5分钟阅读
整理几篇有潜力的AI技术论文
人工智能(AI)技术的飞速发展正在重塑我们的世界。从自动驾驶到医疗诊断,从语音识别到自然语言处理,AI已经渗透到了我们生活的方方面面。在这个过程中,大量的研究论文成为了推动AI技术进步的关键动力。
作为一名AI研究者或从业者,整理和识别有潜力的AI技术论文至关重要。这不仅有助于我们掌握最新的研究动向和技术进展,更能为我们的工作提供宝贵的启发和思路。然而,在海量的论文中寻找真知灼见并非易事,需要具备专业的视野和严谨的态度。
在这篇文章中,我将分享一些整理有潜力AI技术论文的策略和方法。无论您是资深的AI专家,还是刚踏入这个领域的新手,相信这些建议都能为您提供一些有益的启示。让我们一起探索AI论文的精髓,发掘隐藏其中的宝贵知识和创新灵感。
流式多元扩散:基于区域语义的实时互动生成
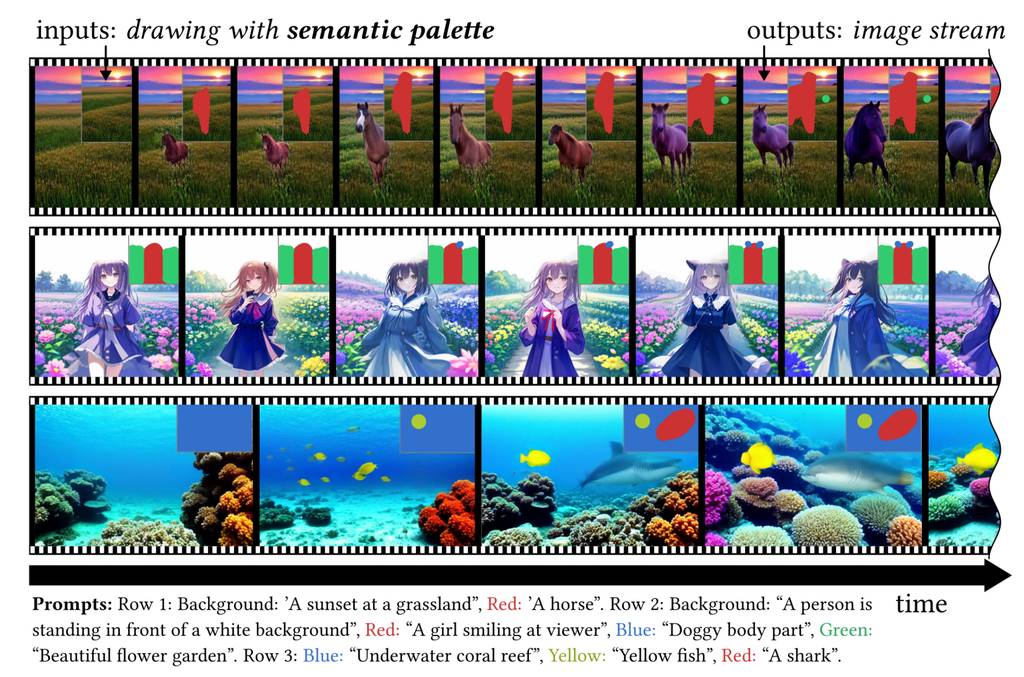
一种创新的文本到图像生成框架——semantic palette。它通过交互式的实时编辑功能提高了用户的体验,同时也展示出在图像生成领域的可能性和前景。
扩散模型在文本到图像合成领域的巨大成功,使其成为了下一代图像生成与编辑终端应用的有力竞争者。先前的研究主要通过减少推理时间或通过引入如基于区域的文本提示等新颖的细粒度控制来提升扩散模型的可用性。然而,我们发现将这些方法有效结合是一项不小的挑战,这限制了扩散模型的潜力。为了解决这一不兼容问题,我们推出了StreamMultiDiffusion,这是首个实时基于区域的文本到图像生成框架。通过稳定快速推理技术,并将模型重构为全新的多提示流批处理架构,我们在单个RTX 2080 Ti GPU上实现了比现有解决方案快10倍的全景图生成速度,以及1.57 FPS的区域文本到图像合成速度。我们的解决方案开启了一种名为“语义调色板”的互动图像生成新范式,能够实时从给定多个手绘区域生成高质量图像,并编码预定的语义含义(例如,鹰、女孩)。我们的代码和演示应用可在以下链接获取:https://github.com/ironjr/StreamMultiDiffusion。
3D-VLA:一个三维视觉-语言-行动生成世界模型
3D-VLA是一个提出的新模型,它专注于在三维物理世界中整合视觉、语言和动作。模型基于一个3D大型语言模型(LLM)构建,并引入交互令牌来与环境互动。 为了增强模型的生成能力,3D-VLA训练了一系列的实体扩散模型,并将它们整合到LLM中,用于预测目标图像和点云。 在实验上,3D-VLA通过使用held-in数据展示了显著的优势,特别是在推理能力、多模态生成等方面。
当前的视觉-语言-行动(VLA)模型依赖于2D输入,未能与更广泛的3D物理世界相结合。此外,它们通过直接从感知到行动的学习来进行行动预测,忽视了世界的广阔动态以及行动与动态之间的关系。相比之下,人类拥有描绘对未来情景想象的世界模型,以此来相应地规划行动。为此,我们提出了3D-VLA,通过引入一类新的具身基础模型家族,通过生成式世界模型无缝连接3D感知、推理和行动。具体来说,3D-VLA建立在基于3D的大型语言模型(LLM)之上,并引入了一套交互令牌来与具身环境互动。此外,为了将生成能力注入模型,我们训练了一系列具身扩散模型,并将它们与LLM对齐以预测目标图像和点云。为了训练我们的3D-VLA,我们从现有的机器人数据集中提取大量的3D相关信息,精心策划了一个大规模的3D具身指令数据集。在我们的实验中,针对持有数据集的测试表明,3D-VLA在具身环境中的推理、多模态生成和规划能力得到了显著提升,展示了其在现实世界应用中的潜力。https://huggingface.co/papers/2403.09631

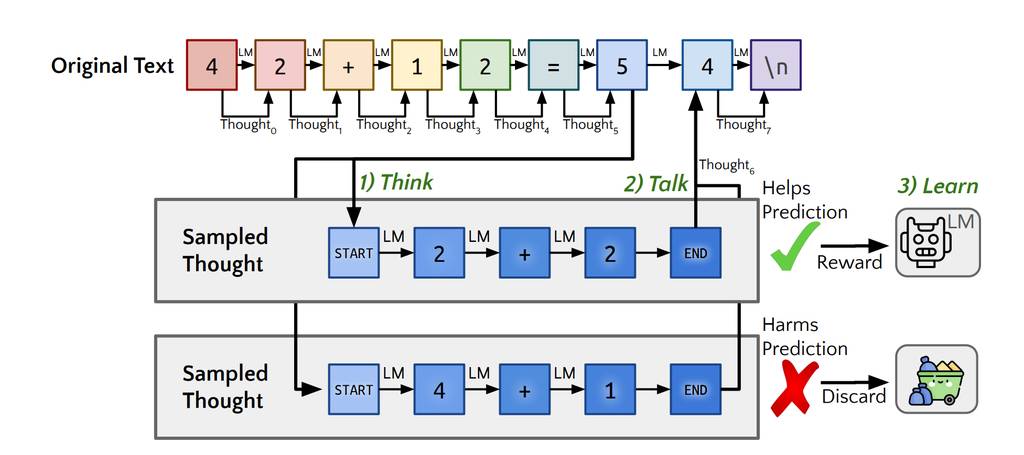
Quiet-STaR:语言模型可以自学在说话前思考
通过大型语言模型自我改进,并结合强化学习技术,研究人员提出了一种压缩和增强提示的方法,以提升人工智能在自然语言处理任务中的表现。
在写作和交谈时,人们有时会暂停下来思考。尽管以推理为核心的研究常常将推理视为回答问题或完成代理任务的方法,但推理几乎隐藏在所有书面文本中。例如,这适用于证明中未明确表述的步骤,或是对话背后的心智理论。在自我教导推理器(STaR,Zelikman等人2022年)中,通过从少量示例中推断理由并从导致正确答案的示例中学习,来习得有用的思考。这是一个高度受限的环境——理想情况下,语言模型应该能够学会在任意文本中推断未明确表述的理由。我们提出了Quiet-STaR,这是对STaR的一种泛化,其中LMs学会在每一个标记处生成理由,以解释未来的文本,从而提高其预测能力。我们解决了关键挑战,包括:1)生成延续的计算成本,2)LM最初不知道如何生成或使用内部想法,以及3)需要预测单个下一个标记之外的内容。为了解决这些问题,我们提出了一个标记级别的并行采样算法,使用可学习的标记来指示想法的开始和结束,并采用了一种扩展的教师强制技术。令人鼓舞的是,生成的理由不成比例地帮助模型预测难以预测的标记,并提高了LM直接回答难题的能力。特别是,在互联网文本语料库上用Quiet-STaR对LM进行持续的预训练之后,我们发现零样本在GSM8K(5.9%→10.9%)和CommonsenseQA(36.3%→47.2%)上有所改进,并且在自然文本中难以预测的标记的困惑度也有所提高。关键的是,这些改进不需要在这些任务上进行微调。Quiet-STaR标志着向能够以更通用和可扩展的方式学会推理的LM迈出的一步。https://huggingface.co/papers/2403.09629
关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。