5分钟阅读
超真实肖像!FLUX+SDXL+SD15组合打造
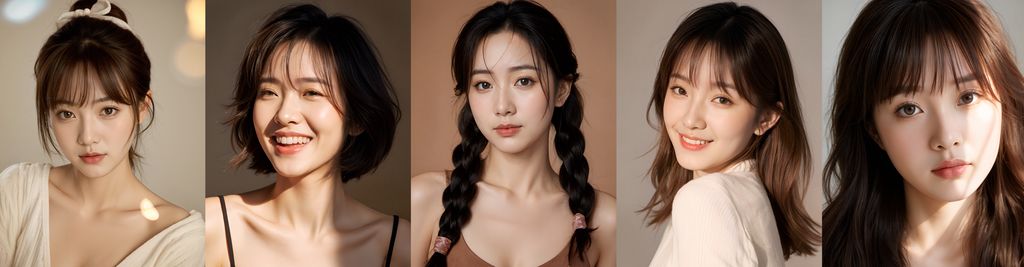
超真实肖像!FLUX+SDXL+SD15组合打造
前言
关于模特,我已经出过几期的文章了。最近有朋友后台私信说关于人物的生成需要再多介绍一下。 那么今天我们就继续探索一下如何用组合模型,打造美女写真。
先看效果
图片可能会被压缩








感觉 AI 味是不是没那么冲了😂
为什么要组合拳?
我们都知道 FLUX 的质量非常棒,但是对于生态的支持还不是很好。这样导致了,后面的放大、细节还原环节,会没那么好处理。
当然,如果有富哥可以搞到 40 G 显存的显卡,使用 flux 直出高分图片,是不是也可以?😂
其原理和模型优势我画一下,便于大家理解,如果有大佬看到,也帮忙指正!
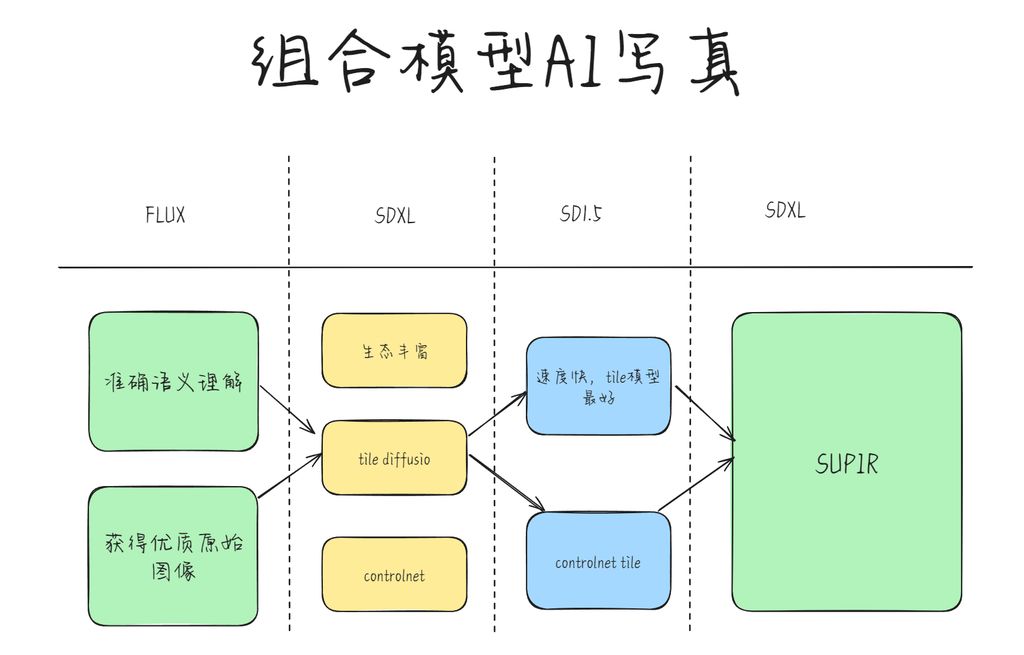
工作流
肖像大师+提示语处理
这次我们还是使用肖像大师节点捏脸。为了让 flux 能更好地识别提示语,加入 llm 处理。
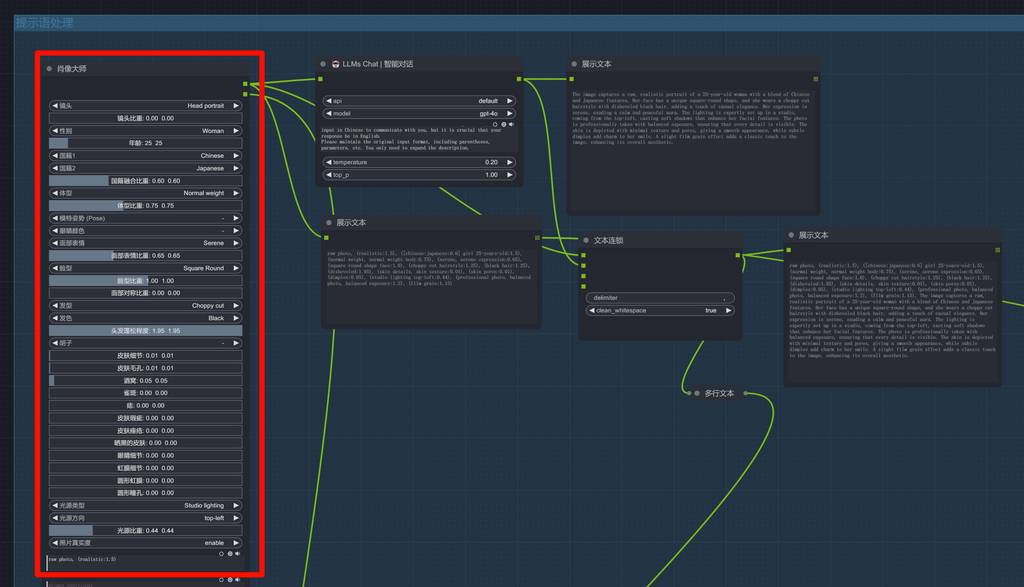
因为肖像大师输出的提示语是这样的格式的:
Raw photo, (realistic: 1.5), ([chinese:japanese: 0.6] girl 25-years-old: 1.5), (normal weight, normal weight body: 0.75), (serene, serene expression: 0.65), (square round shape face: 1.0), (choppy cut hairstyle: 1.25), (black hair: 1.25), (disheveled: 1.95), (skin details, skin texture: 0.01), (skin pores: 0.01), (dimples: 0.05), (studio lighting top-left: 0.44), (professional photo, balanced photo, balanced exposure: 1.2), (film grain: 1.15)
这种格式对于 SDXL 而已,最好需要进行编码,使用 A1111 编码,这块后面会提到。
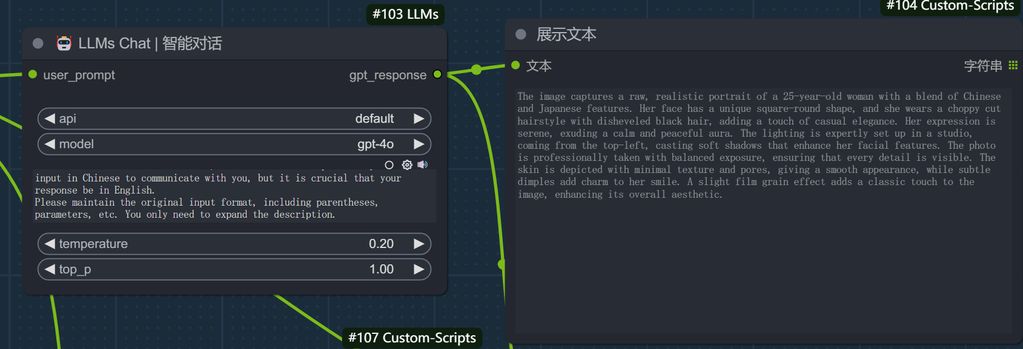
上面的提示语经过 llm 处理后,变成了自然语言,输入到 flux 进行第一次采样。
The image captures a raw, realistic portrait of a 25-year-old woman with a blend of Chinese and Japanese features. Her face has a unique square-round shape, and she wears a choppy cut hairstyle with disheveled black hair, adding a touch of casual elegance. Her expression is serene, exuding a calm and peaceful aura. The lighting is expertly set up in a studio, coming from the top-left, casting soft shadows that enhance her facial features. The photo is professionally taken with balanced exposure, ensuring that every detail is visible. The skin is depicted with minimal texture and pores, giving a smooth appearance, while subtle dimples add charm to her smile. A slight film grain effect adds a classic touch to the image, enhancing its overall aesthetic.
这样处理干净后,让大模型更加好地理解提示语。
Flux gguf 采样
依旧使用 wang 大的 AWportriat 作为 LoRA 串联到 flux gguf 模型中,传入 llm 处理后的提示语。
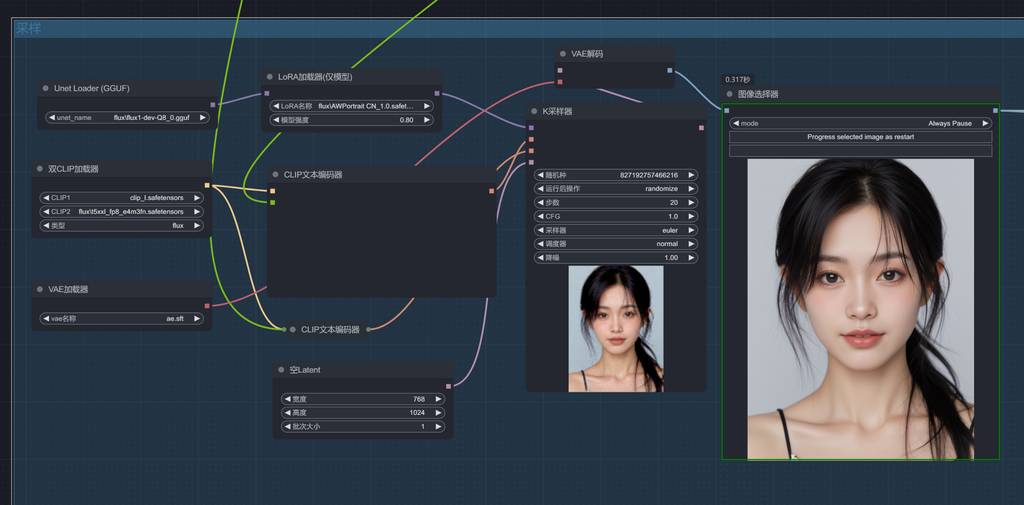
其实出的图,对于普通用途已经够用了,图片的清晰度和人物的真实度已经不错。 但是,AI 味还是有的,细节也不够。 我们接下来进一步加工。

第一次放大处理
这个步骤就是“混合券”。
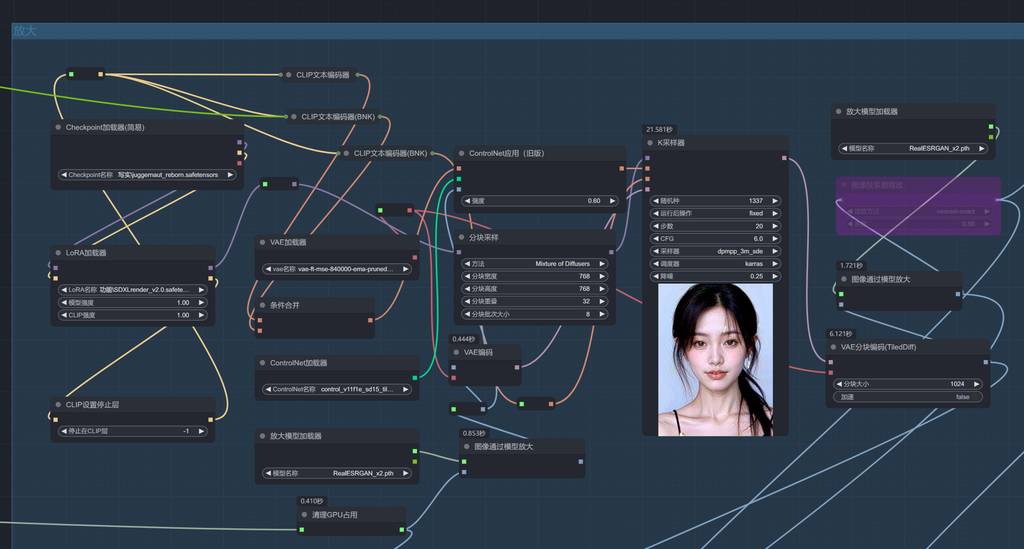
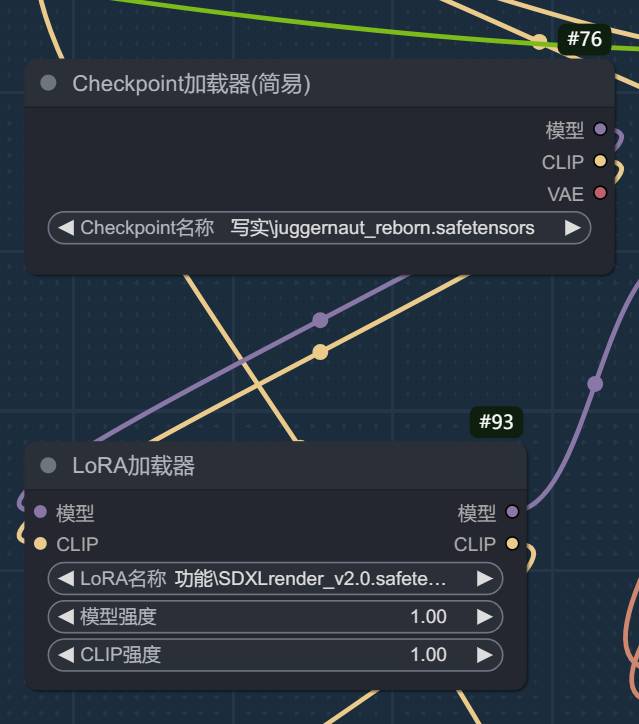
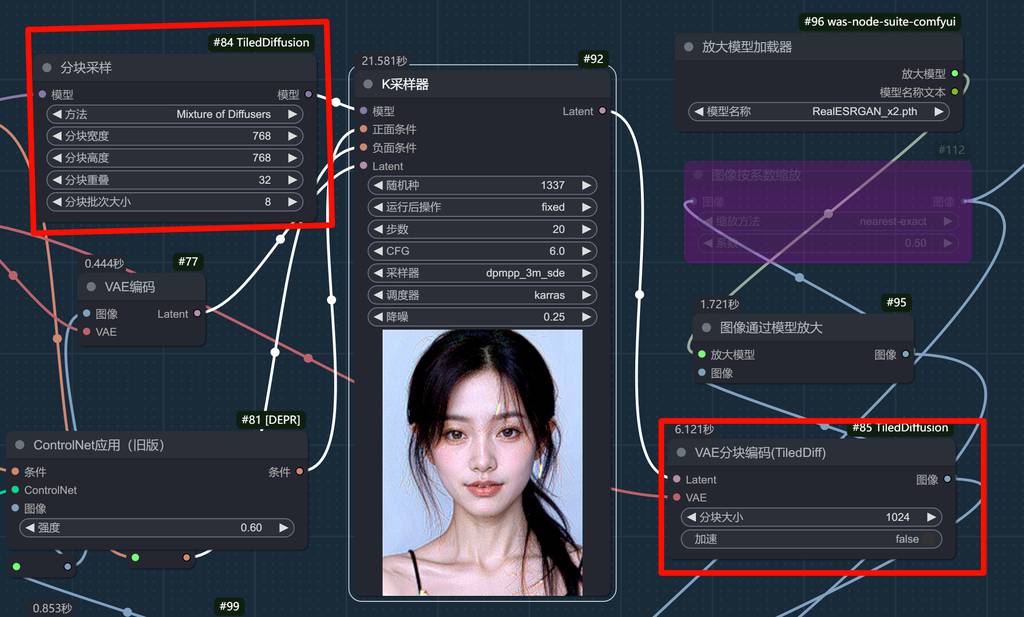
SDXL reborn 模型+sd 1.5 的 SDXLrender LoRA 模型。目的是增加图片的真实感和细节。
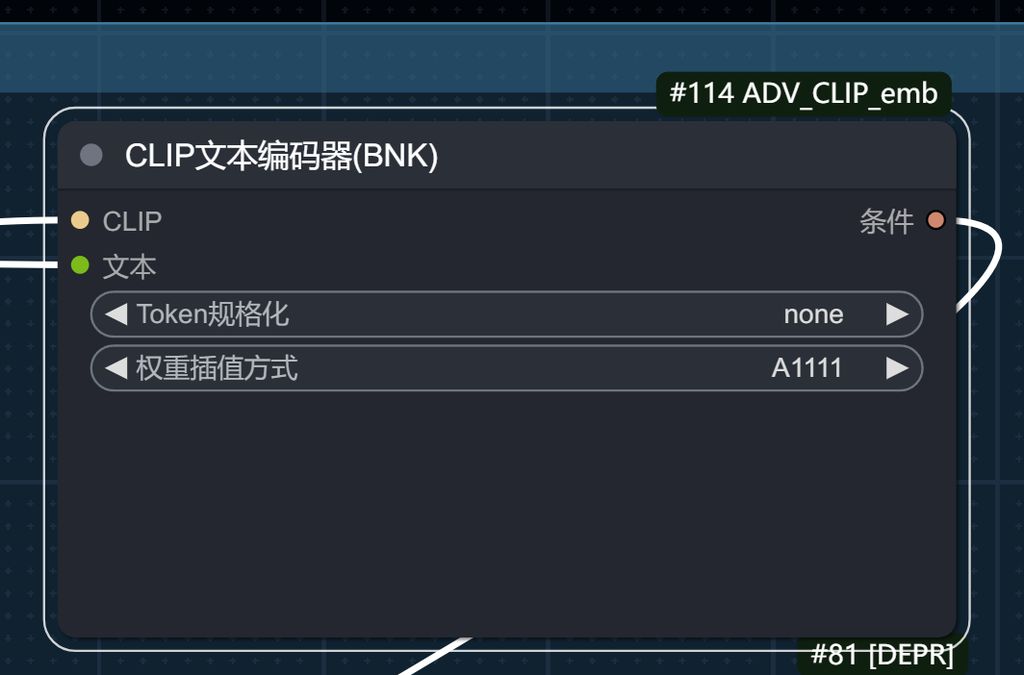
正向提示词使用 A 1111 权重插值方式。不然放大后会糊!切记切记!
Contentnet 控制,使用 SD 1.5 的 tile 模型。没错,就是乱的,但是能运行!速度也快!
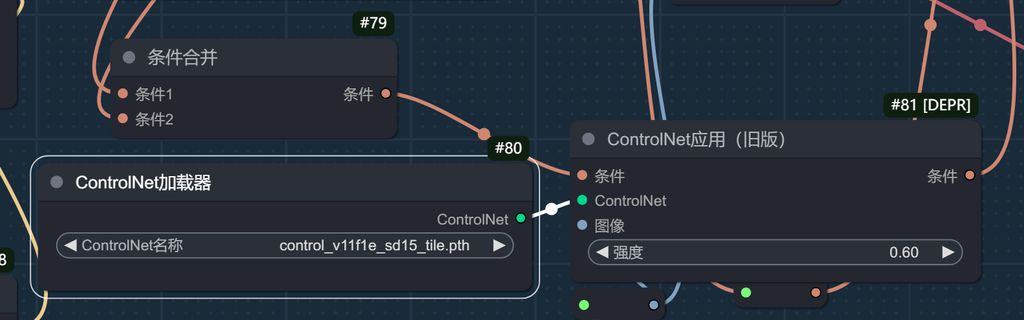
将 tilediffusion 接入放大流程中。
图像处理
这步骤可选。
经过第一次放大的图片。

嗯,细节增加了,当然有人可能会说,细节多了,但是美女没那么美了。这个就看每个人的审美了,是追求不真实的美化,还是真实的纹理?
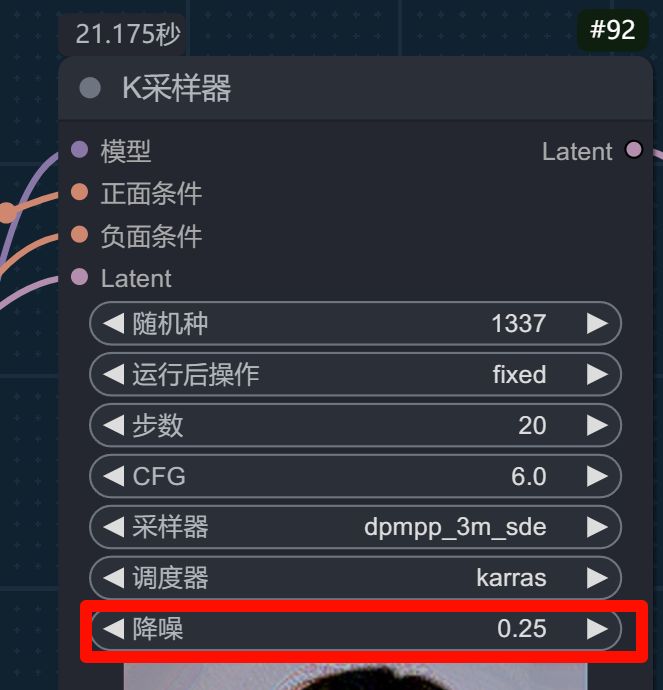
当然,放大的采样,可以调低点,这样可以减少一些不必要的细节增加。
到了这步够了吗?还不够!继续放大。
第二次放大
第二步很简单,使用到 supir节点的,这个节点使用的是 SDXL 模型,除了放大会适当对皮肤进行磨皮修复,修复第一次放大时,错误增加的皮肤细节。
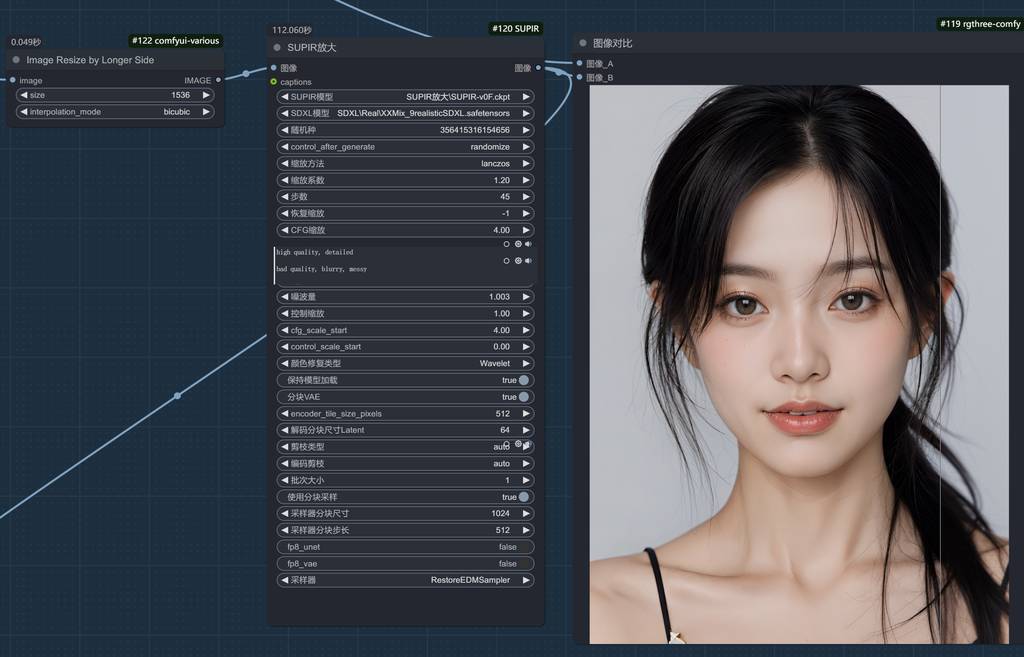
最后输出就是文章开头看到的图。
动图对比一下:


写在最后
其实 AIGC 发展到今天,各种模型已经逐步完善了,但回头发现,都会有各种的不足,从 1.5 到 flux 或者 sd 3,通过 comfyui 这套灵活的工具,可以充分发挥他们的优势!大家不妨也灵活用起来。
更多 AI 辅助设计和设计灵感趋势,请关注公众号(设计小站):sjxz 00。