5分钟阅读
三个值得关注的AI技术或研究

【AI前沿】值得关注和思考!最近一周三个AI技术或研究
前言
过去一周,AI 与 AIGC 领域迎来多项技术突破。本文聚焦三款值得关注的核心技术:开源图像修改模型 UniWorld-V 1、多模态 3D 纹理生成工具 FlexPainter,以及 Apple 揭示的大模型思考效能临界点研究。
一、UniWorld-V 1:开源图像编辑新标杆
技术定位
作为 Kontext 开源前夕首个问世的图像修改模型,UniWorld-V 1 由北京大学袁粒团队研发,实现了视觉理解、生成与编辑的统一框架,支持 20 余项视觉任务。
UniWorld-V 1 技术架构示意图
核心突破
- 全资源开源:开放 10+视觉任务数据集,包含 28.6 万长文本标注样本及 72.4 万高清编辑样本
- 创新架构:采用对比语义编码器与扩散模型协同工作流程
- 零学习令牌机制:通过
<指令><图像>因果注意力精准解析用户需求
技术流程
graph LR
A[输入图像] --> B(对比语义编码器)
B --> C[精细控制信号]
C --> D{扩散模型}
D --> E[高保真输出]
效果展示


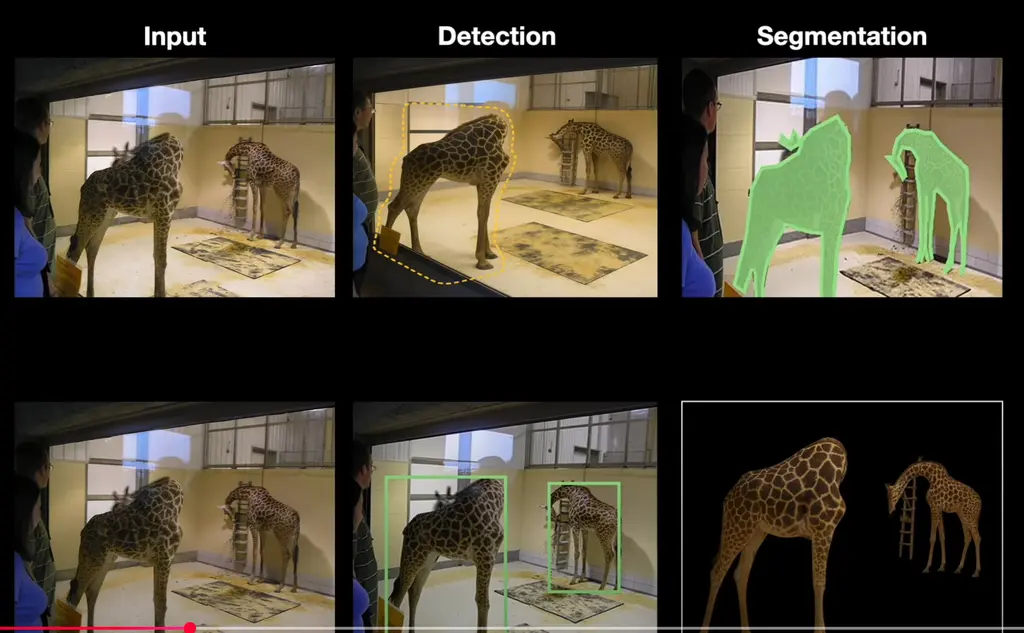
图像编辑效果对比
应用场景
- 文本生成图像(BLIP3o-60 k + OSP 1024-286 k 数据集)
- 高质量图像编辑(72 万专业样本)
- 虚拟试衣(DeepFashion-27 k 数据集)
体验方式
- 环境配置:
git clone https://github.com/PKU-YuanGroup/UniWorld-V1
conda create -n univa python=3.10
pip install -r requirements.txt
- 模型下载:
huggingface-cli download LanguageBind/UniWorld-V1
在线体验:
http://8.130.165.159:8800
ComfyUI 插件:
https://github.com/judian17/ComfyUI-UniWorld-jd17
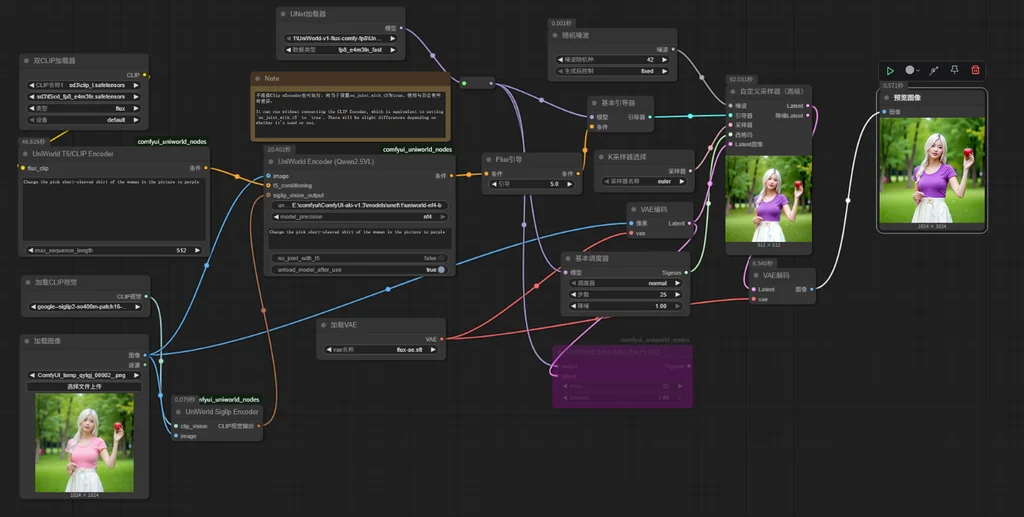
ComfyUI 操作界面
二、FlexPainter:3D 纹理生成革命
香港科技大学团队推出的多模态驱动方案,解决传统 3 D 贴图三大痛点:
- 控制灵活性不足
- 跨视图不一致
- 分辨率限制

多模态提示生成效果
技术架构
graph LR
A[多模态嵌入空间] --> B[视图同步生成]
B --> C[3D感知纹理重建]
C --> D[4K增强输出]
核心创新
- 多模态融合引擎:构建共享条件嵌入空间,支持文本/图像/混合指令
- 视图同步技术:通过网格表示法提升 300%视角一致性
- 4 K 增强管线:智能修补接缝与超分辨率重建
技术解析图
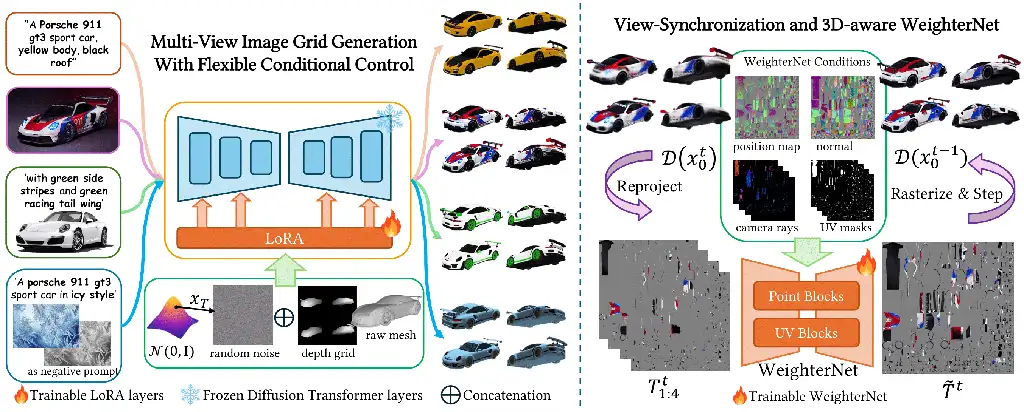
FlexPainter 技术架构图
应用效果

「赛博机甲龙」文本生成效果

《星月夜》风格迁移

工业场景应用
项目地址:
https://starydy.xyz/FlexPainter/
三、Apple 研究:大模型思考效能临界点
最新论文《思考的假象:通过问题复杂度解析推理模型的优势与局限》揭示关键发现:
大模型不能总是思考!
核心结论
-
效能抛物线现象:
- 简单任务:标准模型更高效
- 中等难度:思考型模型优势显现
- 高复杂度:所有模型准确率归零
-
思考代币悖论:
当问题复杂度超过临界深度(如汉诺塔 8 层以上),思考模型产生的代币数量不增反降,显示当前推理架构存在根本性限制。
实验图示

汉诺塔实验模型崩溃现象
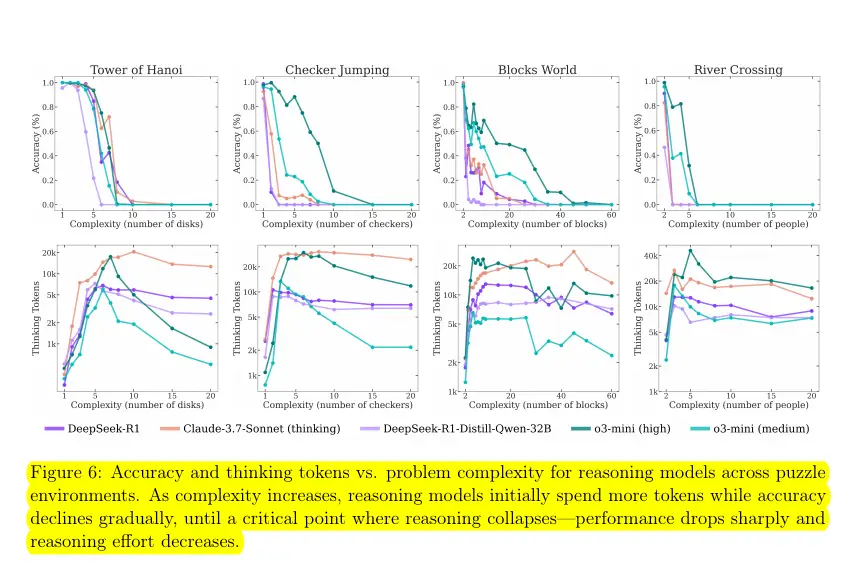
难度与模型表现关系
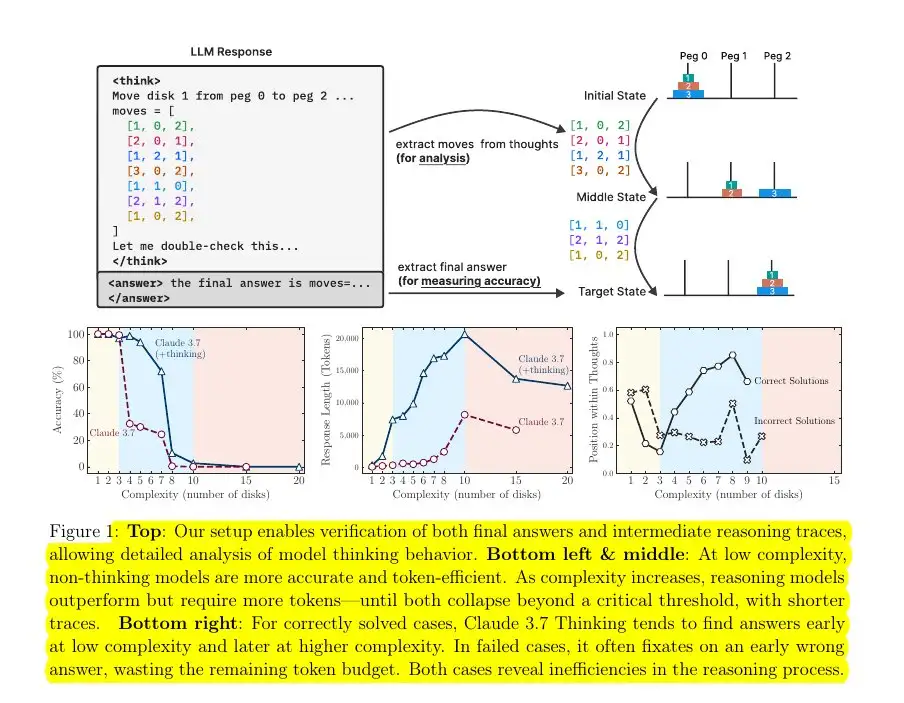
思考代币数量变化趋势
论文地址:
https://machinelearning.apple.com/research/illusion-of-thinking
获取更多 AI 设计前沿资讯
欢迎关注公众号 【设计小站】(ID:sjxz00)