5分钟阅读
Supermemory ai:为 AI 打造人类级记忆的超级引擎

前言
今天这篇文章,是 Supermemory. ai公司的博客文章,除了介绍公司产品,还大致介绍了部分原理和背后的思考,值得读一下。
Supermemory.ai 是一家专注于人工智能记忆解决方案的公司,提供一个强大的平台,帮助用户和开发者将外部知识无缝集成到AI应用程序中。以下是该公司的简要介绍:
- 核心产品:Supermemory 是一个AI驱动的“第二大脑”工具,旨在帮助用户组织、搜索和利用他们在互联网上保存的所有内容(如书签、文章、推文、文档等)。通过其API,用户可以将记忆功能添加到AI应用中,实现跨对话的长期上下文记忆和语义搜索功能12。
- 主要功能:
- 技术与创新:Supermemory 的系统受人类大脑记忆机制启发,开发了模型互操作的记忆控制协议(MCP),使用户可以在不同的语言模型(LLM)应用之间携带记忆和聊天记录,而不会丢失上下文6。
- 用户群体:服务于个人用户、团队以及开发者社区,在GitHub上拥有超过9千星标,是快速增长的开源项目之一7。
Supermemory.ai 的目标是通过技术创新,让用户能够更高效地管理和利用他们的数字内容,将其转变为实际可用的知识库。
原文
以下是原博客内容。
语言是智能的核心,但真正驱动深度交互的却是记忆——那种随时间累积、唤醒并赋予信息情境的能力。
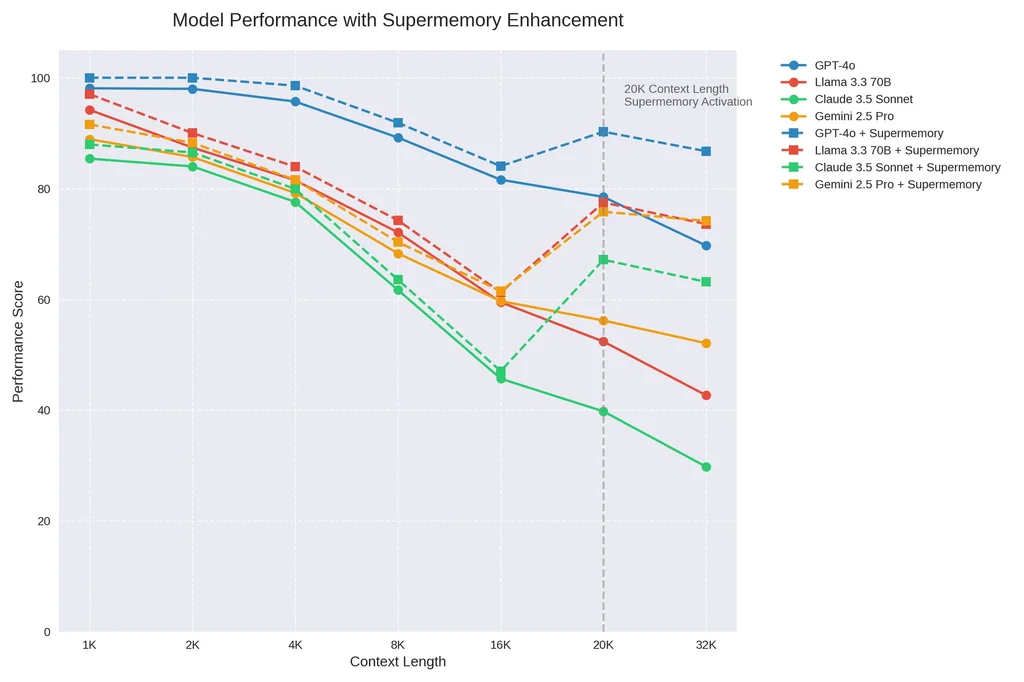
大语言模型(LLMs)已精通语言,记忆却始终是它们的阿喀琉斯之踵。每当上下文窗口扩大,现实需求便迅速将其淹没:用户上传海量文档、进行马拉松式对话,期待系统无缝调用历史偏好。结果?LLMs 遗忘、幻觉频发,最终迫使用户按下”重置键”。
▍为何 LLM 记忆如此艰难?
记忆层绝非简单叠加存储。它需要同时满足五大严苛要求:
- 精准召回:
在数年聊天记录与数千文档中精准定位目标,同时过滤无关/过时/噪声数据 - 毫秒响应:
在亿级数据量下保持<400 ms 延迟(当前方案普遍存在扩展瓶颈)- 向量数据库:规模增长导致成本飙升或响应骤降
- 图数据库:每次查询需遍历指数级增长的边节点
- 键值存储:受限于模型上下文长度,本质是转移而非解决问题
- 无缝集成:
提供开箱即用的 API/SDK,避免数周适配与复杂迁移 - 语义理解:
解析隐喻与模糊表达(例如用户问”展示我关于未来城市的思考”,实际需要关联书签、笔记、聊天片段等多模态数据)

▍Supermemory 的解决方案:人类记忆的工程化复刻
人脑不完美存储所有细节——这恰是进化赋予的优势。我们借鉴生物记忆机制,构建可扩展的 AI 记忆架构:
智能遗忘与衰减
系统自动弱化低频信息(如三周前的停车位),强化核心内容(如昨日重要会议),避免信息过载
近因优先原则
刚讨论的议题自动置顶,常用文档保持高优先级,动态匹配当下需求而非机械匹配关键词
动态记忆重构
像人脑关联碎片记忆般,系统持续更新摘要并建立跨域连接——上月偶然的灵感可能成为今日破局关键
分层记忆架构
基于 Cloudflare 基础设施构建多层次存储:
- 即时层:热数据毫秒响应(采用 KV 键值存储)
- 深层存储:按需调用历史数据,拒绝无效预加载
▍超越记忆引擎的生态体系
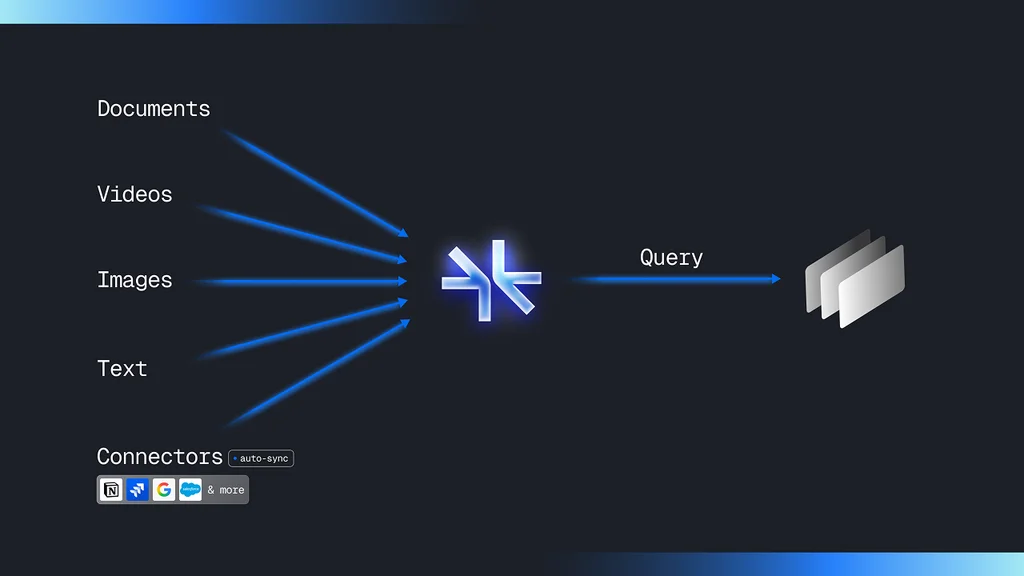
Supermemory 不仅是向量数据库或 RAG 工具,更是即插即用的无限上下文解决方案。接入现有 AI 服务仅需:
- 添加服务端点
- 输入 API 密钥
- 完成部署
核心产品矩阵:
🚀 记忆即服务(MaaS)
支持多模态数据存储与查询,无缝对接 Google Drive/Notion 等平台,通过三条 API 实现全功能:
/add # 添加记忆
/connect # 建立连接
/search # 智能检索
⚡ 无限对话 API(新发布)
动态管理对话记忆流,仅向模型传递必要上下文,实现:
✅ 降低 40%token 消耗
✅ 提升响应质量
✅ 加速 15%推理速度
👉 一行代码即刻体验
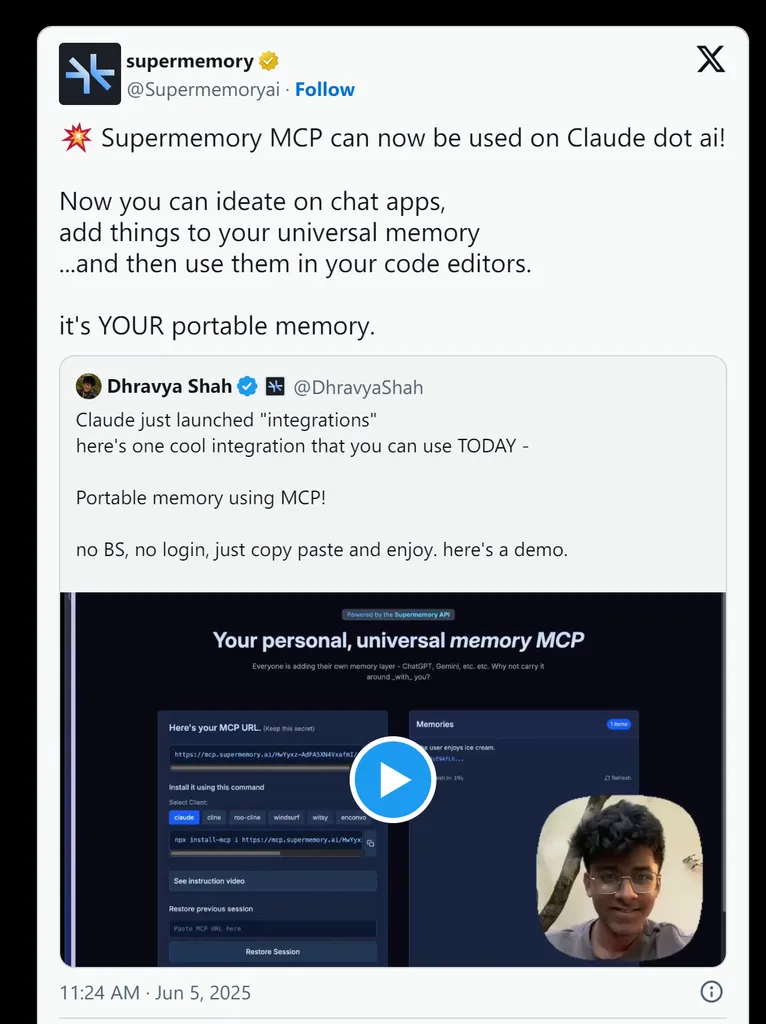
🌐 记忆中枢协议(MCP)
实现跨 LLM 应用的记忆与对话迁移,彻底消除语境断裂
▍记忆:通往 AGI 的最后拼图
当 AI 拥有人类级记忆,我们将见证:
- 客户服务机器人记住三年产品使用偏好
- 医疗助手关联十年病历与最新论文
- 创意工具串联碎片灵感生成突破性方案
此刻即是未来起点
▸ 接入服务
▸ 探索MCP协议
▸ 加入记忆革命团队
**记忆不止于存储,它是智能的时空纽带——
此刻埋下的记忆锚点,终将编织成 AGI 的神经网络。
原文地址:https://blog.supermemory.ai/memory-engine/
想获取更多 AI 辅助设计和设计灵感趋势? 欢迎关注我的公众号(设计小站):sjxz00。