5分钟阅读
出图更傻瓜了!controlnet作者新作:Omost
前几天,controlnet作者-lllyasviel,放出一个源码Omost。 该项目的作用,让用户只需要输入一个简单的主题,AI就可以根据这个主题,对画面自动进行自动补全,最终输出细节丰富且符合意图的图片。
官方效果
看看官方放出效果:
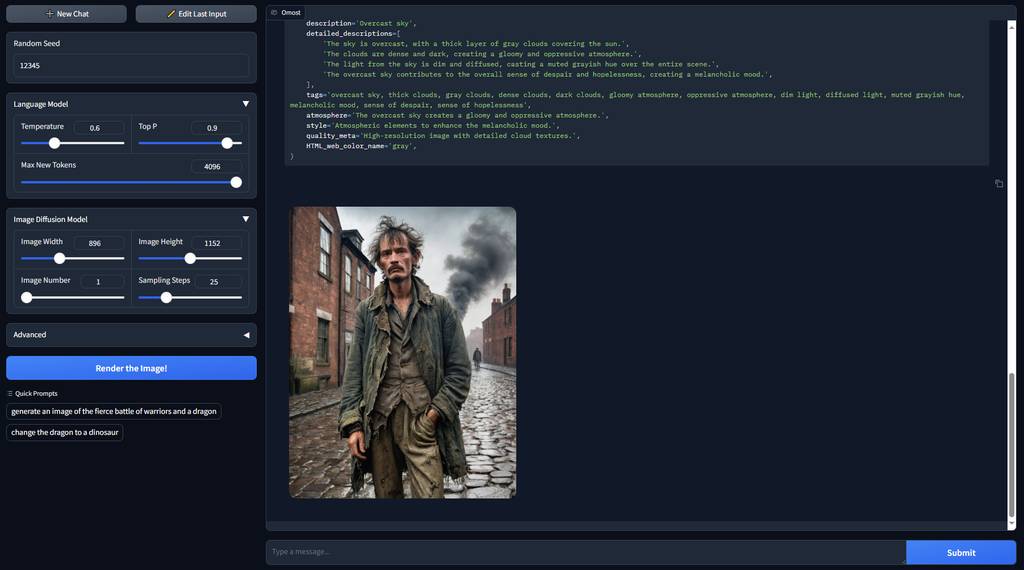
a ragged man wearing a tattered jacket in the nineteenth century:
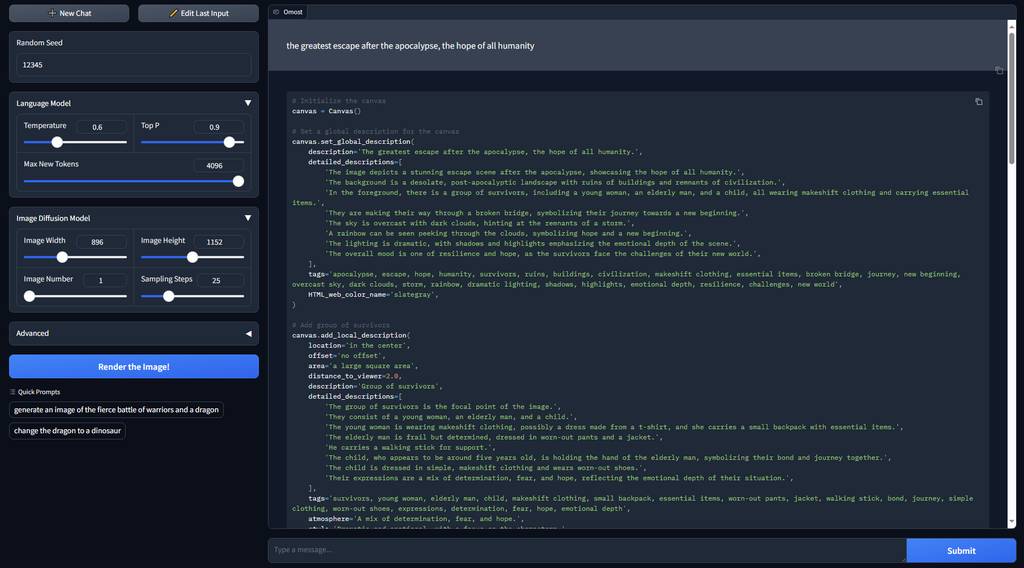
the greatest escape after the apocalypse, the hope of all humanity:
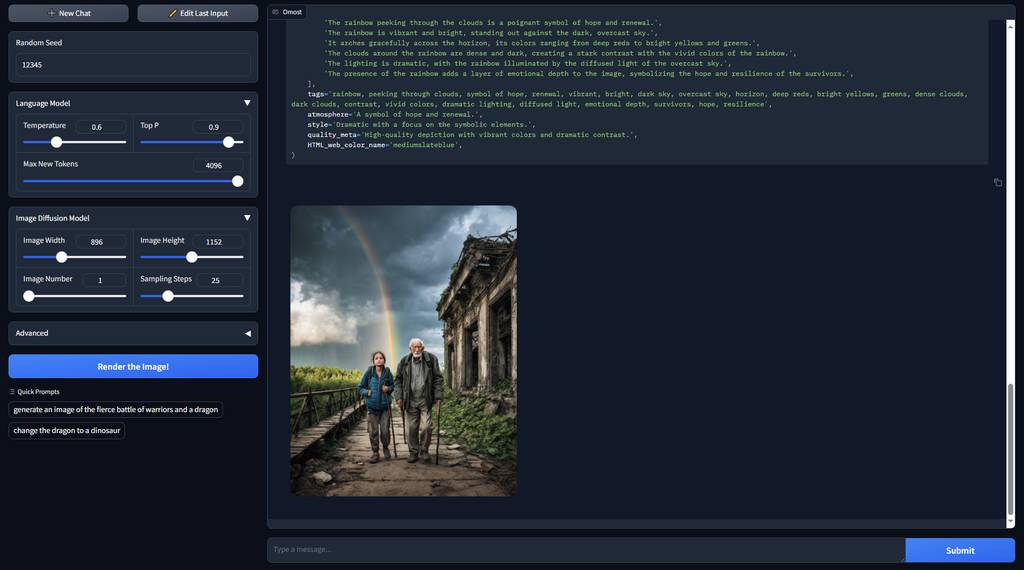
jurassic dinosaur battle:
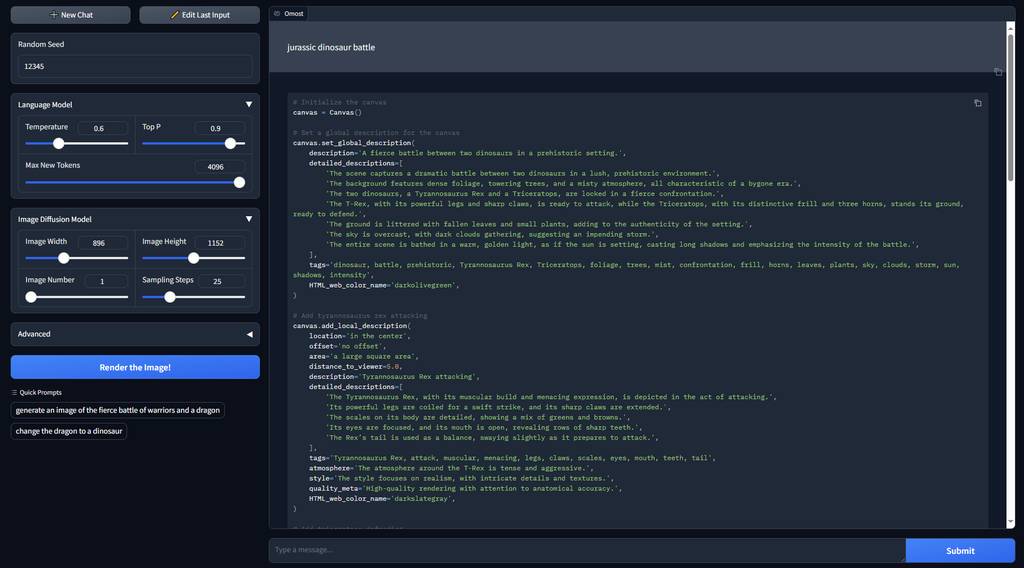
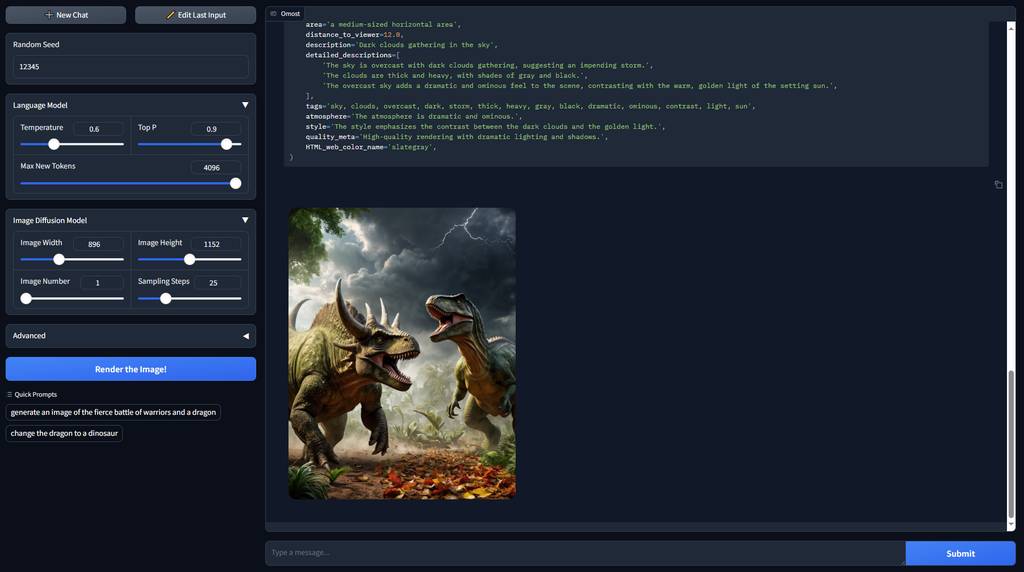
可以看到,输出的效果是非常好的,基本上,用上这个技术,普通人不需要煞费心思地去思考提示词,也可以输出质量不错且符合意图的图片了。
🤔 这样看,会不会跟LLM工具自动补全功能有点相似呢?
熟悉设计小站文章的小伙伴估计也看过我输出过类似的文章,把LLM语言大模型引入ComfyUI工作流中,帮忙补全提示词。
这些工作流都用到这个原理:
- 【AI辅助设计】如何让AI出图更接地气?一招教你去除“AI味”
- 【AI辅助设计】小孩子才做选择,语言大模型我全都要!
- 【AI辅助设计】只需要一句话就可以生成漫画
- 作为设计师,没灵感怎么办?这套免费的AI工作流送给大家
但似乎作者并不是简单地把LLM引入,而是做了一定的算法处理。
在使用前,我们也看看大致原理,懂不懂不重要,知道牛🐂 🍺就行😂
Omost技术原理
我尝试根据作者的项目,整理一下,如果有出入,请大家指正。
规范LLM参数
所有 Omost LLM 都经过训练以遵守以下符号。这样LLM就可以根据格式规范,进行语言理解和输出。
class Canvas:
def set_global_description(
self,
description: str,
detailed_descriptions: list[str],
tags: str,
HTML_web_color_name: str
):
pass
def add_local_description(
self,
location: str,
offset: str,
area: str,
distance_to_viewer: float,
description: str,
detailed_descriptions: list[str],
tags: str,
atmosphere: str,
style: str,
quality_meta: str,
HTML_web_color_name: str
):
assert location in [
"in the center",
"on the left",
"on the right",
"on the top",
"on the bottom",
"on the top-left",
"on the top-right",
"on the bottom-left",
"on the bottom-right"
]
assert offset in [
"no offset",
"slightly to the left",
"slightly to the right",
"slightly to the upper",
"slightly to the lower",
"slightly to the upper-left",
"slightly to the upper-right",
"slightly to the lower-left",
"slightly to the lower-right"
]
assert area in [
"a small square area",
"a small vertical area",
"a small horizontal area",
"a medium-sized square area",
"a medium-sized vertical area",
"a medium-sized horizontal area",
"a large square area",
"a large vertical area",
"a large horizontal area"
]
assert distance_to_viewer > 0
pass
规范的范围有如下:
- 功能:Canvas.set_global_description和Canvas.add_local_description
- 参数:描述和detailed_descriptions
- 参数:位置、偏移量、面积
- 参数:distance_to_viewer和HTML_web_color_name
- 参数:标签和氛围以及风格和quality_meta
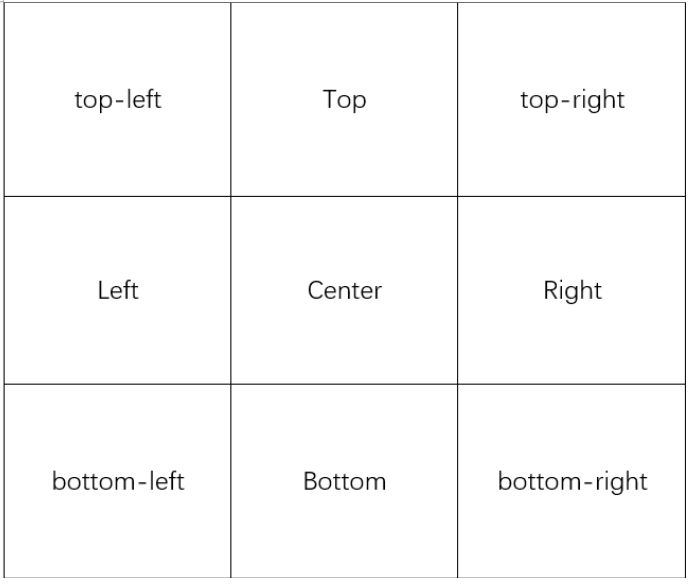
参数:位置、偏移量、面积
作者把画布分为3x3=9个位置。
然后进一步将每个位置划分为 33 个偏移量,得到 99=81 个位置:
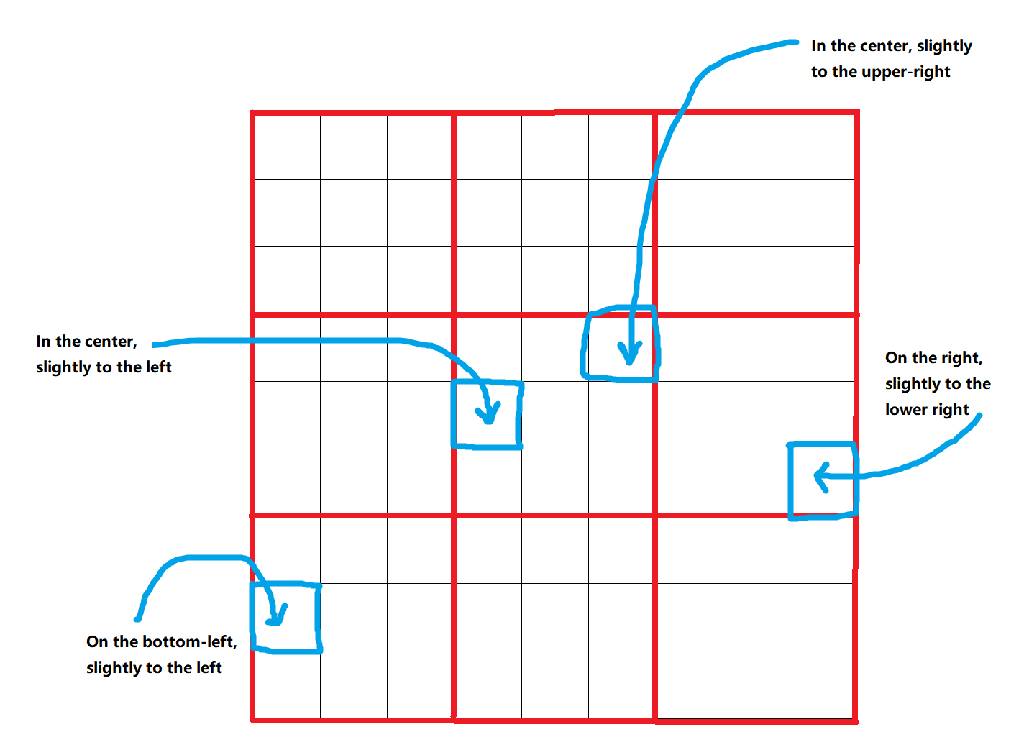
以这些位置为中心,进一步定义了 9 种类型的边界框:

这种方法允许 999=729 个不同的边界框,几乎涵盖了图像中对象的所有常见可能位置。
这样的目的是在于让LLM绘制各个区域的画面细节,从而达到丰富画面的效果。
不得不说,真是高明 👍
参数:distance_to_viewer和HTML_web_color_name
这个参数,我理解是把深度参数转化为LLM可以描述和识别的方式。
distance_to_viewer可以看作是相对深度。请注意,此值的绝对数根本不可靠(因为开源 LLM 不太擅长生成图像空间数字),它应该只用于将元素排序到背景到前景层。
在使用扩散模型渲染所有局部元素之前,始终可以使用 distance_to_viewer 对它们进行排序。全局描述始终可以被视为最远的背景图层。
通过结合distance_to_viewer和HTML_web_color_name,您可以绘制出非常粗糙的构图图像。例如,如果 LLM 运行良好,“在黑暗的房间里,木桌上的红瓶子前面有一个绿色瓶子”应该可以让你计算出如下图像:

参数:标签和氛围以及风格和quality_meta
这些标签被设计为描述的可能替代品,因为许多扩散模型更喜欢标签。如果与动漫模型一起使用,可能会对一些逻辑进行硬编码,以将所有”女孩”替换为”1女孩”。如果与 Pony 一起使用,那么可能总是硬编码添加”score_9,score_8…”对此。氛围、风格和quality_meta是一些实验参数,没有非常具体的用例。
目前,我们可以将它们视为子提示,并将它们参与到子提示包的贪婪合并中。在我的实验中,这将稍微改善气氛和质量。
基线渲染器
通过注意力评分机制,引导LLM产出更符合意图的元素。
Omost提供了基于注意力操作的 Omost LLM 的基线渲染。
作者基于**注意力评分操作**的方法:
这是一种更高级的方法。它直接操纵注意力分数,以确保鼓励掩蔽每个区域的激活,并阻止掩蔽之外的激活。该公式类似于
y=softmax(modify(q@k))@v其中modify()是一个复杂的非线性函数,具有许多归一化和改变分数分布的技巧。这种方法超越了简单的屏蔽注意力,真正确保这些层得到想要的激活。一个典型的例子是密集扩散。
编写了一个新的基线公式。他认为这种无参数公式是一个非常标准的基线实现,几乎会引入零样式偏移或质量下降。
区域提示器
原理大致如下:
让我们考虑一个只有 2*2=4 像素的极其简化的图像
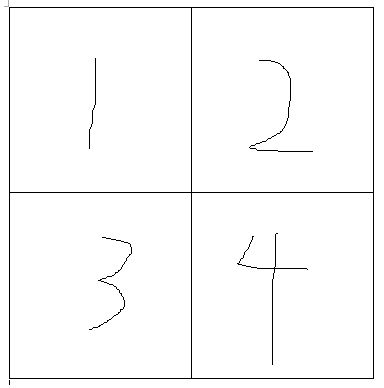
然后我们有三个提示”两只猫”、“一只黑猫”、“一只白猫”,我们有他们的面具:

然后我们可以画出这个注意力得分表:
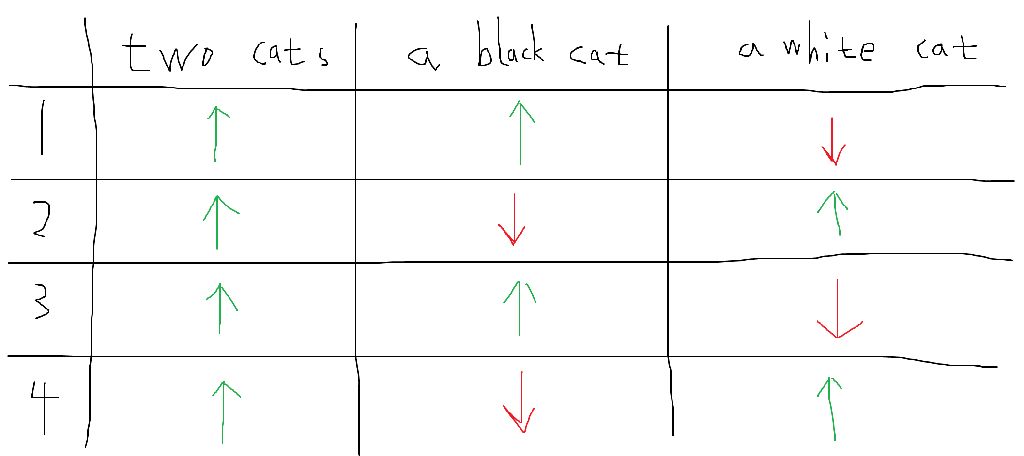
其中,上面的箭头表示我们想要鼓励激活,而下面的箭头表示我们想要摆脱这些激活。
此操作直接修改注意力分数,并在单个 SDP 注意力传递中计算所有提示条件。
提示前缀树
这个算法,是整合提示语链路关系并分别加工细节,提升准确性。
作者还加入了另一个技巧,这个技巧可以大大提高提示理解,称它为提示前缀树。其动机是,既然现在我们所有的提示都是可以任意合并的子提示(回想一下,所有子提示严格少于 75 个标记,通常少于 40 个标记,描述独立的概念,并且可以任意合并为剪辑编码的常见提示),找到一种更好的方法来合并这些子提示可能会改善结果并提示解释。
例如,下面是全局/局部整体/详细描述的树结构。
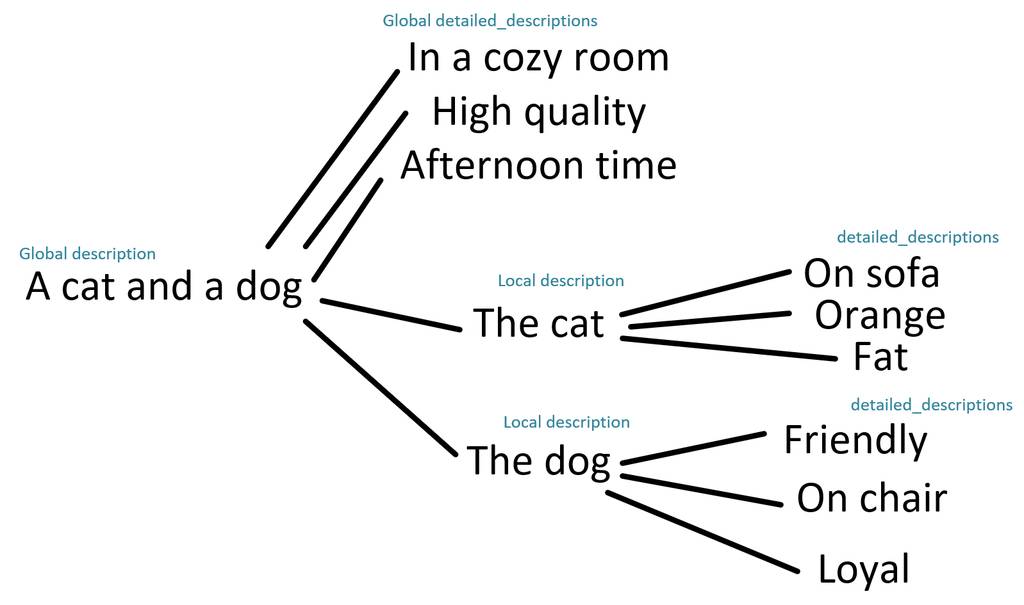
这个想法是,由于所有子提示都可以任意合并,因此我们可以将此树形图中的路径用作提示。
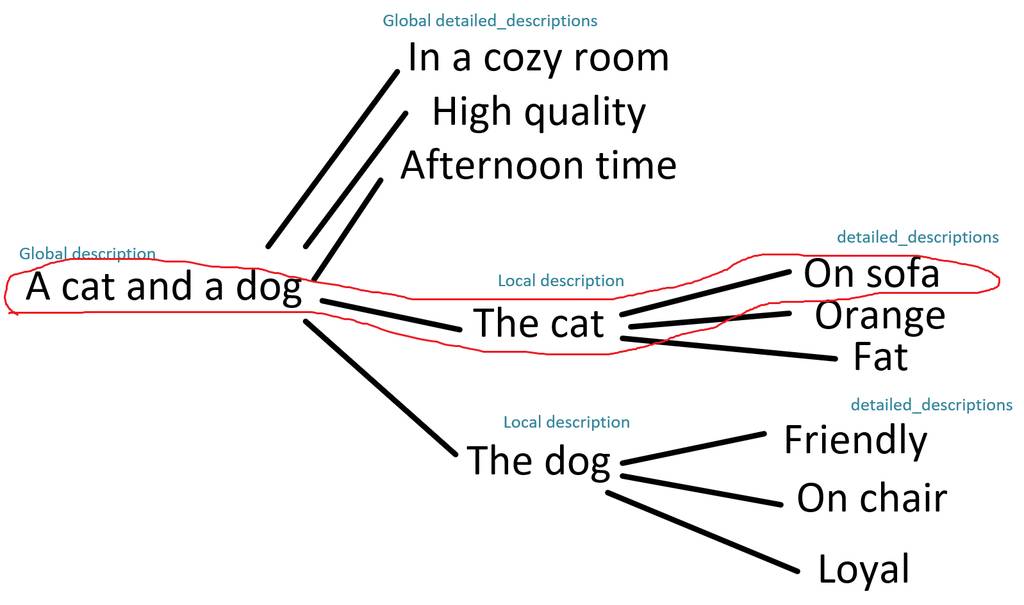
例如,下面的路径将给出提示”一只猫和一只狗。沙发上的猫。
好复杂,看不懂没关系,作为设计师,知道怎么用就可以了。
如何使用
目前作者提供源码方式,可以直接拉取下来部署使用。
当然,也可以用抱脸上的地址进行快速体验。https://huggingface.co/spaces/lllyasviel/Omost
可以使用以下方式部署(需要 8GB Nvidia VRAM):
git clone https://github.com/lllyasviel/Omost.git
cd Omost
conda create -n omost python=3.10
conda activate omost
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
python gradio_app.py
需要下载很多的模型:
测试效果
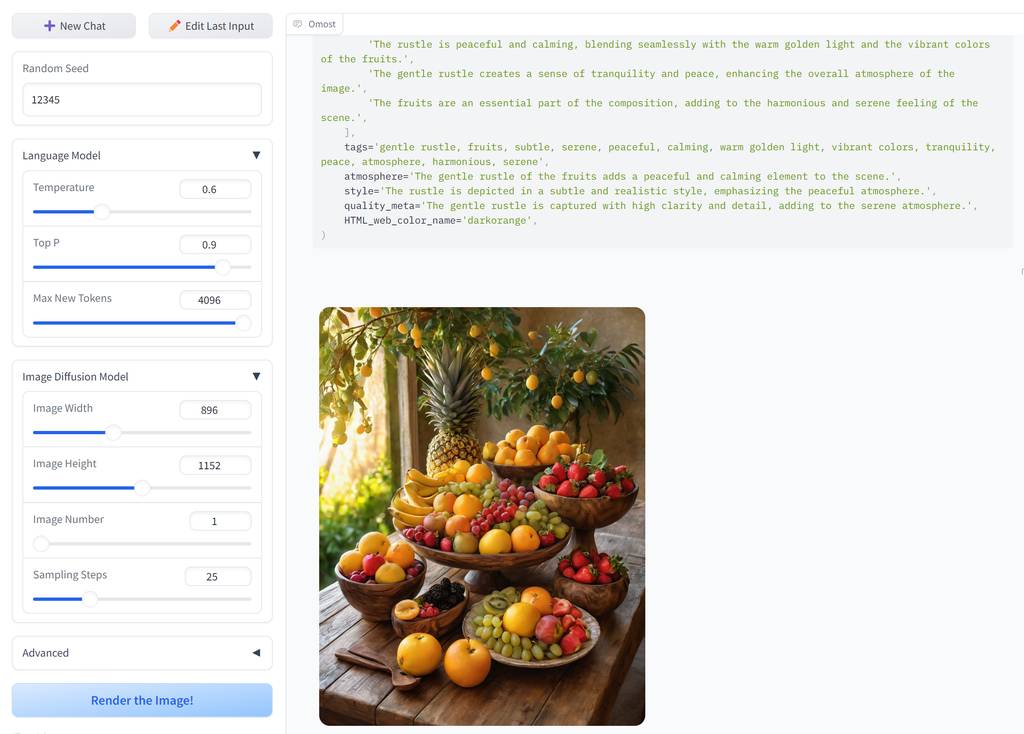
我们使用普通的SDXL工作流,输入同一个提示语,看两者有什么差别。 以下图片,左边为普通SDXL输出,右边为Omost输出。
吉普赛女孩
A gypsy girl

南非节日
South American festivals

窗台上的猫
a cat on the windowsill

翩翩起舞的中国女孩
Chinese girls dancing gracefully

丰盛的水果餐
A sumptuous fruit meal

画面的细节和氛围感,Omost是非常好了,无脑出好图指日可待!期待大神们整合到ComfyUI工作流,或者webui中。
关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。