5分钟阅读
最近值得关注的几个AI消息

前言
已经有很多天没有整理AI方面的最新消息了,今天为大家总结一下。 有以下几条AI信息值得大家关注:
- novitalabs开源了AnimateAnyone的代码。一张图可以生成动画!
- RectifID 技术开源,不用训练LoRA就可以保持一致性的解决方案
- Ocular AI开源。由YC投资的Ocular AI开源了部分代码,可以部署类似perplexity的AI搜索产品。
- tencent-ailab发布V-Express,一个类似阿里EMO的图片生成视频,再到嘴型同步的方案。
novitalabs开源了AnimateAnyone的代码
概述
AnimateAnyone这个项目发布有一段时间了,但是其核心代码一直没有公布。 最近,novitalabs把他们开源了。此存储库目前提供Animate Everyone的非官方预训练权重和推理代码。它受到MooreThreads/Moore-AnimateAnyone存储库实现的启发,我们对训练过程和数据集进行了一些调整。
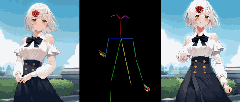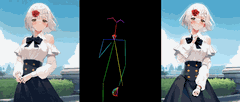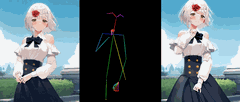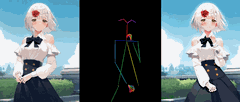

快速开始
构建环境
推荐使用python版本>=3.10和cuda版本=11.7,然后搭建环境如下:
# [Optional] Create a virtual env
python -m venv .venv
source .venv/bin/activate
# Install with pip:
pip install -r requirements.txt
下载权重
自动下载:您可以运行以下命令来自动下载权重:
python tools/download_weights.py
权重将放置在./pretrained_weights目录下。整个下载过程可能需要很长时间。
推理
以下是运行推理脚本的 cli 命令:
python -m scripts.pose2vid --config ./configs/prompts/animation.yaml -W 512 -H 784 -L 64
您可以参考的格式来animation.yaml添加自己的参考图像或姿势视频。要将原始视频转换为姿势视频(关键点序列),您可以运行以下命令:
python tools/vid2pose.py --video_path /path/to/your/video.mp4
RectifID 技术开源
该技术论文地址:https://arxiv.org/pdf/2405.14677
论文摘要如下
RectifID:个性化修正流与锚定分类器引导
摘要: 本文介绍了RectifID,这是一种无需训练即可定制扩散模型的技术,用于从用户提供的参考图像生成保持身份特征的图像。该方法利用分类器引导和修正流框架实现灵活的个性化,无需针对特定领域的广泛训练。
主要贡献:
- 基于分类器引导的固定点公式,提出了一种无需训练即可个性化修正流的方法。
- 将流轨迹锚定到参考轨迹上,以提高稳定性并提供理论上的收敛保证。
- 在人脸、活体主体和特定对象的各种个性化任务中实现了优势结果,并进行了实施和演示。
引言: 扩散模型的最新进展促进了对其可定制性的研究,特别是在个性化图像生成方面。然而,现有方法在身份保持和灵活性方面受到限制,因为它们需要额外的微调或预训练阶段。
方法:
- RectifID建立在修正流框架上,该框架具有强大的理论属性,如其采样轨迹的直线度。
- 该方法将原始分类器引导重新表述为一个简单的固定点问题,克服了对特殊噪声感知分类器的依赖。
- 提出了一种新的锚定分类器引导,以提高求解过程的稳定性。
应用: RectifID针对实际的修正流类别进行了实施,该类别被假设为分段直线,并与面部或对象鉴别器结合使用。它为人脸、活体主体、特定对象和多主体的个性化任务提供了灵活性。
实验:
- 该方法不涉及训练数据,仅在测试时操作。
- 在CelebA-HQ和DreamBooth数据集上进行了以人脸为中心和以主体为驱动的生成评估。
- 指标包括身份相似性、提示一致性和计算时间。
结果: RectifID在定量评估中实现了最先进的性能,无需训练,展示了更高的身份相似性和提示一致性。
结论: RectifID提出了一种使用锚定分类器引导的无需训练的个性化图像生成方法。它通过在修正流框架上开发并锚定流轨迹到参考轨迹,扩展了原始分类器引导的适用性,提高了求解稳定性。




安装使用
要求
- 安装 insightface、onnxruntime-gpu、onnx2torch、kornia、deepface 和PeRFlow的依赖项。
- 下载antelopev2并将
.onnx模型放在此文件夹中。 callback_on_step_end要使用2整流流,请InstaFlow/code/pipeline_rf.py根据此代码添加参数。
入门
-
对于单面个性化,运行以下命令:
python single_person.py --model FLOW_NAME --ref REF_IMAGE --prompt PROMPT_LIST --out OUT_IMAGE_LIST -
对于单个对象定制,运行以下命令:
python single_object.py --model FLOW_NAME --ref REF_IMAGE --ref_name REF_NAME --prompt PROMPT_LIST --out OUT_IMAGE_LIST -
或者,你可以自行探索 jupyter 笔记本:
- 单人:
single_person_perflow.ipynb和single_person_2rflow.ipynb - 单个对象:
single_object_perflow.ipynb和single_object_2rflow.ipynb - 多人:
multi_person_perflow.ipynb - 多对象:
multi_object_perflow.ipynb
- 单人:
-
对于以脸部为中心的生成,请在提示中包含触发词“人”,并可选择在末尾附加“,脸部”。
Ocular AI开源
有一个类perplexity的应用开源。
特征
- ** 类似 Google 的搜索界面 - 找到您所需内容。
- ** App MarketPlace - 连接到所有您喜爱的应用程序。
- ** 自定义连接器 - 构建您自己的连接器到专有数据源。
- ** 可定制的模块化基础设施 - 将您自己的定制 LLM、Vector DB 等带入 Ocular。
- ** 治理引擎 - 基于角色的访问控制、审计日志等。
在 Docker 中运行 Ocular
要在本地运行 Ocular,您除了需要设置 Ocular 之外,还需要设置 Docker。
先决条件
首先,确保你的设备上安装了 Docker。你可以从这里下载并安装它。
-
克隆 Ocular 目录。
git clone https://github.com/OcularEngineering/ocular.git && cd ocular -
在主目录中,打开
env.local添加所需的 OPEN AI 环境变量-
必需的密钥
- Open AI 密钥 - 要运行 Ocular,必须在后端设置 LLM 提供程序。默认情况下,Open AI 是 Ocular 的 LLM 提供程序,因此请添加 Open AI 密钥
env.local。 - 对其他 LLM 提供商的支持即将推出!
- Open AI 密钥 - 要运行 Ocular,必须在后端设置 LLM 提供程序。默认情况下,Open AI 是 Ocular 的 LLM 提供程序,因此请添加 Open AI 密钥
-
可选键
- 应用程序(Gmail|GoogleDrive|Asana|GitHub 等)- 要从应用程序中索引文档,必须为该特定应用程序设置 Api 密钥
env.local。请阅读我们的文档,了解如何设置每个应用程序。
- 应用程序(Gmail|GoogleDrive|Asana|GitHub 等)- 要从应用程序中索引文档,必须为该特定应用程序设置 Api 密钥
-
-
运行 Docker。
docker compose -f docker-compose.local.yml up --build --force-recreate
此命令初始化文件中指定的容器docker-compose.local.yml。完成此操作可能需要一些时间,具体取决于您的计算机和互联网连接。
该过程完成后docker compose,您应该会在 Docker 容器中启动并运行本地版本的 Ocular。您可以通过 访问它http://localhost:3001/create-account。
请记住,只要您正在使用本地 Ocular 实例,就保持 Docker 应用程序打开。
V-Express:用于肖像视频生成渐进式训练

可以让一张图说话的技术。
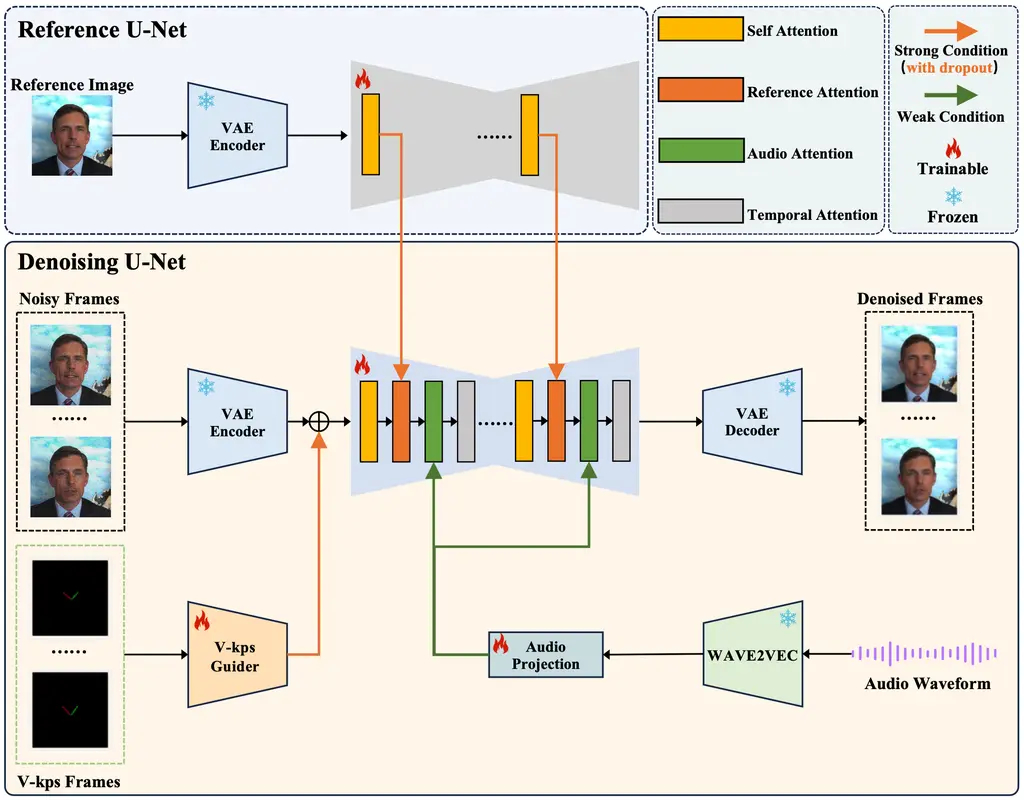
介绍
在人像视频生成领域,使用单张图片生成人像视频的做法越来越普遍。一种常见的方法是利用生成模型来增强可控生成的适配器。然而,控制信号的强度各不相同,包括文本、音频、图像参考、姿势、深度图等。其中,较弱的条件往往因较强条件的干扰而难以发挥作用,这对平衡这些条件提出了挑战。在我们关于人像视频生成的工作中,我们发现音频信号特别弱,常常被姿势和原始图像等较强的信号所掩盖。然而,直接用弱信号进行训练往往会导致收敛困难。为了解决这个问题,我们提出了 V-Express,这是一种简单的方法,它通过一系列渐进的丢弃操作来平衡不同的控制信号。我们的方法通过弱条件逐渐实现有效控制,从而实现同时考虑姿势、输入图像和音频的生成能力。
安装
# install requirements
pip install diffusers==0.24.0
pip install imageio-ffmpeg==0.4.9
pip install insightface==0.7.3
pip install omegaconf==2.2.3
pip install onnxruntime==1.16.3
pip install safetensors==0.4.2
pip install torch==2.0.1
pip install torchaudio==2.0.2
pip install torchvision==0.15.2
pip install transformers==4.30.2
pip install einops==0.4.1
pip install tqdm==4.66.1
# download the codes
git clone https://github.com/tencent-ailab/V-Express
# download the models
cd V-Express
git lfs install
git clone https://huggingface.co/tk93/V-Express
mv V-Express/model_ckpts model_ckpts
# then you can use the scripts
下载模型
您可以从这里下载模型。我们已将所有需要的模型包含在模型卡中。您也可以从原始存储库单独下载模型。
- 稳定性ai/sd-vae-ft-mse。
- runwayml/stable-diffusion-v1-5。这里只需要 unet 的模型配置文件。
- facebook/wav2vec2-base-960h。
- insightface/buffalo_l。
如何使用
重要提醒
重要!重要!重要!
在说话人脸生成任务中,当目标视频与参考人物不是同一个人时,人脸的重新定位将是非常重要的一环。而选择与参考人脸姿态更相似的目标视频将能够得到更好的结果。另外,我们的模型现在在英语上表现较好,其他语言还未进行详细测试。
运行演示(步骤 1,可选)
如果您有目标说话视频,您可以按照以下脚本从视频中提取音频和面部 V-kps 序列。您也可以跳过此步骤并直接运行步骤 2 中的脚本来尝试我们提供的示例。
python scripts/extract_kps_sequence_and_audio.py \
--video_path "./test_samples/short_case/AOC/gt.mp4" \
--kps_sequence_save_path "./test_samples/short_case/AOC/kps.pth" \
--audio_save_path "./test_samples/short_case/AOC/aud.mp3"
我们建议剪裁一张清晰的方形人脸图像,如下例所示,并确保分辨率不低于 512x512。下图中绿色到红色的框是建议的剪裁范围。

运行演示(步骤2,核心)
场景 1(A 的照片和 A 的说话视频。)(最佳实践)
如果你有一张 A 的照片和另一个场景中 A 的说话视频。那么你应该运行以下脚本。我们的模型能够生成与给定视频一致的说话视频。你可以在我们的项目页面上看到更多示例。
python inference.py \
--reference_image_path "./test_samples/short_case/AOC/ref.jpg" \
--audio_path "./test_samples/short_case/AOC/aud.mp3" \
--kps_path "./test_samples/short_case/AOC/kps.pth" \
--output_path "./output/short_case/talk_AOC_no_retarget.mp4" \
--retarget_strategy "no_retarget" \
--num_inference_steps 25
场景 2(A 的照片和任何说话的音频。)
如果您只有一张图片和任何会说话的音频。使用以下脚本,我们的模型可以为固定面部生成生动的嘴部动作。
python inference.py \
--reference_image_path "./test_samples/short_case/tys/ref.jpg" \
--audio_path "./test_samples/short_case/tys/aud.mp3" \
--output_path "./output/short_case/talk_tys_fix_face.mp4" \
--retarget_strategy "fix_face" \
--num_inference_steps 25
场景 3(A 的照片和 B 的说话视频。)
- 通过下面的脚本,我们的模型可以生成生动的嘴部动作并伴随轻微的面部运动。
python inference.py \
--reference_image_path "./test_samples/short_case/tys/ref.jpg" \
--audio_path "./test_samples/short_case/tys/aud.mp3" \
--kps_path "./test_samples/short_case/tys/kps.pth" \
--output_path "./output/short_case/talk_tys_offset_retarget.mp4" \
--retarget_strategy "offset_retarget" \
--num_inference_steps 25
- 通过以下脚本,我们的模型生成与目标视频具有相同动作的视频,并且角色的口型同步与目标音频相匹配。
目前我们只实现了非常简单的重定向策略,这使我们能够在有限的条件下使用不同的角色视频来驱动参考人脸。为了获得更好的结果,我们强烈建议您选择更接近参考人脸的目标视频。我们还在尝试实现更强大的人脸重定向策略,希望可以进一步解决参考人脸和目标人脸不一致的问题。我们也欢迎有经验的人来帮忙。
python inference.py \
--reference_image_path "./test_samples/short_case/tys/ref.jpg" \
--audio_path "./test_samples/short_case/tys/aud.mp3" \
--kps_path "./test_samples/short_case/tys/kps.pth" \
--output_path "./output/short_case/talk_tys_naive_retarget.mp4" \
--retarget_strategy "naive_retarget" \
--num_inference_steps 25
更多参数
对于不同类型的输入条件,例如参考图像和目标音频,我们提供参数来调整该条件信息在模型预测中所起的作用。我们将这两个参数称为 和reference_attention_weight。audio_attention_weight使用以下脚本可以应用不同的参数来实现不同的效果。Through our experiments, we suggest that reference_attention_weight takes the value 0.9-1.0 and audio_attention_weight takes the value 1.0-3.0.
python inference.py \
--reference_image_path "./test_samples/short_case/10/ref.jpg" \
--audio_path "./test_samples/short_case/10/aud.mp3" \
--output_path "./output/short_case/talk_10_fix_face_with_weight.mp4" \
--retarget_strategy "fix_face" \ # this strategy do not need kps info
--reference_attention_weight 0.95 \
--audio_attention_weight 3.0
好了,今天的介绍就到这里,有什么疑问或者问题,可以留言交流哦~ 关注我公众号(设计小站):sjxz00,获取更多AI辅助设计和设计灵感趋势。