5分钟阅读
AI时代设计师如何管理自己的知识?

前言
我们正身处一个信息爆炸的时代,每一天,我们都在与新鲜的知识和经典的智慧碰撞交流。对于设计师而言,如何有效地管理自己的设计知识库,已经成为了一项不可或缺的技能。掌握这门艺术,不仅能够极大地丰富和提升你的知识体系,还能将你的智慧积累转化为一个强大的“第二大脑”。
在今天的内容中,我将向大家展示如何运用人工智能的力量,来巧妙地管理和组织你的设计知识。以AIGC(AI Generated Content)知识管理为例,我将逐步带你探索如何构建一个专属于你的AI知识库。
即便你不是编程高手,也无需担心。因为在这个AI驱动的时代,你并不需要深厚的代码功底。掌握基本的操作和阅读文档的技巧就足够了。然而,我仍然坚信,在AI的浪潮中,懂得编程的设计师将更具竞争力,更能把握时代的脉搏!
设计知识库效果
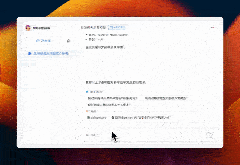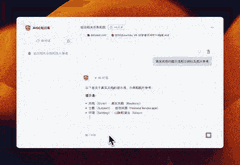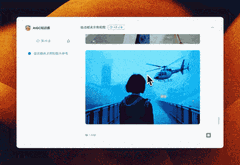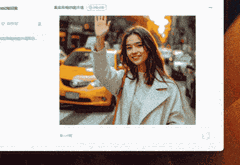
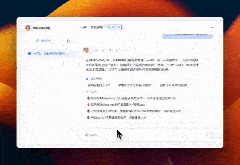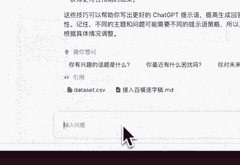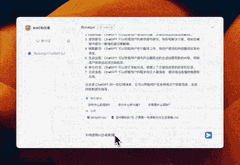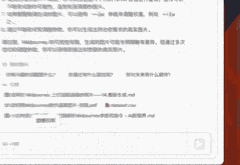
让我们一睹为快,这是我精心构建的AIGC知识库。它汇集了Midjourney、Stable Diffusion、ChatGPT等领域的智慧,为我提供了一个系统学习AI知识的平台。在日常学习和工作中,我只需将收集到的知识与精选内容填充其中,通过对话式的交互,便能轻松检索并调用这些宝贵的知识资源。这种方式让我的学习变得更加高效,也让知识管理变得触手可及。
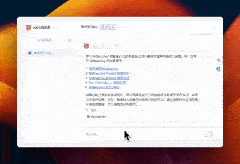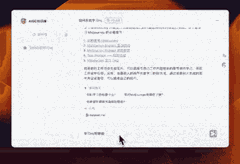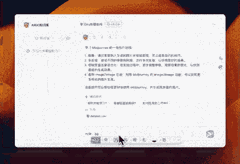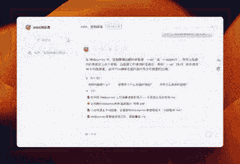
案例:如何系统学习Midjourney
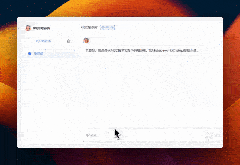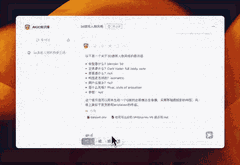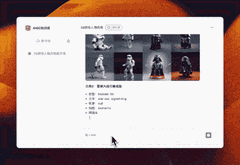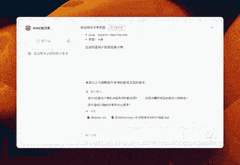
AI如同我的私人助手,它能够自动在我的知识库中进行深度搜索,快速定位并梳理出我所需的信息。它不仅能够将这些信息进行精准的总结和归纳,还能为我提供详尽的引用资源,让我在学习和创作过程中如虎添翼。这样的智能辅助,极大地提高了我的工作效率,让知识的力量在我指尖流转。
案例:如何写提示语
为了撰写出贴近真实风格的提示语,AI首先为我构建了一份结构化的知识框架,确保了信息的系统性和逻辑性。接着,它贴心地提供了丰富的案例参考,让我能够在实际情境中领会和应用这些知识。这样的辅助不仅让我在创作时能够更加得心应手,还能确保我的提示语既真实又具有说服力,仿佛每一句话都源自于生活的智慧。
假如3D游戏风格又该怎么书写呢?AI也给我方法和示例。
至于Chatgpt的提示语方法,也不在话下。
确实,AI的知识库并非凭空生成,它依赖于我们日常的积累与“喂养”。AI的作用在于它能够帮助我们整理、梳理并输出这些知识,让我们能够更高效地利用它们。而知识库的应用潜力是巨大的,我所展示的只是其众多可能性中的一部分。
接下来,我将从以下三个方面详细介绍如何构建这个知识库:
-
系统的构成:探讨如何选择合适的工具和平台,以及如何搭建知识库的基础架构。
-
内容构成:讲解如何筛选和整理知识内容,确保知识库的丰富性和准确性。
-
如何使用:分享如何高效地利用这个知识库,包括日常的维护、更新,以及如何在实际工作中发挥其最大效能。
通过这些步骤,我们将一起探索如何将知识库打造成为一个强大的知识管理和创新工具。
如何构建
系统构成
为了构建这套个人知识库,我们巧妙地整合了多种开源产品,形成了一个高效、灵活的系统架构。以下是一个整体的架构图概述,它揭示了各个组件如何协同工作,以支撑起你的个人知识库:
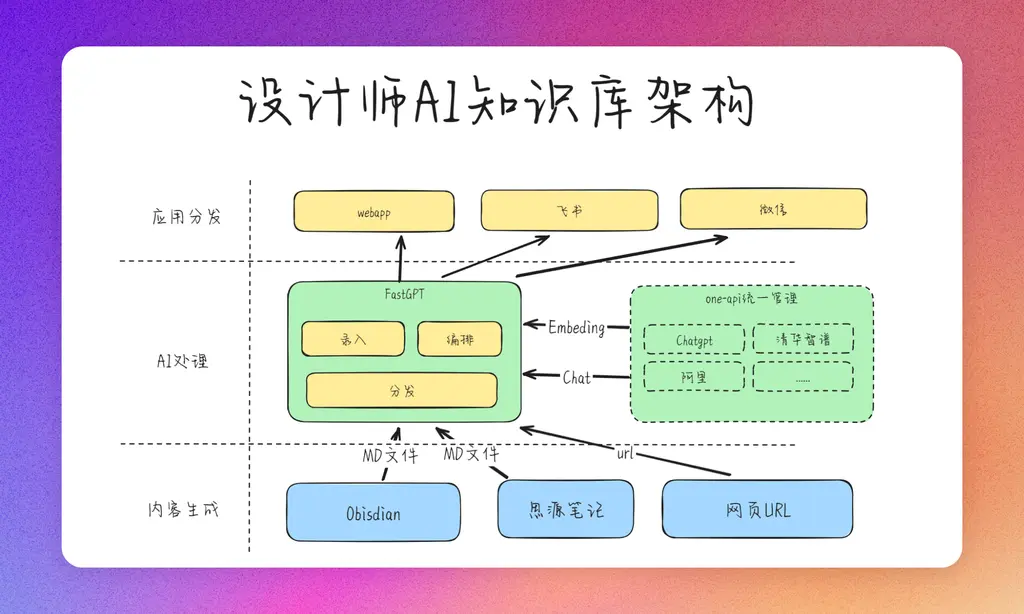
从架构图可以看出,FastGPT在个人知识库构建中扮演着核心角色。它通过以下几个关键步骤,将知识转化为可用的资产:
- 知识录入:首先,将你的设计知识输入到FastGPT中,这包括文本、图像、链接等多种形式的内容。
- 知识向量化:FastGPT利用先进的自然语言处理技术,将录入的知识转化为机器可理解的向量化表示。这一步骤为后续的智能检索和推荐打下了基础。
- 应用Agent编排:通过FastGPT提供的图形编排工具,你可以根据自己的需求,编排不同的应用Agent。这些Agent负责处理特定的任务,如智能问答、内容推荐、知识总结等。
- 分发与应用:最后,FastGPT将这些经过处理的知识以各种应用形态分发出去,可以是API接口、Web应用、移动应用或者集成到其他工作流程中。
这样的架构设计使得知识库不仅能够存储和管理知识,还能够智能化地处理和分发知识,极大地提高了设计师的工作效率和创新速度。FastGPT的这种灵活性和扩展性,确保了知识库能够随着技术的进步和业务需求的变化而不断演进。
构建步骤
申请大模型API
申请大模型的门槛,除了openai的chatigpt,其他国内的是非常低的,我把地址贴在这里,大家可以自行申请,申请完成后,可以获得一些APPID、Key这些,可以先记录下来,后面one-api用到。

至于申请步骤,国内的都非常简单,基本上按照官网的一步一步操作就行。我这里给一些常用模型的申请入口:
**百度千帆:**https://cloud.baidu.com/product/wenxinworkshop 阿里通义千问:https://tongyi.aliyun.com/ 清华智谱:https://www.zhipuai.cn/ 月之暗面:https://www.moonshot.cn/ Openai:openai.com
至于openai,网上也有大量教程,大家可以自行搜索。
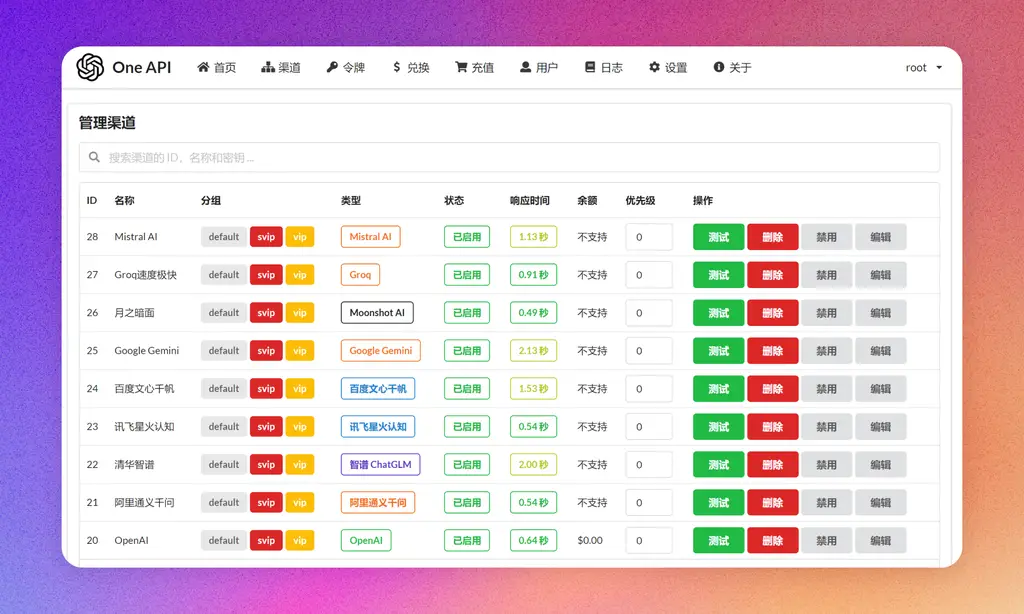
接入one-api
one-api是大模型的关键,可以把市面上大部分语言模型管理起来,包括本地运行的开源模型。关于如何接入,我上一篇文章就有较为详细的介绍,# 【AI辅助设计】小孩子才做选择,语言大模型我全都要!大家可以移步过去看看,也可以直接看官方的github介绍,有详细的教程。官方地址:https://github.com/songquanpeng/one-api
部署FastGPT
FastGPT作为个人知识库构建的核心,其提供的两种版本——SaaS在线版和免费的开源版,极大地满足了不同用户的需求。我个人使用的是开源版,它提供的功能已经完全能够满足我的日常需求。在这里,我要特别感谢FastGPT的产研团队,他们为我们带来了如此出色的产品,确实值得一个大大的赞👍! 我将FastGPT部署在了自家的NAS上,采用的是Docker方式进行安装。如果你有VPS或云服务器,同样可以按照类似的步骤进行部署,原理是相通的。 部署过程并不复杂,只需遵循官方文档的步骤即可。下面,我将简要演示如何在群晖Docker上部署FastGPT
建立文件目录
在群晖文件管理docker目录下,新建fastgpt目录,作为FastGPT的主目录,存储数据库和配置文件等。然后记得要赋予该目录为最高权限。
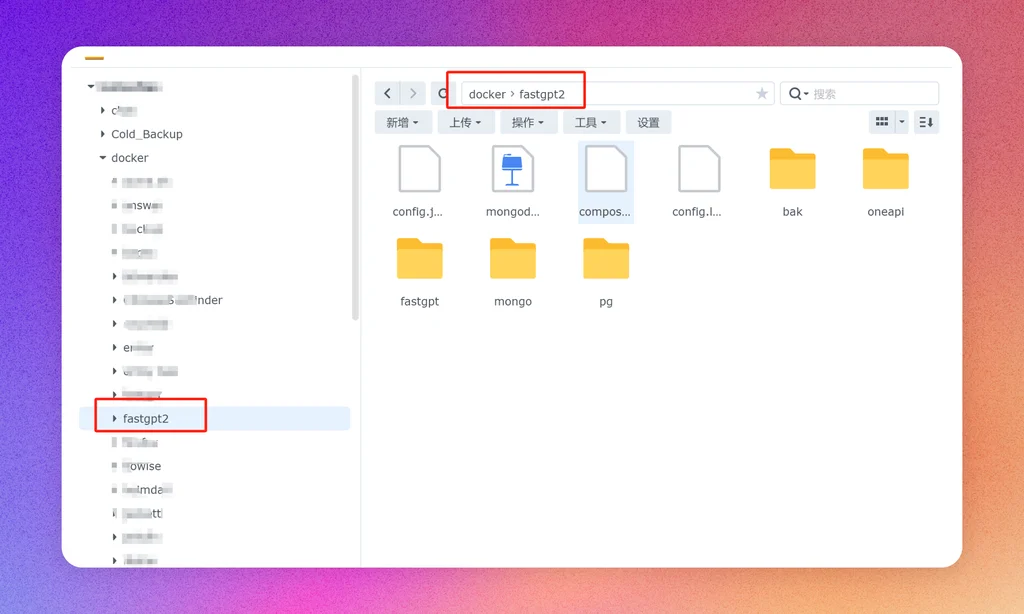
右键-属性-权限,添加everyone完全控制权限。
修改docker-compose.yaml
下载官方的compose.yaml文件:https://github.com/labring/FastGPT/blob/main/files/deploy/fastgpt/docker-compose.yml
# 非 host 版本, 不使用本机代理
# (不懂 Docker 的,只需要关心 OPENAI_BASE_URL 和 CHAT_API_KEY 即可!)
version: '3.3'
services:
pg:
image: ankane/pgvector:v0.5.0 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云
container_name: pg
restart: always
ports: # 生产环境建议不要暴露
- 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
mongo:
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18
container_name: mongo
restart: always
ports:
- 27017:27017
networks:
- fastgpt
command: mongod --keyFile /data/mongodb.key --replSet rs0
environment:
- MONGO_INITDB_ROOT_USERNAME=myusername
- MONGO_INITDB_ROOT_PASSWORD=mypassword
volumes:
- ./mongo/data:/data/db
entrypoint:
- bash
- -c
- |
openssl rand -base64 128 > /data/mongodb.key
chmod 400 /data/mongodb.key
chown 999:999 /data/mongodb.key
exec docker-entrypoint.sh $$@
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:latest # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
restart: always
environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
# 中转地址,如果是用官方号,不需要管。务必加 /v1
- OPENAI_BASE_URL=https://api.openai.com/v1
- CHAT_API_KEY=sk-xxxx
- DB_MAX_LINK=5 # database max link
- TOKEN_KEY=any
- ROOT_KEY=root_key
- FILE_TOKEN_KEY=filetoken
# mongo 配置,不需要改. 用户名myusername,密码mypassword。
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
# pg配置. 不需要改
- PG_URL=postgresql://username:password@pg:5432/postgres
volumes:
- ./config.json:/app/data/config.json
networks:
fastgpt:
只需要关心和处理以下几个代码就可以:
- OPENAI_BASE_URL=https://api.openai.com/v1
- CHAT_API_KEY=sk-xxxx
OPENAI_BASE_URL填写one-api的地址,例如我的one-api地址是:http://192.168.1.110:3200/v1 注意,这里后面要有v1.
CHAT_API_KEY 填写one-api的令牌即可。
这里mongo数据库的版本也要注意一下,因为官方给的版本跟我的群晖920+硬件不匹配,所以我改为了4.4.6版本了。
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:4.4.6
改完后将yaml文件放在上文建好的fastgpt目录下。
配置config.json文件
这里也比较关键,决定了FastGPT能够调用什么模型,同时格式必须严格遵守json文件规范,不然很容易不生效。
在官方下载config配置文件:https://github.com/labring/FastGPT/blob/main/projects/app/data/config.json
# 其他代码
"llmModels": [
{
"model": "gpt-3.5-turbo",
"name": "gpt-3.5-turbo",
"maxContext": 16000,
"maxResponse": 4000,
"quoteMaxToken": 13000,
"maxTemperature": 1.2,
"charsPointsPrice": 0,
"censor": false,
"vision": false,
"datasetProcess": false,
"usedInClassify": true,
"usedInExtractFields": true,
"useInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
},
# 其他模型
],
"vectorModels": [
{
"model": "text-embedding-ada-002",
"name": "Embedding-2",
"charsPointsPrice": 0,
"defaultToken": 700,
"maxToken": 3000,
"weight": 100
}
],
# 其他代码
按照模板,我们一般只关心llmModels和vectorModels两处代码即可,添加上要调用的模型。修改这个文件,建议还是装个vscode修改,方便检查格式是否有错。
构建docker容器
完成所有配置后,我们就可以构建docker容器了。在群晖容器应用中,点击新建项目,按照指引一步一步操作。
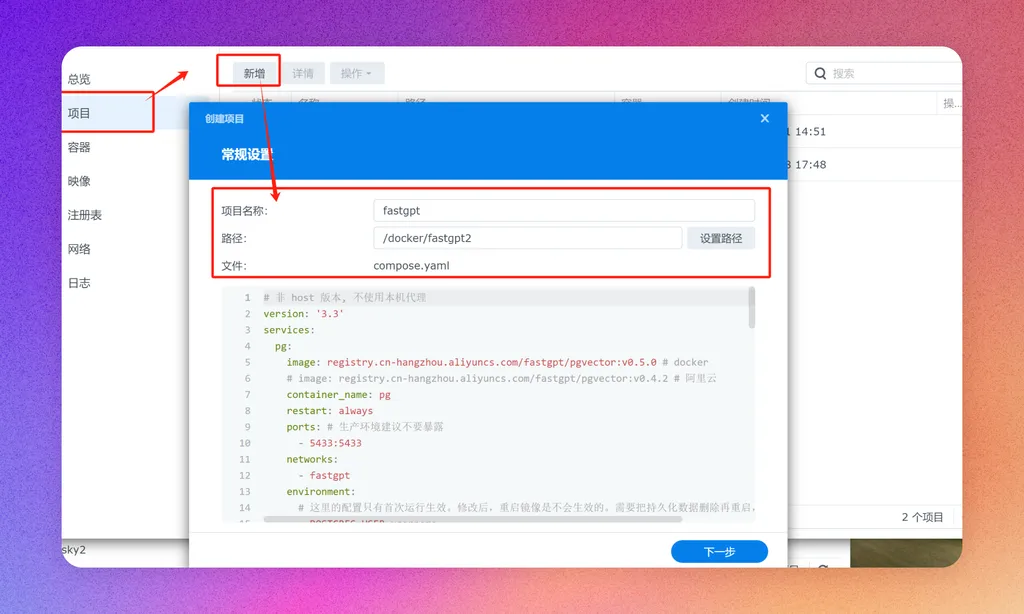
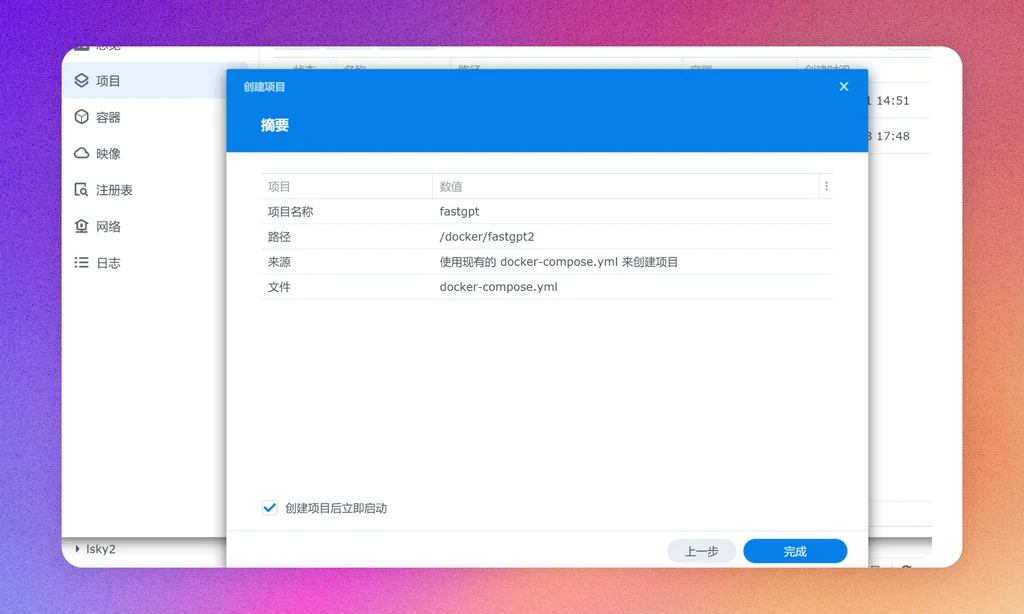
都是默认配置即可,最后点击完成,等待容器构建完成。如果没报错,打开http://nasip:3000 即可打开FastGPT的webui。
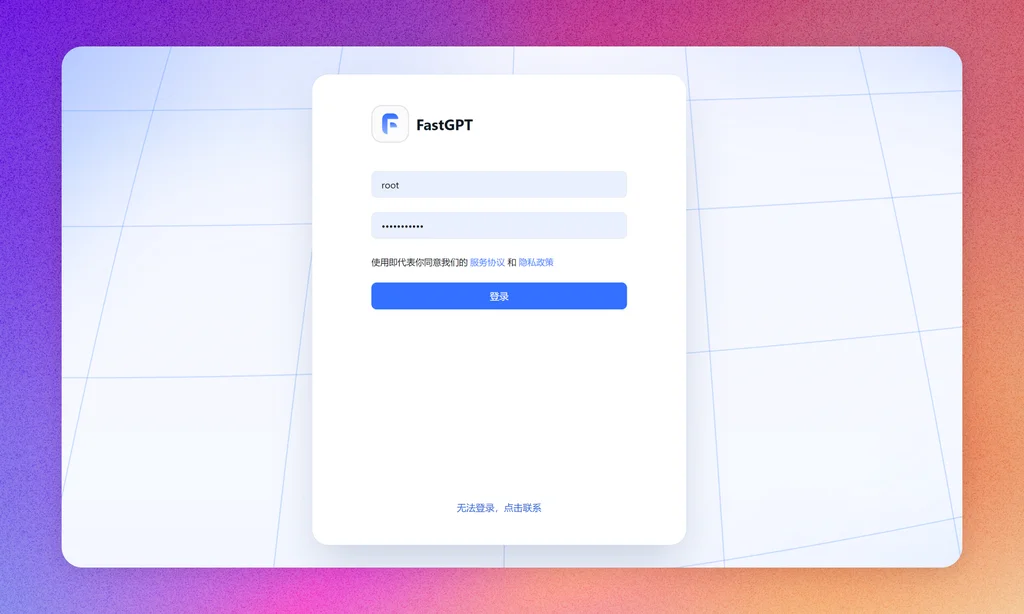
至此我们完成了FastGPT的部署,可以开始玩耍了。
知识(数据集)处理
FastGPT确实为用户提供了多种数据源接入方式,极大地便利了知识的整合与利用。在我个人的使用习惯中,Markdown(md)文档成为了我最常用的知识输入方式。我通常会先使用Obsidian这样的知识管理工具来撰写文章或剪藏网络内容,并将其保存为md文件格式。随后,我会将这些宝贵的知识资产批量导入到FastGPT中。
这种方式的优势在于:
- 格式兼容性:Markdown格式简单、通用,易于阅读和编辑,且支持跨平台使用。
- 高效写作:Obsidian等工具提供的双链、标签等功能,有助于构建知识网络,提高写作效率。
- 便捷导入:FastGPT支持Markdown文件,可以快速将已有的知识库整合到系统中,无需复杂的格式转换。
通过这样的工作流程,我能够将散落的知识点有序地组织起来,并在FastGPT的帮助下,将这些知识转化为可查询、可利用的智能资源。这不仅提升了我的知识管理效率,也为我日后的学习和工作提供了强大的支持。
md文档有个好处,就是AI的回答可以带上图片,其他的数据集都不行。
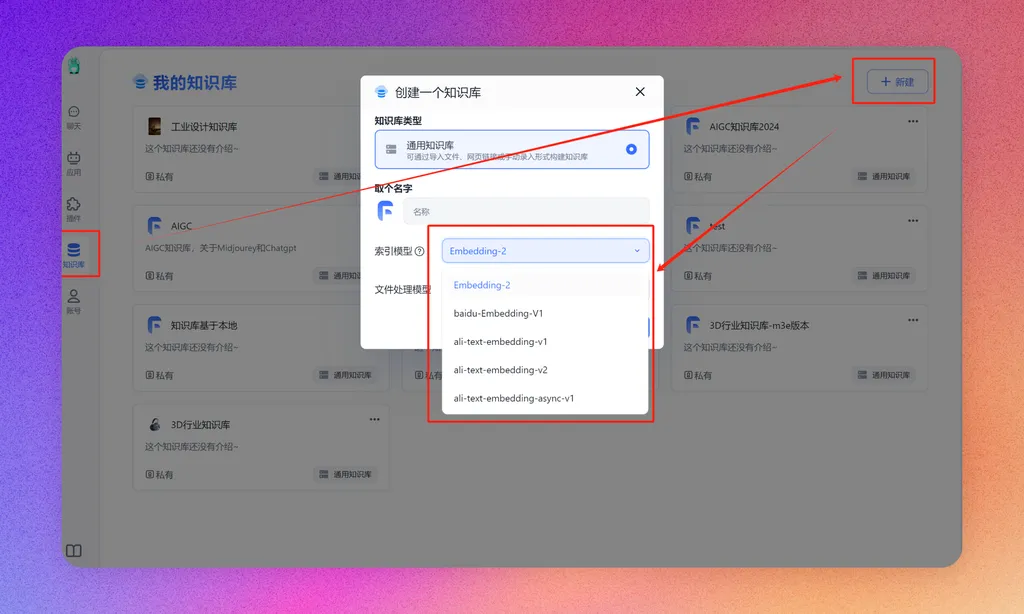
创建知识库
在FastGPT界面中,选择知识库—新建创建一个知识库,选择好向量模型后点击确认。
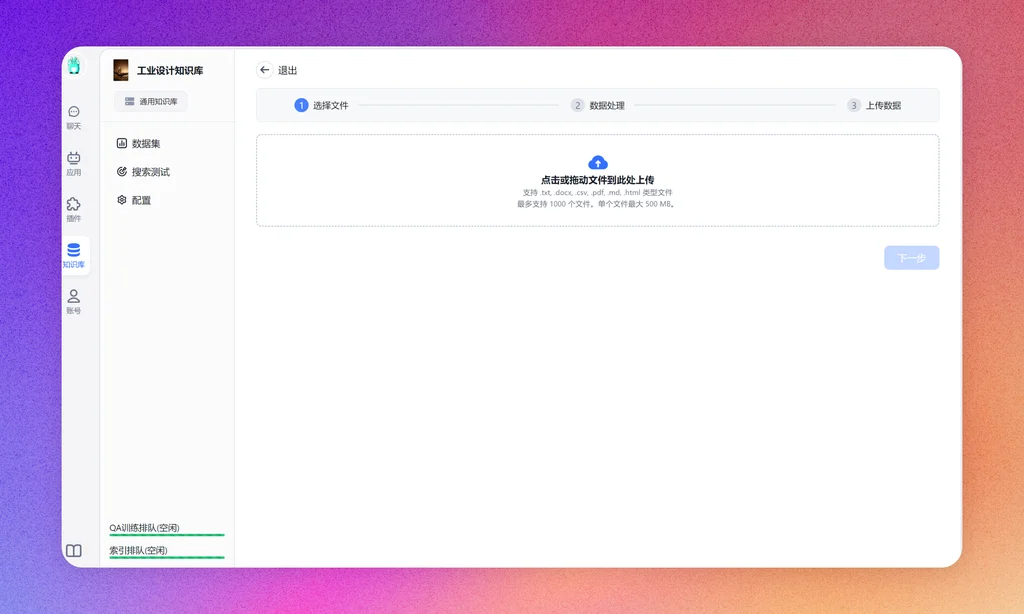
录入数据
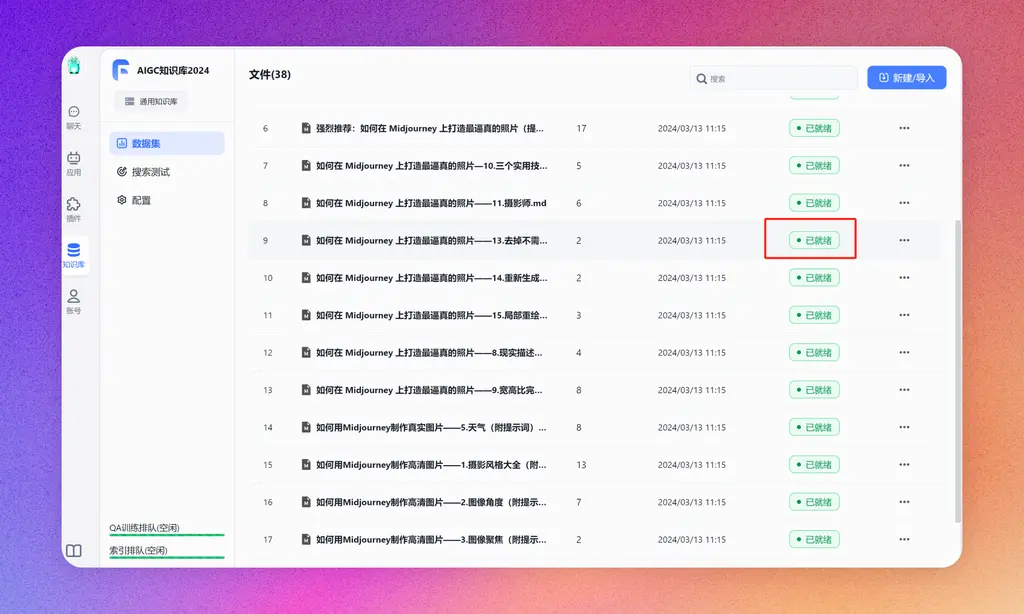
选择刚才创建的知识库,新建/导入-文本数据集-本地文件-确认,然后把md所在文件夹全部拖进去,点击下一步,上传即可交给向量模型进行数据向量化。
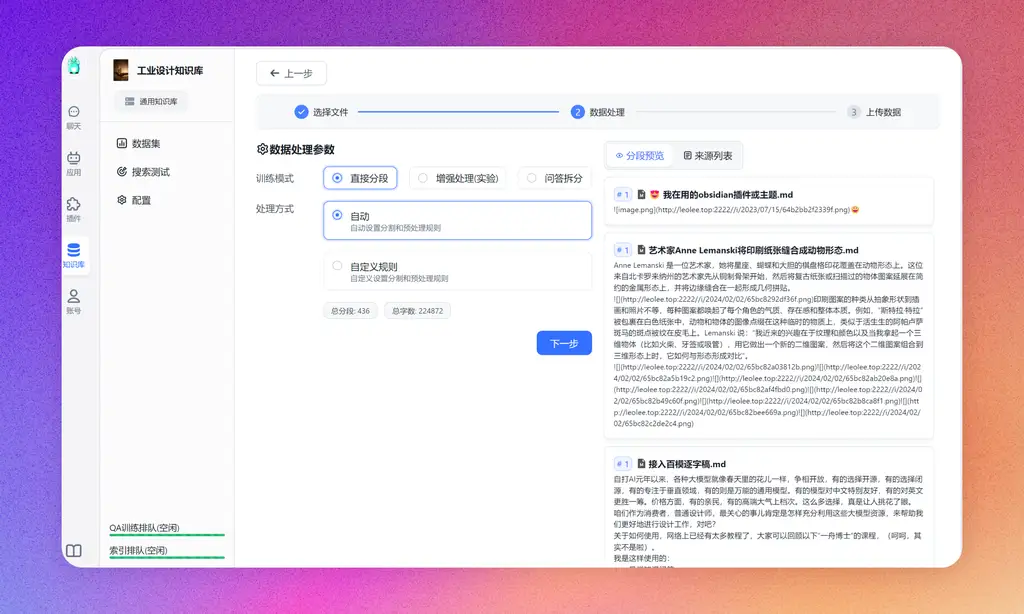
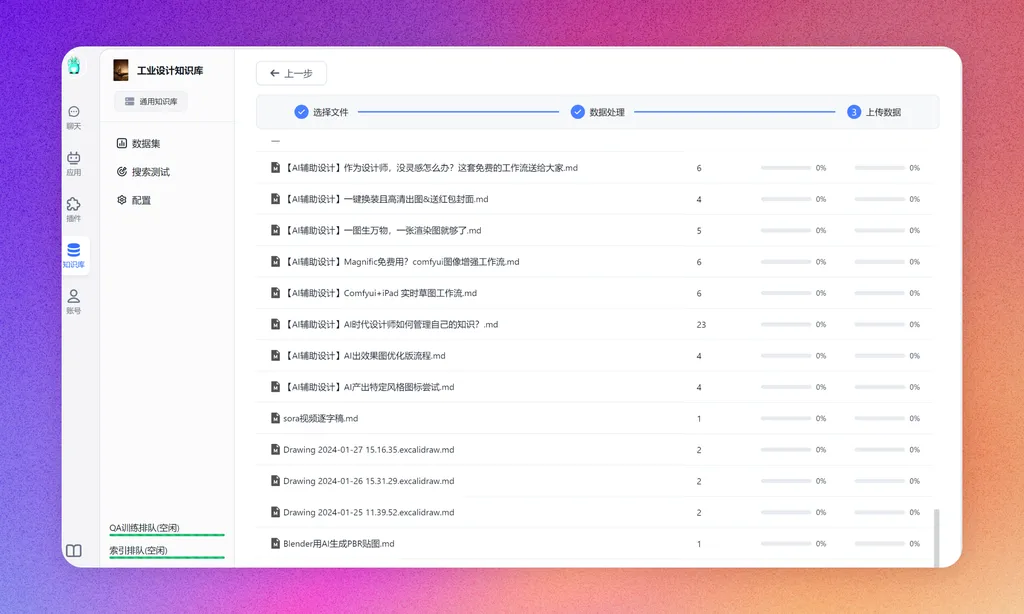
实测openai的向量模型是最稳定最快速的。当看到数据已就绪时,证明知识库已经建立好了。
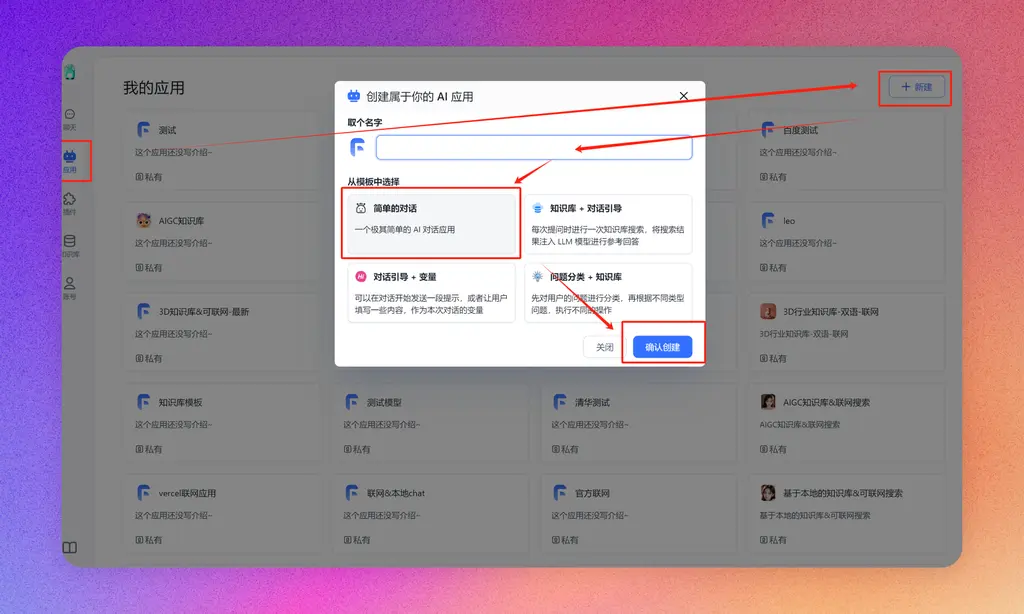
新建应用
有了知识库,我们还需要建一个AI应用,调用这个数据库,形成AI对话。我们先新建一个简单的对话应用。
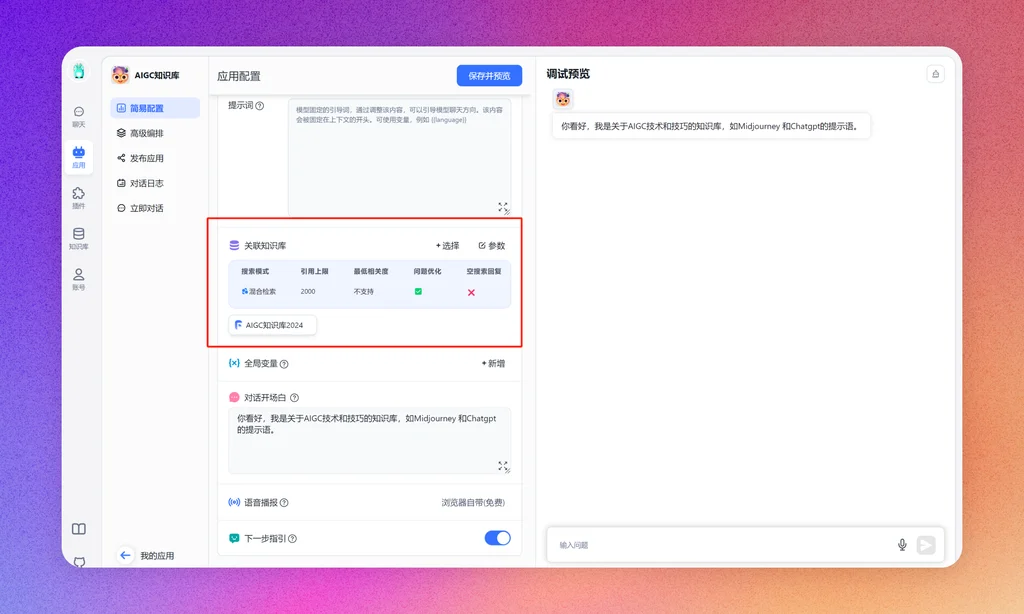
新建完成后,进入该应用进行设置。在简易配置下,关联建立的知识库,然后保存并预览,在右侧的调试预览窗口,就可以看到效果了。
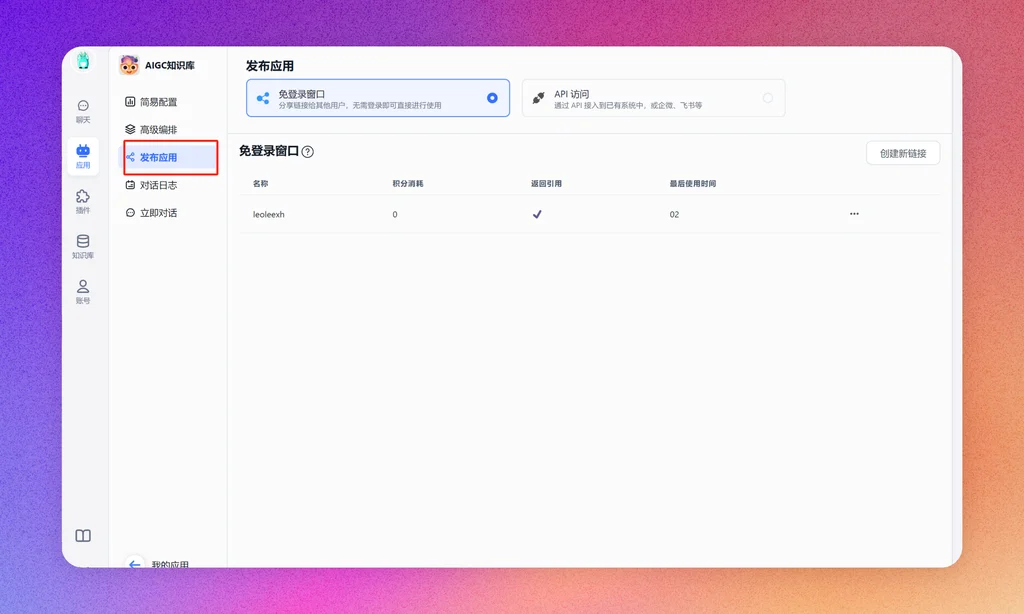
发布
在发布应用功能那里,可以将应用发布为一个web链接,就可以直接基于这个应用和知识库进行文档。
对话的效果可以看文章开头。当然,发布态可以结合飞书和微信生态进行嵌入,这需要一定的开发能力。
至此,我们已经完成了一个简单AI知识库的介绍。如果你对构建这样一个知识库感兴趣,不妨跟随我的脚步,亲自动手尝试。让AI成为我们得力的“第二大脑”,助力我们的学习和工作。 感谢大家的阅读,今天的分享就到此为止。希望我的经验能够对你有所启发,也期待看到你在知识管理上的创新与实践。如果有什么疑问或想法,欢迎继续交流讨论。祝大家学习愉快!
关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。