5分钟阅读
设计师务必关注!万物迁移再出利器DSD

【AI前沿】设计师务必关注!万物迁移再出利器-DSD
前言
之前我写过几期文章,关于使用 FLUX+Redux 进行万物迁移的,需要一个工作流支持,可以实现。感兴趣的小伙伴可以回顾一下:
- 【AI辅助设计】FLUX.1 Fill+Redux万物迁移之换装
- 【AI辅助设计】FLUX.1 Fill+Redux万物迁移之mockup
- 【AI辅助设计】FLUX.1 Fill+Redux万物迁移之电商出图
- 【AI辅助设计】FLUX.1 Fill+Redux万物迁移之换衣2.0
- 【AI辅助设计】FLUX Fill+Redux万物迁移之内衣模特(技术文!非ca 边)
使用起来,相对比较复杂,拿到工作流的朋友纷纷表示跑不起来(跟设备、环境有关,我本地跑是没问题的😂)。 然鹅,AI 的技术最近有往前一步了!今天为大家介绍一个刚推出的新技术:DSD-diffusion-self-distillation。它可以在不训练 LoRA 的情况下,实现但不仅限于如下功能:
- 角色一致性
- 万物迁移
- 风格迁移 基本上把 FLUX+Redux,以及阿里的 IC-LoRA 那套玩法全覆盖了!
效果
我们看看官方的案例:
角色一致性-Character Preservation
可以把角色主体,放在不同场景和氛围中,保持的非常到位。


万物迁移- Item Preservation
特别适合用于产品设计,电商出图!把产品放在不同的场景中进行渲染和效果表达!这个设计师要重点关注一下啊!🐂🍺



指令提示 - Instruction Prompting
也是属于设计师重点关注的功能!可以按照图片的元素,通过提示语方式,迁移到不同的场景和画面中!



重打光-Relighting
摄影师、设计师重点关注!给照片重打光,iclingt 是不是可以退役了🤔。




漫画生成器- Comic Generation
其实有了角色一致性、万物迁移和重打光,这个漫画生成也就是水到渠成而已😂。




项目介绍
简介
项目中文名称:扩散自蒸馏:零样本定制化图像生成方法 文本到图像扩散模型虽能生成惊艳效果,但对于追求精细化控制的艺术家而言仍显不足。以”身份保持生成”为例(即在全新场景中生成特定实例图像),这类任务本应最适合图文联合条件生成模型。然而,直接训练此类模型面临高质量配对数据匮乏的难题。我们提出扩散自蒸馏方法,利用预训练文本到图像模型自主生成图文条件图像转换任务的训练数据:
- 首先通过文本扩散模型的上下文生成能力创建图像网格,借助视觉语言模型(VLM)筛选海量配对数据集
- 使用该数据集将文本到图像模型微调为文本+图像到图像生成模型
实验表明,扩散自蒸馏在各类身份保持生成任务中不仅超越现有零样本方法,更可与需要逐实例优化的技术相媲美,且无需测试阶段优化。
顺便提一句,底模是基于 FLUX.1-dev 的。
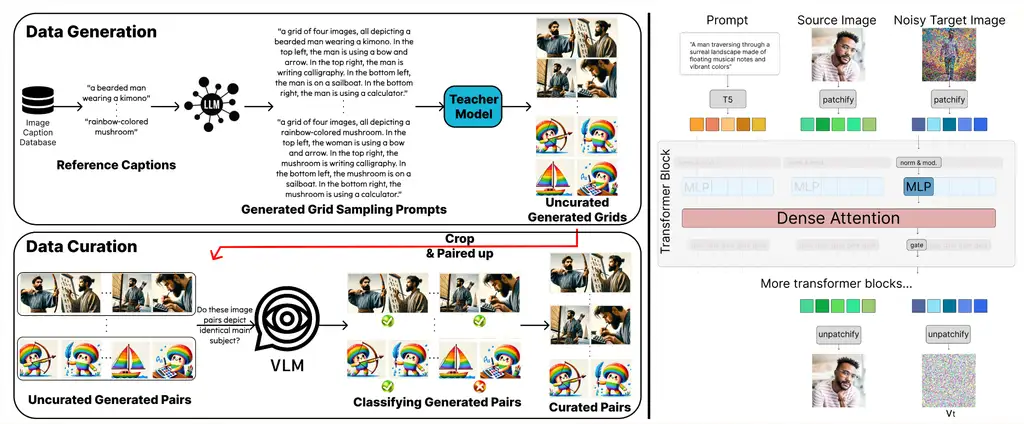
技术原理
左:数据生成与提纯流程
- 顶层(原始配对数据生成) :
① 从LAION数据集采样参考图像描述
② 通过LLM将描述转化为身份保持的网格生成提示
③ 输入预训练扩散模型生成候选图像网格
④ 裁剪组合为原始图像对 - 底层(数据提纯) :
通过VLM自动筛选保留主体一致的图像对,模拟人工标注流程
右:模型架构创新
将扩散Transformer扩展为图像条件框架:
- 将输入图像视为双帧序列的首帧
- 模型同步生成两帧:首帧重建输入,次帧输出编辑结果
- 实现条件图像与目标输出间的有效信息交互
通俗来说,就好比如下:
想象一下,你要教一个学生画画,但你给他的任务是先临摹一些复杂的画作,比如一幅彩虹蘑菇的画。这张画不仅有彩虹蘑菇,还有蘑菇在用弓箭、写书法、划船甚至使用计算器的场景。为了让学生学得更好,你需要先准备好素材、筛选出适合的例子,并用系统的方法教他。下面用生活化的比喻来解释图中的技术原理:
1. 数据生成:像准备画画的任务清单
- 比喻:你有一本“画画任务清单”(图中的“Image Caption Database”),上面写着各种描述,比如“穿和服的胡子男人”或者“彩虹蘑菇”。
- 做法:你把这些描述交给一个“聪明的助手”(LLM,大语言模型),助手会根据描述生成更详细的任务清单,比如“画四个场景:第一个场景是胡子男人拉弓箭,第二个场景是写书法,第三个是划船,第四个是用计算器”。
- 结果:助手帮你生成了一系列任务清单(图中的“Generated Grid Sampling Prompts”),并交给一个“老师”(Teacher Model),老师画出了对应的图片。
2. 数据筛选:像挑选好作品
- 比喻:老师画完后,你发现画的质量参差不齐,有些画得很好,比如胡子男人的四个场景都很清晰;但也有些画得不太好,比如彩虹蘑菇的图中有错误——蘑菇在用计算器那张看起来不太对劲。
- 做法:你需要一个“艺术鉴赏家”(VLM,视觉语言模型),来帮你判断哪些画是合格的,哪些需要淘汰。
- 结果:最后,你留下了一些高质量的画作对,比如“胡子男人的四张图”和“彩虹蘑菇的前三张图”,这些是“精挑细选的好作品”(Curated Pairs)。
3. 学习过程:像教学生看图画故事
- 比喻:接下来,你用这些挑选好的画作对,教学生理解画中的内容。比如,你让学生看一张“胡子男人拉弓箭”的图,并告诉他对应的描述是“胡子男人拉弓箭”。
- 技术细节:这里的“Transformer Block”就像学生的大脑,能逐步理解图片和文字之间的关系。通过不断练习,学生可以从一张图片中学会推理出它的文字描述,或者从文字描述中画出对应的图片。
4. 噪声处理:像修复模糊的画
- 比喻:有时候,学生会遇到一些模糊的画,比如一张涂满杂乱颜色的画(图中“Noisy Target Image”)。你教他通过已有的知识,把模糊的画“修复”成清晰的画。
- 做法:学生会把模糊的画分成小块(“patchify”),然后逐步分析每一块内容,最后组合成一幅完整的清晰画。
整个过程就像是你在教一个学生画画和理解画作:
- 准备任务清单(数据生成)。
- 挑选高质量的作品(数据筛选)。
- 用好作品教学生(模型学习)。
- 教学生修复模糊画作(处理噪声)。
最终,这个学生(AI 模型)就能从文字描述中画出高质量的图片,或者从图片中理解文字描述!
如何使用?
既然如此厉害,我们怎么使用呢?
目前官方发布了模型权重,地址:https://huggingface.co/primecai/dsd_model,也开放了线上的使用:https://huggingface.co/spaces/primecai/diffusion-self-distillation。
如果硬件够,可以拉取代码进行本地部署:https://github.com/primecai/diffusion-self-distillation。
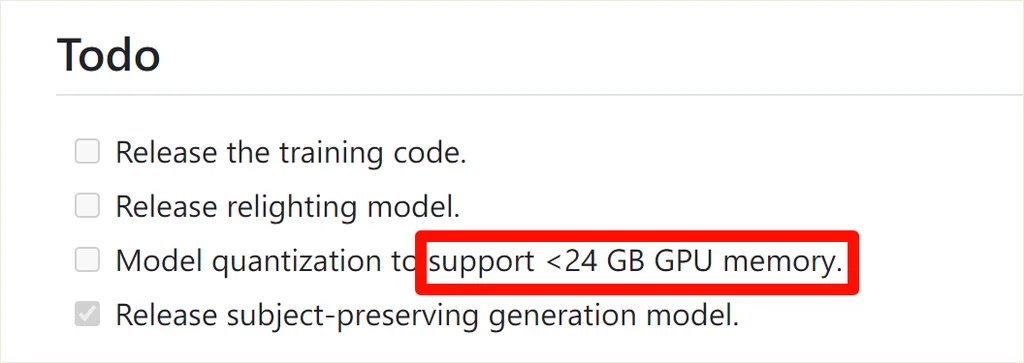
需要提一下,24 G 显存以下的就别想了🥱!官方说明,后面才适配 20 G 显存以下的量化模型。
实测效果
我使用线上的实测一下,几乎也达到了项目介绍中的效果,希望尽快放出更多的量化模型,还有 ComfyUI 插件。
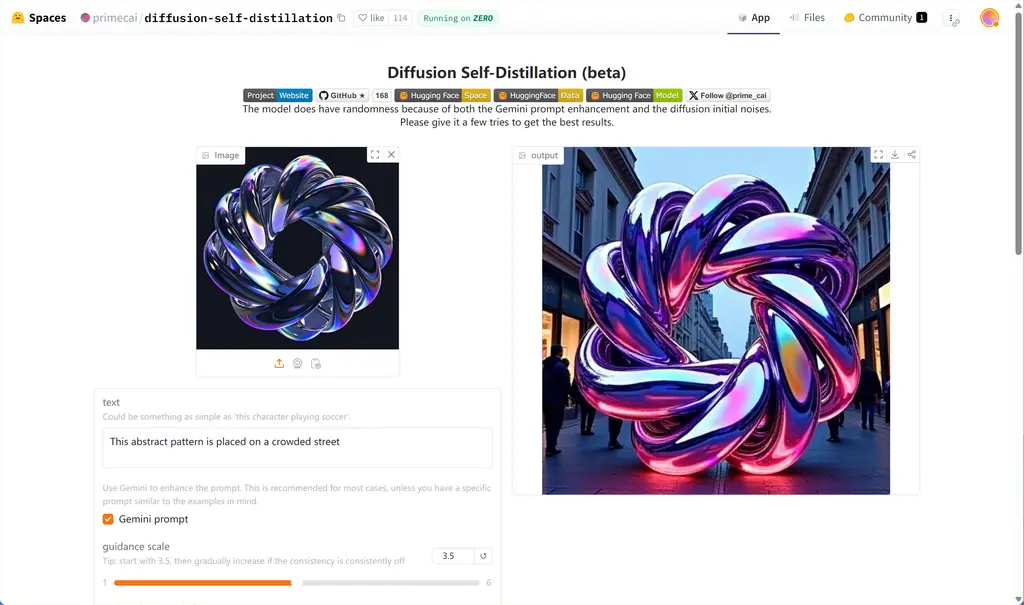
将物体放在街道上
形状保持得很好,就是材质还原度不够🤔。
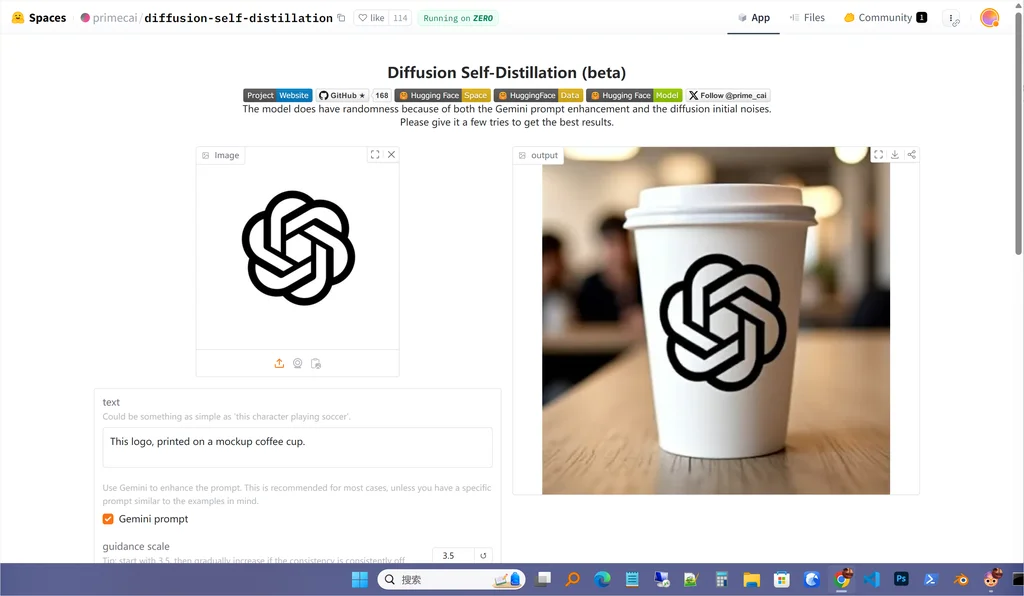
Logo 迁移
可以迁移了,但是大小不知道怎么控制🤔。
其他的还没有试,抱脸上的免费额度用完了~🥱
想获取更多 AI 辅助设计和设计灵感趋势? 欢迎关注我的公众号(设计小站):sjxz 00。