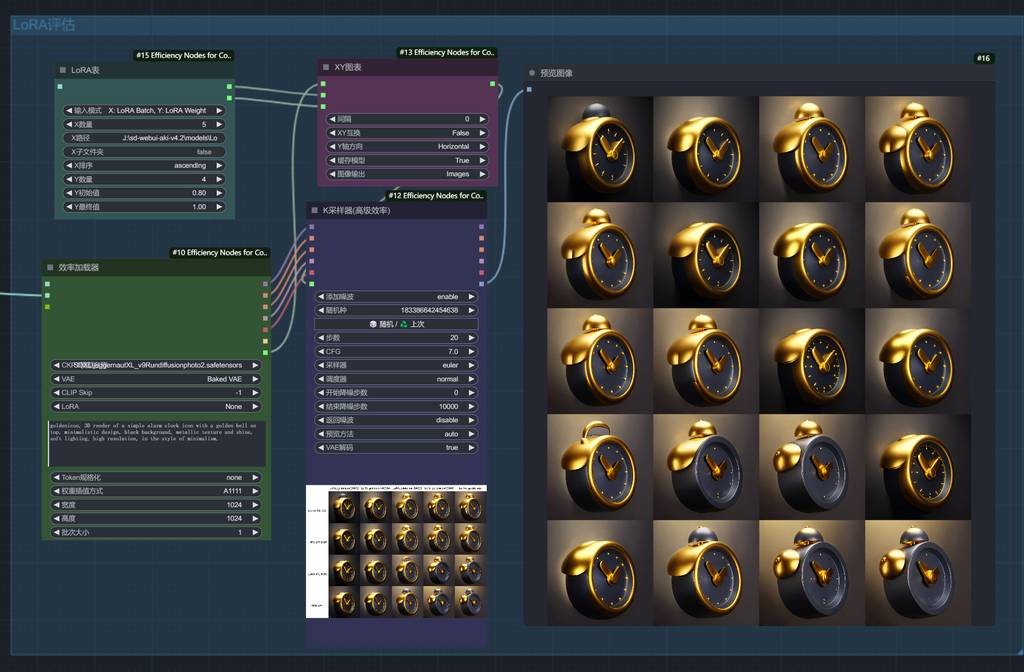
评估效果
从输出的xy图标中,我们可以看到,权重在0.9-1.0之间,名称为goldenicon的LoRA模型拟合程度符合预期(图片右下角位置),可以作为成果去使用了。

这个模型已经上传到,哩布哩布了,感兴趣的设计师可以下载玩玩。
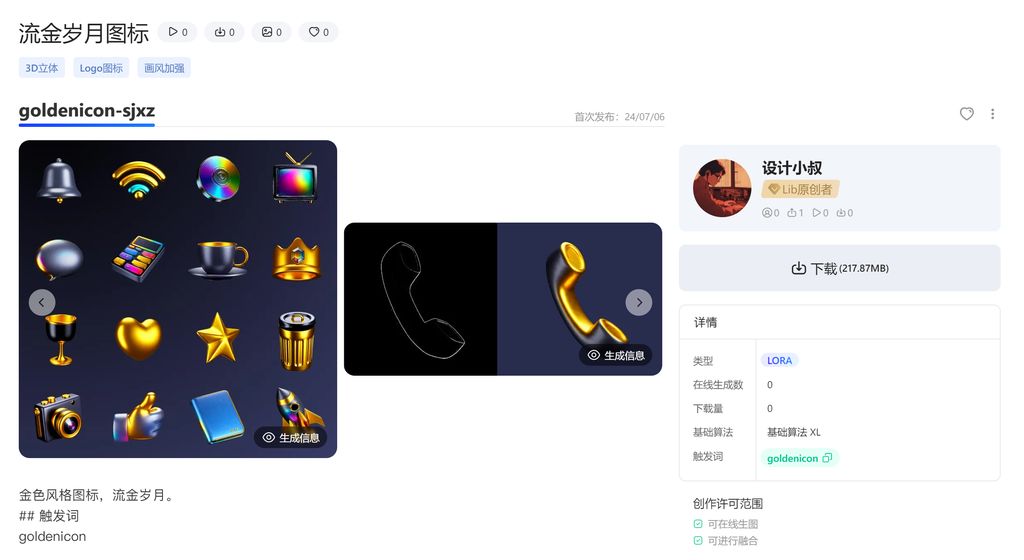
分享介绍就到这里,有什么疑问或者问题,可以留言交流哦~
关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。