5分钟阅读
建议精读!AI工程与艺术——与ComfyUI的comfyanonymous对话

本文翻译自 latent. Space 的播客文章。该播客近日采访了 ComfyUI 的作者comfyanonymous ,谈到了 ComfyUI 的开发的初心和目的,以及AIGC 相关的讨论,文章也给出了学习 ComfyUI 的资源(当然需要有条件的网络)。关注 ComfyUI 的朋友不妨都读一下,可以帮助大家理解和使用 ComfyUI。
译者按
翻译这篇文章,其实我还是蛮有感受的,最初在 2023 年 2 月接触 AIGC ,我是从 A1111 webui 开始的,当时用的还是 M1 Macbook,当我输入 1girl 的时候,立即生成一个虚拟女孩,那种惊喜,真的多年未有!
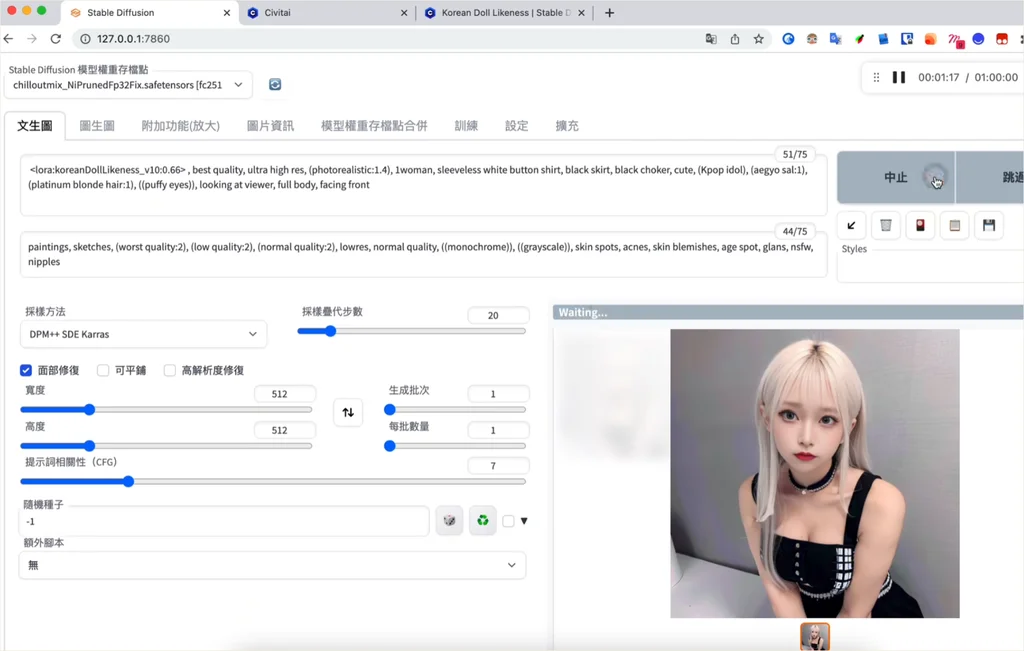
但是随着对 AI 的需求越来越高,需要的灵活性和功能日益增加,还有各种新模型的涌现和迭代,SD webui 明显落伍了,于是我便全面转到 ComfyUI 中来,后面就一直使用它作为本地的 AI 工具了😎。
甚至我把它用到了生成环境中,作为 AI 工具的后端!😂
译者摘要
其实,ComfyUI 不仅是用来出图的,而是一个系统的 AI 工具!
ComfyUI是一个基于节点的AI图像生成工具,由comfyanonymous开发。与传统的文本框输入方式不同,它采用DAG(有向无环图)的方式来构建工作流。虽然界面较复杂,但能够支持更高级的图像生成任务,如视频生成、3D建模等。ComfyUI不仅是一个UI工具,更是一个运行时,可以用来构建完整的AI艺术应用程序。
ComfyUI 是一个 AI 系统工具

ComfyUI 特点

原文翻译
AI 工程与艺术——与 ComfyUI 的 comfyanonymous 对话
当前时间:0:00 / 总时长:-55:03

AI 工程与艺术——与 ComfyUI 的 comfyanonymous 对话
使用模型进行“艺术工程”,构建难以使用的 UI,以及图像生成如何从文本框转向 DAG(有向无环图)
专注于工作中的智能体的纽约市 AI 工程师峰会的申请现已开放!
当我们最初创办 Latent Space 时,在闪电回合中,我们总是会问嘉宾:“你最喜欢的 AI 产品是什么?”大多数人会说 Midjourney。简单的 UI——输入提示→生成非常美观的图像——使其成为了一个年收入超过 3 亿美元的自主创业公司,乘上了 AI 图像生成的第一波浪潮。
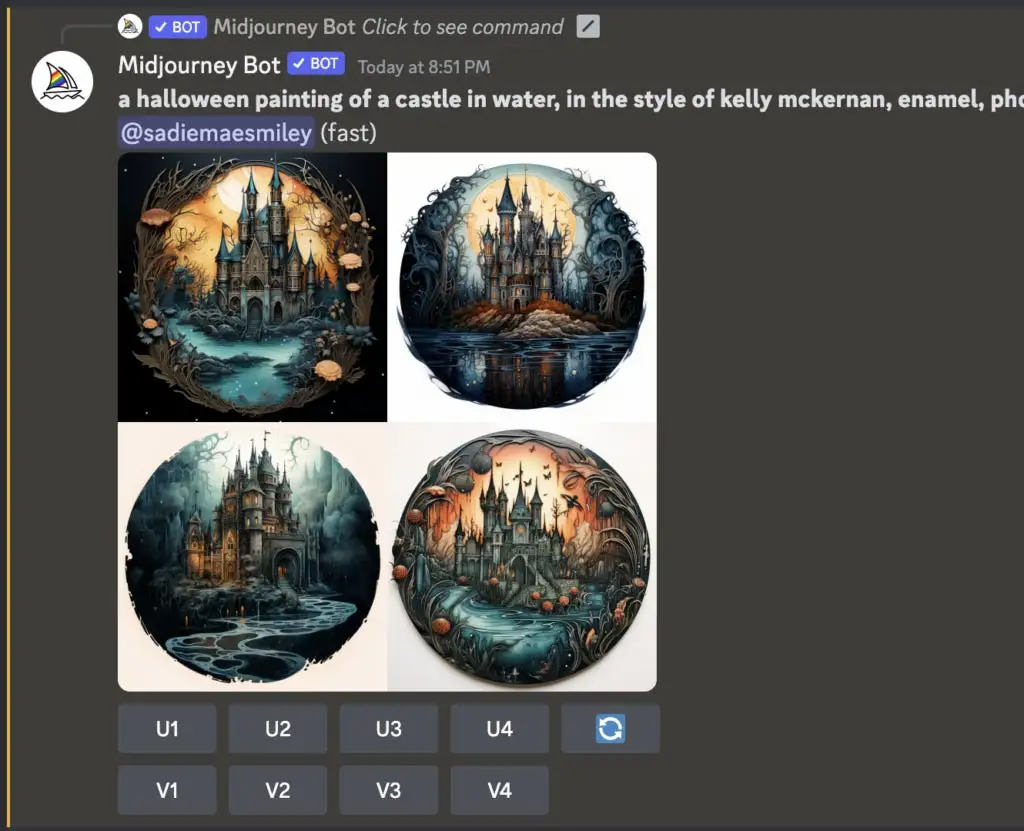
在开源领域,StableDiffusion 围绕 AUTOMATIC1111 聚集,成为事实上的 Web UI。与 Midjourney 不同,Midjourney 提供了一些标志,但主要是提示驱动的,而 A 1111 则让用户可以玩更多的参数,支持 img 2 img 等额外模式,并允许用户加载自定义模型。如果你对 SD 的历史感兴趣,可以看看我们与 Lexica、Replicate和Playground 的节目。
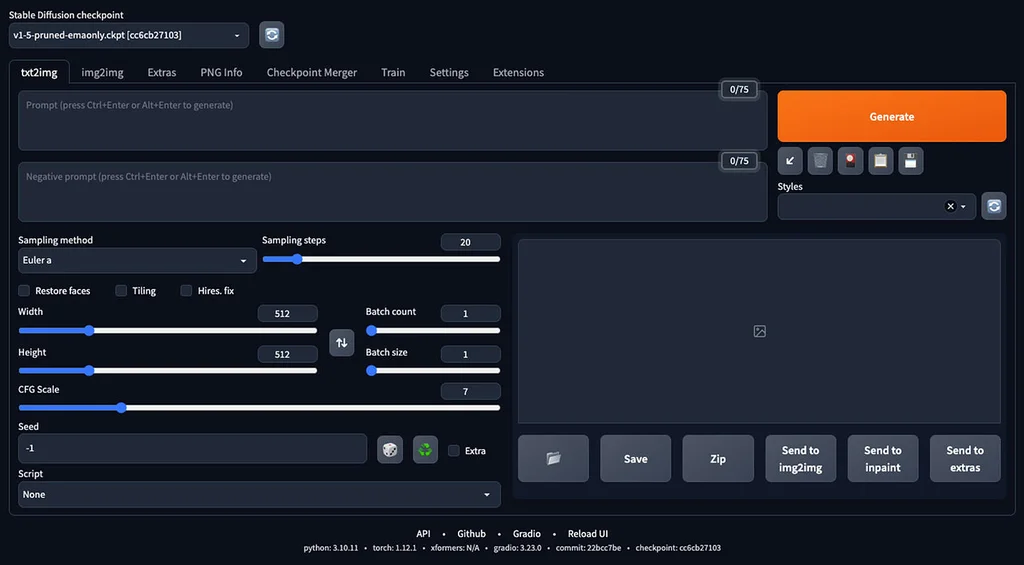
AUTOMATIC 1111 UI 的早期版本之一
参与该社区的其中一位是 comfyanonymous,他也在2023年成为Stability团队的一员,决定构建一个名为ComfyUI 的替代品,现在它是生成图像领域增长最快的开源项目之一,并且现在是**Black Forest Labs**的Flux Tools的首选合作伙伴。其背后的理念很简单:“每个人都在尝试制作易于使用的界面。让我尝试制作一个功能强大但不易使用的界面。”
与它的前辈不同,ComfyUI 没有输入文本框。一切都基于节点的概念:有一个文本输入节点、一个 CLIP 节点、一个检查点加载器节点、一个 KSampler 节点、一个 VAE 节点等。虽然对于简单的图像生成来说可能有些吓人,但该工具对于更复杂的工作流程非常出色,因为你可以分解流程的每一步,然后将它们中的许多链接在一起,而不是手动在工具之间切换。你还可以从中间重新开始执行,而不是从头开始,这在使用较大模型时可以节省大量时间。
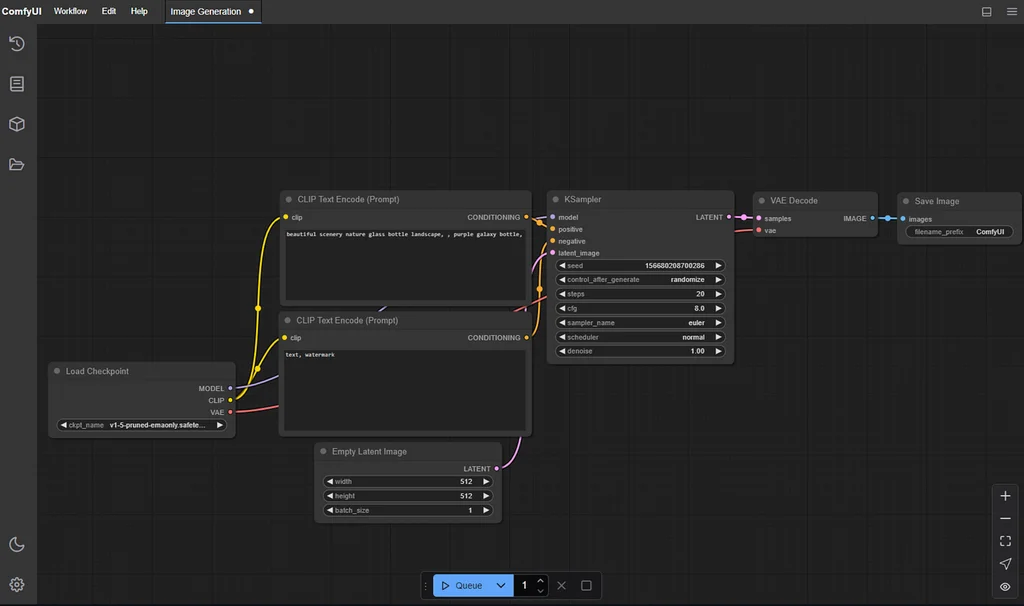
为了让你了解这种 UI 启用的一些新用例:
- 绘制草图→从草图中生成 SD 图像→将其输入 SD Video 进行动画制作
- 生成物体图像→转换为 3 D 资产→输入到交互式体验中
- 输入音频→生成音频反应视频
他们的示例页面还包括一些更常见的用例,如 AnimateDiff 等。他们最近推出了 Comfy Registry,这是一个在线库,用户可以从中提取不同的节点,而不必从头开始构建所有内容。该项目在 Github 上有超过 60,000 颗星,随着社区的发展,人们构建的一些项目变得相当复杂:
![ComfyUI] 我觉得更复杂的工作流程并不会提高质量 :
r/StableDiffusion](https://substackcdn.com/image/fetch/w_1456, c_limit, f_auto, q_auto: good, fl_progressive: steep/https%3 A%2 F%2 Fsubstack-post-media. S 3. Amazonaws. Com%2 Fpublic%2 Fimages%2 Fdda 28581-37 c 8-44 da-8822-57 d 1 ccc 2118 c_2130 x 1658. Png)
关于 Comfy 最有趣的是,**它不是一个 UI,而是一个运行时。**你可以通过在图像模型上使用 Comfy 来构建完整的应用程序。你可以将 Comfy 工作流作为端点暴露出来,并将它们链接在一起,就像你链接单个节点一样。我们正在看到 AI 工程应用于艺术的兴起。
来自 Latent Space Discord 的 Major Tom 的 ComfyUI 资源
特别感谢 LS Discord 上的Major Tom,他是一位图像生成专家,提供了以下建议:
-
“Comfy 最好的地方在于它几乎立即支持所有新发布的东西——不像 A 1111 或 forge,它们仍然不支持 flux cnet。当冲突节点解决后,它将成为完美的工具”
-
Alessandro Perili的AP工作流是一个很好的例子,展示了在 Comfy 上构建的一体化训练-评估-生成系统
-
学习 ComfyUI 的 YouTubers:
-
值得关注的 ComfyUI 节点:
-
https://github.com/PowerHouseMan/ComfyUI-AdvancedLivePortrait
-
Sarav: https://www.youtube.com/@mickmumpitz/videos (应用类内容)
-
Sarav: https://www.youtube.com/@latentvision (技术类,但不频繁)
-
寻找 comfyui 节点以支持 https://github.com/magic-quill/MagicQuill
-
“Comfy for Video”资源
-
Kijai (https://github.com/kijai) 正在推出对 Mochi、CogVideoX、AnimateDif、LivePortrait 等的支持
-
Comfyui 节点支持如 LTX https://github.com/Lightricks/ComfyUI-LTXVideo 和 HunyuanVideo
-
社区: https://www.reddit.com/r/StableDiffusion/, https://www.reddit.com/r/comfyui/
完整视频
一如既往,你可以在我们的 YouTube 上找到完整视频节目(别忘了点赞和订阅!)
时间戳
- 00:00:04 主持人介绍和匿名嘉宾
- 00:00:35 Comfy UI 的起源和早期 Stable Diffusion 的格局
- 00:02:58 Comfy 的背景和高分辨率修复的开发
- 00:05:37 图像生成中的区域条件和合成
- 00:07:20 讨论不同的 AI 图像模型(SD、Flux 等)
- 00:11:10 闭源模型 API 和社区对 SD 版本的讨论
- 00:14:41 图像生成中的 LoRAs 和文本反转
- 00:18:43 Comfy 社区中的评估方法
- 00:20:05 图像生成中的 CLIP 模型和文本编码器
- 00:23:05 提示权重和负面提示
- 00:26:22 Comfy UI 的独特功能和设计选择
- 00:31:00 Comfy UI 中的内存管理
- 00:33:50 GPU 市场份额和兼容性问题
- 00:35:40 Comfy UI 中的节点设计和参数设置
- 00:38:44 自定义节点和社区贡献
- 00:41:40 视频生成模型和功能
- 00:44:47 Comfy UI 的开发时间线和流行度上升
- 00:48:13 Comfy UI 团队的现状和未来计划
- 00:50:11 讨论其他 Comfy 初创公司和潜在的文本生成支持
文字版
Alessio [00:00:04]: 大家好,欢迎来到 Latent Space 播客。我是 Alessio,Decibel Partners 的合伙人和 CTO,我和我的联合主持人 Swyx 一起,他是 Small AI 的创始人。
swyx [00:00:12]: 大家好,我们再次在 Chroma Studio,但这次我们迎来了第一位匿名嘉宾,Comfy Anonymous,欢迎。
Comfy [00:00:19]: 你好。
swyx [00:00:21]: 我觉得这是你的全名,你就叫 Comfy,对吧?
Comfy [00:00:24]: 是的,很多人就叫我 Comfy,即使他们知道我的真名。嘿,Comfy。
Alessio [00:00:32]: Swyx 也是一样。你知道,很多人不叫你 Shawn。
swyx [00:00:35]: 是的,你有一个专业名字,人们知道你的名字,然后你有一个法律名字。是的,没关系。我该怎么表达呢?我觉得懂行的人都知道 Comfy 是图像生成和其他多模态内容的工具。我想说,当我刚开始接触 Stable Diffusion 时,明星产品是 Automatic 111,对吧?我实际上回顾了 2022 年左右的笔记,Comfy 那时已经开始崭露头角,但它更像是后来者,你的主要功能是流程图。你能回顾一下那个时刻,那一年,你是如何看待当时的格局并决定开始 Comfy 的吗?
Comfy [00:01:10]: 是的,我在 2022 年 10 月发现了 Stable Diffusion。然后我开始玩它。是的,我一开始用的是 Automatic,那时大家都在用。所以我从那里开始,因为当我开始时,我对 Diffusion 一无所知。我不知道 Diffusion 模型是如何工作的,也不知道这些东西是如何运作的,所以。
swyx [00:01:36]: 哦,是的。你之前的工程师背景是什么?
Comfy [00:01:39]: 只是一个软件工程师。是的。无聊的软件工程师。
swyx [00:01:44]: 但是,有没有任何图像处理、编排、分布式系统、GPU 的经验?
Comfy [00:01:49]: 没有,我基本上没做过什么有趣的事情。Crud,Web 开发?是的,很多 Web 开发,只是,是的,一些基本的,也许是一些基本的自动化工作。好吧。只是。是的,没有大公司或任何东西。
swyx [00:02:08]: 是的,但已经对自动化有一些兴趣,可能有很多 Python。
Comfy [00:02:12]: 是的,是的,当然,Python。但在我开始 Comfy UI 之前,我并不习惯节点图界面。我只是觉得,哦,什么是最好的方式来在用户界面中表示 Diffusion 过程?然后,哦,好吧。自然地,哦,这是我找到的最好的方式。这就是节点界面。所以我是怎么开始的呢,是的,2022 年 10 月,就像我之前没有写过一行 PyTorch 代码。所以完全是新手。发生的事情是我对生成图像上瘾了。
Alessio [00:02:58]: 我们都一样。是的。
Comfy [00:03:00]: 然后我开始。我开始在 auto 中试验高分辨率修复,对于那些不知道的人来说,高分辨率修复只是因为在那个时候 Diffusion 模型只能生成低分辨率的图像。所以你要做的是生成低分辨率图像,然后放大,然后再细化。这是生成高分辨率图像的技巧。我真的很喜欢生成。更高分辨率的图像。所以我开始试验。所以我修改了一些代码。好吧。如果我在第二遍使用不同的采样器会发生什么,我编辑了 auto 的代码。所以如果我使用不同的采样器会发生什么?如果我使用不同的设置,不同的步数会发生什么?因为那时候。高分辨率修复非常基础,只是,所以。是的。
swyx [00:04:05]: 现在有一个完整的库,只是,呃,上采样器。
Comfy [00:04:08]: 我想,我想他们后来在高分辨率修复中添加了很多选项,呃,自从,呃,自从,自从那时起。但在此之前,它非常基础。所以我想更进一步。我想试试。如果我在第二遍使用不同的模型会发生什么?然后,好吧,然后 auto 的代码库不够好。就像,在 auto 界面中实现它会比创建我自己的界面更难。所以那时我决定创建自己的界面。你开始的时候主要是自己做的,还是已经有一群人了?不,我,呃,自己做的,因为,因为只是我在试验一些东西。所以是的,就是这样。然后,所以我从 2023 年 1 月 1 日开始写代码。然后我在 2023 年 1 月 16 日在 GitHub 上发布了第一个版本。事情就是这样开始的。
Alessio [00:05:11]: 名字是什么?一开始就叫 Comfy UI 吗?是的。
Comfy [00:05:14]: Comfy UI。名字的原因,我的名字是 Comfy,因为人们觉得我的图片很舒适,所以我只是,呃,就把它命名为,呃,我的 Comfy UI。所以是的,呃,
swyx [00:05:27]: 你有没有针对特定的社区用户?比如更密集的工作流艺术家,你知道,与 automatic 用户相比,或者,你知道,
Comfy [00:05:37]: 这是我试验新事物的方式,比如我提到的高风险修复,就像在 Comfy 中,你首先可以轻松地做的是将不同的模型链接在一起。然后其中一个第一次获得一些流行度的事情是当我开始试验不同的,比如应用。提示到图像的不同区域。是的。我称之为区域条件,发布在 Reddit 上,获得了很多赞。所以我想那是,像,人们第一次知道 Comfy UI 的时候。
swyx [00:06:17]: 主要是修复手吗?
Comfy [00:06:19]: 呃,不,不,不。那只是,比如说,这仍然有点难。比如你想要一座山,你有一张图片,然后,好吧。我就想,好吧。我想要山在这里,我想要,比如说,一只狐狸在这里。
swyx [00:06:37]: 是的。所以是图像合成。是的。
Comfy [00:06:40]: 我的方法非常简单。就像,哦,当你运行扩散过程时,你会生成,好吧。你每次通过扩散进行一次传递,每一步你都会进行一次传递。好吧。这张图片的这个位置有这个品牌,这个空间,图片的这个位置有另一个道具。然后。整张图片有另一个道具,然后每一步都把所有东西平均在一起,这就是,呃,我称之为区域合成。然后,一个月后,有一篇论文出来了,叫做多扩散,它是一样的东西,但,是的,那就是,呃,
Alessio [00:07:20]: 你能用不同的模型进行区域合成吗?还是因为你是在平均,所以你需要相同的模型。
Comfy [00:07:26]: 可以用不同的模型,但,是的,我还没有实现。对于不同的模型,但,呃,你可以用,呃,如果你想的话,可以用不同的模型,只要这些模型共享相同的潜在空间,就像我们,我们每次有人说的时候都应该敲个钟,比如说,你不能用 Excel 和 SD 1.5,因为它们有不同的潜在空间,但,呃,是的,比如 SD 1.5 模型,不同的模型。你可以,你可以做到。
swyx [00:07:59]: 有些模型尝试在像素空间中工作,对吧?
Comfy [00:08:03]: 是的。它们非常慢。当然。这就是问题所在。这就是为什么稳定扩散实际上变得如此受欢迎的原因,因为潜在空间。
swyx [00:08:14]: 小而且是的。因为它曾经是潜在扩散模型,然后他们训练了它。
Comfy [00:08:19]: 是的。因为像素扩散模型太慢了。所以。是的。
swyx [00:08:25]: 你有没有尝试过和像,像 Stability,潜在扩散的那些人谈谈,比如,你知道,Robin Rombach,那帮人。是的。
Comfy [00:08:32]: 嗯,我曾经在 Stability 工作。
swyx [00:08:34]: 哦,我其实不知道。是的。
Comfy [00:08:35]: 我曾经在 Stability 工作。我,呃,我在 2023 年 6 月被雇佣。
swyx [00:08:42]: 啊,这是我不知道的部分。好的。是的。
Comfy [00:08:46]: 所以,我被雇佣的原因是因为他们当时在做 SDXL,他们基本上是在做 SDXL。我不知道你是否记得,它是一个基础模型,然后是一个精炼模型。基本上他们想实验,比如把它们链接在一起。然后,呃,他们看到了,哦,对了。哦,这个,我们可以用这个来做那个。好吧,让我们雇佣那个人。
swyx [00:09:10]: 但他们没有,他们没有为 SD 3 继续这样做。你是什么意思?像 SDXL 的方法。是的。
Comfy [00:09:16]: 这种方法的原因是基本上他们有两个模型,然后他们想发布这两个模型。所以他们,他们训练了一个在较低的时间步长上,这是精炼模型。然后他们,第一个模型是正常训练的。然后他们在测试过程中发现,哦,如果我们把这些模型串在一起,质量会提高。所以让我们发布这个。它奏效了。是的。但现在,我不认为很多人还在使用精炼模型,尽管它实际上是一个完整的扩散模型。你可以单独使用它。它会生成图像。我不认为有人,人们大多已经忘记了它。但,呃。
Alessio [00:10:05]: 我们能稍微谈谈模型吗?所以稳定扩散显然是最知名的。我知道 Flux 已经获得了很大的关注。有没有一些被低估的模型人们应该更多地使用,或者现在的情况如何?
Comfy [00:10:17]: 嗯,最新的,呃,最先进的,至少,是的,对于图像来说,有,呃,是的,有 Flux。还有 SD 3.5。SD 3.5 是两个模型。有一个小的,2.5 B,还有一个大的,8 B。所以它比 Flux 小。所以,而且它在某种程度上更有创意,但 Flux,是的,Flux 是最好的。人们应该试试 SD 3.5,因为,呃,它不一样。我不会说它更好。嗯,它在某些特定用例中更好。对吧。如果你想做一些更有创意的东西,也许 SD 3.5。如果你想做一些更一致的东西,Flux 可能更好。
swyx [00:11:06]: 你有没有考虑过支持闭源模型的 API?
Comfy [00:11:10]: 呃,嗯,他们,我们确实支持它们作为自定义节点。我们实际上有一些,呃,官方的自定义节点来自,呃,不同的。Ideogram。
swyx [00:11:20]: 是的。我想 DALI 会有一个。是的。
Comfy [00:11:23]: 那是,呃,只是不是我负责的人。当然。
swyx [00:11:28]: 当然。关于 SD 的快速问题。有很多社区讨论关于从 SD 1.5 到 SD 2,然后从 SD 2 到 SD 3 的过渡。人们仍然非常忠诚于前几代的 SD?
Comfy [00:11:41]: 呃,是的。SD 1.5 仍然有很多用户。
swyx [00:11:46]: 最后一个基础模型。
Comfy [00:11:49]: 是的。然后 SD 2 大多被忽略了。它没有,呃,它没有比前一个模型有足够的改进。好吧。
swyx [00:11:58]: 所以 SD 1.5,SD 3,Flux 和其他什么。SDXL。SDXL。
Comfy [00:12:03]: 那是主要的。稳定级联。稳定级联。那是一个好模型。但,呃,问题是,呃,它得到了,呃,像 SD 3 在一周后宣布。是的。
swyx [00:12:16]: 那是一个奇怪的发布。呃,在 Stability 内部是什么样子的?我是说,诉讼时效。是的。诉讼时效已经过期了。你知道,管理层已经换了。所以现在更容易谈论了。是的。
Comfy [00:12:27]: 在 Stability 内部,实际上那个模型在三个月前就准备好了,但它被卡在了,呃,红队测试中。所以基本上,如果那个模型发布了,或者应该由作者发布,那么它可能会变得非常流行,因为它比 SDXL 更进一步。但它所有的势头都被 SD 3 的宣布偷走了。所以人们没有在上面开发任何东西,尽管它,呃,是的。它是一个好模型,至少,呃,完全被忽略了,出于某种原因。像
swyx [00:13:07]: 我认为命名也很重要。它看起来像是主要开发树的一个分支。是的。
Comfy [00:13:15]: 嗯,那是不同的研究人员做的。是的。是的。非常像,呃,好模型。像是 Worcestershire 的作者。我不知道我是否发音正确。是的。是的。是的。
swyx [00:13:28]: 我其实在维也纳见过他们。是的。
Comfy [00:13:30]: 他们在 Stability 工作了一段时间,然后在 Cascade 发布后离开了。
swyx [00:13:35]: 这是 Dustin,对吧?不。呃,Dustin 是 SD 3。是的。
Comfy [00:13:38]: Dustin 是 SD 3 SDXL。那是,呃,Pablo 和 Dome。我想我发音正确。是的。是的。是的。是的。那很好。
swyx [00:13:51]: 看起来社区非常,他们行动非常迅速。是的。当有新模型出来时,他们就会放下当前的模型。然后他们全部转移过去。他们不会留下来探索全部功能。如果稳定级联那么好,他们会多做些 AB 测试。相反,他们就像,好吧,SD 3 出来了。我们走吧。你知道吗?
Comfy [00:14:11]: 嗯,我发现实际上相反。社区不喜欢,他们只在新模型有显著改进时才会跳上去。如果只有增量改进,这是大多数这些模型会有的,特别是如果你,因为,呃,保持相同的参数数量。是的。除非有什么大的变化,否则你不会得到巨大的改进。所以,呃。是的。
swyx [00:14:41]: 他们如何评估这些改进?因为,你知道,这是一个完整的链条,comfy 工作流。是的。链条的一部分如何影响整个过程?
Comfy [00:14:52]: 你是在说模型方面吗?
swyx [00:14:54]: 模型方面,对吧?但一旦你有了基于模型的整个工作流,就很难移动。
Comfy [00:15:01]: 呃,不,嗯,不完全是。嗯,这取决于你的,呃,取决于他们的特定工作流。是的。
swyx [00:15:09]: 所以我做了很多文本和图像。是的。
Comfy [00:15:12]: 当你改变时,大多数工作流都会是完整的。是的。就像,你可能需要完全改变你的提示,完全改变。好吧。
swyx [00:15:24]: 嗯,我的意思是,那么问题可能真的是关于评估。Comfy 社区在评估方面做了什么?只是,你知道,
Comfy [00:15:31]: 嗯,他们并没有真正做那个。更像是,哦,我觉得这张图片不错。所以,呃,
swyx [00:15:38]: 他们只是订阅 Fofr AI,然后看看 Fofr 在做什么。是的。
Comfy [00:15:43]: 嗯,他们只是这样生成。我没看到有人真的这么做。至少在使用 Comfy 的用户中,他们更像是生成图片然后看看,哦,这张不错。就是这样,不像那种更科学的检查,那种更多是在模型方面。如果,嗯,是的,但也有很多感觉,因为这是一种艺术性的东西。你可以创建一个非常好的模型,但它生成的图片并不好看。因为互联网上的大多数图片都不好看。所以如果你只是说,哦,我有最好的模型,第十代巨人,超级聪明。我在所有图片上训练过,就像我在互联网上的所有图片上训练过一样。图片不会好看。所以是的。
Alessio [00:16:42]: 是的。
Comfy [00:16:43]: 它们会非常一致。但人们不会期待从模型中得到那种效果。所以是的。
swyx [00:16:54]: 我们能谈谈 LoRa 吗?因为我们刚刚讨论了模型,下一步可能是 LoRa。之前,我其实有点好奇 LoRa 是如何进入图像社区的工具集的,因为 LoRa 的论文是 2021 年的。然后像 textual inversion 这样的方法在早期的 SD 阶段也很流行。是的。
Comfy [00:17:13]: 我甚至无法解释它们之间的区别。是的,textual inversion。基本上你做的就是训练一个向量,因为,嗯,Stable Diffusion。你有扩散模型,你有文本编码器。所以基本上你做的就是训练一个向量,然后传递给文本编码器。基本上你是在训练一个新词。是的。
swyx [00:17:37]: 这有点像现在的表示工程。是的。
Comfy [00:17:40]: 是的,基本上。是的。你只是,所以如果你知道文本编码器的工作原理,基本上你有,你把你的产品词转换成标记,然后用标记器转换成向量。基本上,是的。每个标记代表一个不同的向量。所以每个词代表一个向量。然后根据你的词,这些向量会被传递给文本编码器,它只是一个。是的,一堆注意力层。基本上它非常接近 LLM 架构。是的。所以基本上你做的就是训练一个新向量。我们说,嗯,我有所有这些图片,我想知道它们代表哪个词?然后它会得到,你训练这个向量,然后当你使用这个向量时,它希望生成类似于你的图片的东西。是的。
swyx [00:18:43]: 我会说它在捕捉你试图训练的概念上出奇地高效。是的。
Comfy [00:18:48]: 嗯,人们已经不再这么做了,尽管当我在 Stability 时,我们实际上在内部训练了一些 textual inversion,比如 T 5 XXL,效果还不错。但出于某种原因,是的,人们不再使用它们。而且它们可能也像,嗯,这是某种东西,可能必须测试,但如果你在 T 5 XXL 上训练一个 textual inversion,它可能也会适用于所有使用 T 5 XXL 的模型,因为同样的事情,比如为 SD 1.5 训练的 textual inversion,它们也适用于 SDXL,因为 SDXL 有两个文本编码器。其中一个和 SD 1.5 的 CLIP-L 一样。所以它们实际上,它们不会那么有效,因为它们只应用于一个文本编码器。但同样的事情也适用于 SD 3。SD 3 有三个文本编码器。所以它仍然有效。你仍然可以在 SD 3 上使用你的 SD 1.5 textual inversion,但它会弱很多,因为现在有三个文本编码器。所以它被稀释得更多了。是的。
swyx [00:20:05]: 人们在 CLIP 方面做了很多实验吗?比如 Siglip,Blip,人们在这些方面做了很多实验吗?
Comfy [00:20:12]: 你不能真的替换。是的。
swyx [00:20:14]: 因为它们是一起训练的,对吧?是的。
Comfy [00:20:15]: 它们是一起训练的。所以你不能像,嗯,我看到人们实验的是长 CLIP。所以基本上有人微调了 CLIP 模型,使其接受更长的提示。
swyx [00:20:27]: 哦,这有点像长上下文微调。是的。
Comfy [00:20:31]: 所以,所以像它,它实际上在 Core Comfy 中得到了支持。
swyx [00:20:35]: 多长是长?
Comfy [00:20:36]: 常规 CLIP 是 77 个标记。是的。长 CLIP 是 256。好的。所以,但像你,如果你使用 Stable Diffusion 1.5,你可能已经注意到,哦,如果我使用超过 77 个词的提示,它仍然有效。嗯,那是因为技巧是,嗯,你把整个大提示分成 77 个词的块。假设你给它像圣经这样的大段文字,它会把它分成 77 个词的块,然后通过 CLIP 传递每个块,最后把它们拼在一起。这不是理想的,但它确实有效。
swyx [00:21:26]: 所以词的位置真的很重要,对吧?这就是为什么提示中的顺序很重要。是的。
Comfy [00:21:33]: 是的。它有效,但它不是理想的,但这是人们所期望的。如果,如果有人给了一个很长的提示,他们期望至少最后的一些概念出现在图片中。但通常当他们给长提示时,他们,他们不,他们不期望细节,我想。所以这就是为什么它很有效。
swyx [00:21:58]: 当我们讨论这个话题时,提示权重,负面提示。负面提示都是这个堆栈层的类似部分。是的。
Comfy [00:22:05]: 它的技巧是,它在 CLIP 上有效,基本上它只是对 SD 1.5 有效,嗯,对于 SD 1.5,提示权重有效是因为 CLIP L 不是一个很深的模型。所以你有一个非常高的相关性,你有输入标记,输入标记向量的索引。和输出标记,它们非常,概念非常紧密地联系在一起。所以这意味着如果你从什么插值向量,嗯,Comfy UI 的做法是它有,好的,你有向量,你有一个空提示。所以你有一个,一个块,像空提示的 CLIP 输出,然后你有你的提示的输出。然后它根据你的提示从中插值。是的。
Comfy [00:23:07]: 所以这就是它如何做提示权重的。但这在你的文本编码器越深时就越不适用。所以在 T 5 X 上,它根本不起作用。所以。哇。
swyx [00:23:20]: 这对人们来说是个问题吗?我的意思是,因为我习惯了只是移动数字。可能不是。是的。
Comfy [00:23:25]: 嗯。
swyx [00:23:26]: 所以你只是用词来描述,对吧?因为它是一个更大的语言模型。是的。
Comfy [00:23:30]: 是的。所以。是的。所以老实说这可能是好的,但我没有在 Flux 上看到很多关于它不起作用的抱怨。所以,我想人们可以用语言绕过它。所以。是的。
swyx [00:23:46]: 是的。然后回到 LoRa,现在定制模型的流行方式是 LoRa。我看到你也支持 Locon 和 LoHa,我之前从未听说过。
Comfy [00:23:56]: 有很多,因为 LoRa 本质上是什么。而不是像,好的,你有你的模型,然后你想微调它。所以你可以微调整个东西,但这有点重。所以为了加快速度并减少负担,你可以做的是只微调一些较小的权重,比如基本上两个低秩矩阵,当你把它们相乘时,代表训练权重和基础权重之间的差异。所以通过训练这两个较小的矩阵,负担就小得多。是的。
Alessio [00:24:45]: 而且它们是可移植的。所以你可以分享它们。是的。这更容易。而且也更小。
Comfy [00:24:49]: 是的。这就是 LoRa 的工作原理。所以基本上,当你在推理时,你可以非常高效地使用它们,就像 ComputeWrite 做的那样。它只是,当你使用 LoRa 时,它直接应用在权重上,所以在采样之前只有一点延迟,然后它就像以前一样快。所以对于推理来说,它并不那么糟糕,但然后你有,所以基本上所有的 LoRa 类型,比如 LoHa,LoCon,所有这些都是表示差异的不同方式。基本上,你可以称之为压缩,尽管它并不是真正的压缩,它只是表示差异的不同方式。有基本的 LoRa,它只是,哦,让我们把这两个矩阵相乘。然后还有其他所有不同的算法。所以。是的。
Alessio [00:25:57]: 所以让我们谈谈 LoRa。让我们谈谈 Comfy UI 实际上是什么。我想大多数人都听说过它。有些人可能看过截图。我想更少的人构建了非常复杂的工作流。所以当你开始时,automatic 是超级简单的方式。你做了哪些选择?所以节点工作流,还有什么其他独特的方式来处理图像生成工作流吗?
Comfy [00:26:22]: 嗯,我觉得,是的,那时候每个人都在尝试做易于使用的界面。是的。所以我说,嗯,每个人都在尝试做易于使用的界面。
swyx [00:26:32]: 让我们做一个难用的界面。
Comfy [00:26:37]: 所以,所以像,我不需要那样做,其他人都在做。所以让我尝试一些像,让我尝试做一个强大的界面,但不容易使用。所以。
swyx [00:26:52]: 所以像,是的,有一种节点执行引擎。是的。是的。它实际上列出了它优先考虑的功能,对吧?让我看看,比如从工作流的任何部分重新执行,异步队列系统,智能内存管理,所有这些似乎都是很多工程。是的。
Comfy [00:27:12]: 在后台有很多工程来让事情运行得很好。因为那是我一直在本地使用它。所以一切。所以有很多,很多思考和努力让一切尽可能运行良好。所以是的。Comfy UI 实际上更像是一个后端,至少,嗯,不是所有的前端都在得到更多的开发,但,但之前,之前它主要是,我几乎只专注于后端。是的。
swyx [00:27:50]: 所以 v 0.1 只是今年八月。是的。
Comfy [00:27:54]: 有了新的前端。之前没有版本控制。所以是的。是的。是的。
swyx [00:27:57]: 那么 0.1 和 1.0 的大重写是什么?
Comfy [00:28:02]: 嗯,那更多是在前端方面。那是因为之前它只是像 UI,什么,因为当我第一次写它时,我只是说,好的,我怎么能做,像,我会做网页开发,但我不喜欢做。像什么是最简单的方法我可以把这个节点界面放在上面。然后我找到了这个库。是的。像 JavaScript 库。
swyx [00:28:26]: Live graph?
Comfy [00:28:27]: Live graph。
swyx [00:28:28]: 通常人们会使用像 react flow 这样的流程构建器。是的。
Comfy [00:28:31]: 但那似乎太复杂了。所以我不想花时间开发前端。所以我说,嗯,哦,light graph。它有整个节点界面。所以,好的。让我把它插入到我的后端。
swyx [00:28:49]: 我觉得如果 Streamlit 或 Gradio 提供了你会使用 Streamlit 或 Gradio 的东西,因为它是 Python。是的。
Comfy [00:28:54]: 是的。是的。是的。
Comfy [00:29:00]: 是的。
Comfy [00:29:14]: 是的。逻辑和你的后端逻辑,然后把它们粘在一起。
swyx [00:29:20]: 这对你们来说应该很容易。如果你是 Python 主,你知道,我是 JS 主,对吧?好的。如果你是 Python 主,它应该很容易。
Comfy [00:29:26]: 是的,它很容易,但它会让你的整个软件变得一团糟。
swyx [00:29:30]: 我明白了,我明白了。所以你是在混合关注点而不是分离关注点?
Comfy [00:29:34]: 嗯,这是因为… 像前端和后端。前端和后端应该很好地分离,有一个定义的 API。像这就是你应该做的。聪明的人不同意。它只是把所有东西粘在一起。它让它变得容易像一团糟。而且它,Gradio 有很多问题。像它很好,如果你只是想快速给你的 ML 项目加个界面。像这就是它的用途。是的。像使用它没有问题。像,哦,我有我的代码。我只是想快速加个界面。这很完美。像使用 Gradio。但如果你想做一些像真正的软件,能持续很长时间并且易于维护的东西,那么我会避免它。是的。
swyx [00:30:32]: 所以你的批评是 Streamlit 和 Gradio 是一样的。我的意思是,那些是同样的批评。
Comfy [00:30:37]: 是的,Streamlit 我用得不多。是的,我只是看了一下。
swyx [00:30:43]: 类似的哲学。
Comfy [00:30:44]: 是的,它类似。它只是,它对我来说就像,好的,对于快速的 AI 演示,它很完美。
swyx [00:30:51]: 是的。回到核心技术,像异步队列,慢速重新执行,智能内存管理,你知道,有什么你非常自豪或很难解决的问题吗?
Comfy [00:31:00]: 是的。最头疼的可能是内存管理。是的。
swyx [00:31:05]: 你只是把模型分页进出吗?是的。
Comfy [00:31:08]: 之前它只是,好的,加载模型,完全卸载它。然后,好的,当你的模型很小时,这很有效,但如果你的模型很大,比如有人有 4090,模型大小是 10 GB,加载和加载可能需要几秒钟,所以你想尽量让东西保持在 GPU 内存中。Comfy UI 现在做的是它。它尝试估计,好的,像,好的,你要采样这个模型,它可能会占用这么多内存,让我们移除已经加载在 GPU 上的模型,这么多内存,然后执行它。但所以有一个微妙的平衡,因为尝试移除已经加载的最少模型。因为像 Windows 驱动,另一个问题是 Windows 上的 NVIDIA 驱动默认情况下,因为有一种方法可以禁用这个功能,但默认情况下,如果你开始加载,你可以溢出你的 GPU 内存,然后驱动会自动开始分页到 RAM。但问题是它会让一切变得非常慢。所以当你看到人们抱怨,哦,这个模型有效,但哦,它开始变得非常慢,那可能就是发生了什么。所以基本上你必须尽量使用尽可能多的内存,但不要太多,否则事情会开始变慢,或者人们会内存不足,然后只是找到,尝试找到那条线,哦,像 Windows 上的驱动开始分页等等。是的。PyTorch 的问题是它,它的高级别没有那么多细粒度的控制,像特定的内存东西,所以必须把内存释放留给 Python 和 PyTorch,这有时会很烦人。
swyx [00:33:32]: 所以,你知道,我认为一件事是,作为这个项目的维护者,你设计了一个非常广泛的计算表面,像,你甚至支持 CPU。
Comfy [00:33:42]: 是的,嗯,那只是,对于 PyTorch,PyTorch 支持 CPU,所以,是的,它只是,支持它并不难。
swyx [00:33:50]: 首先,有市场份额估计吗,像,70% NVIDIA,30% AMD,然后像 Apple Silicon 上的杂项或其他?
Comfy [00:33:59]: 对于 Comfy?是的。是的,我不知道市场份额。
swyx [00:34:03]: 你能猜到吗?
Comfy [00:34:04]: 我觉得主要是 NVIDIA。对。因为 AMD 在 Windows 上表现很差。在 Linux 上,它表现还行。它比同等价格的 NVIDIA GPU 要差一些,但还能用,你可以生成图像,一切都能正常工作。但在 Windows 上,你可能会遇到困难,所以,这就是问题所在,而且我认为大多数买了 AMD 的人可能都在用 Windows。他们可能不会切换到 Linux,所以……是的。所以,直到 AMD 真正把他们的,比如,raw cam 移植到 Windows 上,并且 PyTorch 也能正常工作,我认为他们正在做这件事,他们正在努力,但在他们搞定之前,在 Windows 上有一个好的 PyTorch raw cam 构建之前,他们会遇到困难。是的。
Alessio [00:35:06]: 我们得让 George 来处理这事。是的。嗯,他正在尝试让 Lisa Su 来做这件事,但是……我们来聊聊节点设计吧。所以,与所有其他文本生成图像的工具不同,你有一个非常深的,比如,你有一个单独的节点用于 clip 和 code,你有一个单独的节点用于 case sampler,你有所有这些节点。回到让它简单还是让它复杂的问题,但,比如,人们实际上会怎么玩这些设置呢?你知道的,比如,你怎么引导人们去理解,嘿,这个设置实际上会非常有影响,而这个设置可能影响较小,但我们还是想把它暴露给你?
Comfy [00:35:40]: 嗯,我尝试……我尝试暴露所有东西,或者,但至少对于某些东西,比如,对于采样器,有四个不同的采样器节点,从最简单到最复杂。所以,如果你用简单的节点,常规的采样器节点,你只有基本的设置。但如果你用高级采样器……如果你用自定义高级节点,那个节点你实际上可以看到不同的节点。
Alessio [00:36:19]: 我现在正在看。是的。你用的最有影响的参数是什么?所以,你知道,你可以有更多,但哪些参数真的会带来不同?
Comfy [00:36:30]: 是的,它们都有影响。它们都有自己的作用,比如,步骤。通常你希望步骤尽可能少。但如果你在优化你的工作流程,你会降低步骤,直到图像开始变得太差。因为那是你运行扩散过程的步骤数。所以,如果你想让事情更快,步骤越少越好。但 CFG,那个更像是图像的对比度。如果你的图像看起来太模糊,你可以降低 CFG。所以,CFG,那是负提示和正提示的强度。因为当你采样扩散模型时,它基本上是一个负提示。它只是正预测减去负预测。
swyx [00:37:32]: 对比损失。是的。
Comfy [00:37:34]: 它是正减去负,CFG 是乘数。是的。是的。
Alessio [00:37:41]: 有什么好的资源可以理解这些参数的作用吗?我觉得大多数人从自动开始,然后他们转向,比如,snap,CFG,采样器名称,调度器,去噪。读它。
Comfy [00:37:53]: 但说实话,嗯,更多的是你应该自己尝试。我不知道,你不一定需要知道它是如何工作的才能知道它做了什么。因为即使你知道 CFGO,它是正提示减去负提示。是的。所以你唯一知道的是如果 CFG 是 1.0,那么负提示没有被应用。这也意味着采样速度是两倍。但除此之外,你真的应该自己看看它对图像的影响,你可能会对这些东西的作用有更直观的理解。
Alessio [00:38:34]: 还有其他节点或东西你想提到的吗?比如,我知道 animate diff IP 适配器。那些是最受欢迎的。是的。还有什么你想提到的?
Comfy [00:38:44]: 不是节点,但我喜欢的是有些人有时会做一些使用 ComfyUI 作为后端的东西。比如,有一个 Krita 的插件使用 ComfyUI 作为后端。所以你可以在 Krita 中使用所有在 Comfy 中工作的模型。我想我试过一次。但我知道很多人用它,它可能真的很好,所以。
Alessio [00:39:15]: 人们构建的最疯狂的节点是什么,最复杂的?
Comfy [00:39:21]: 最疯狂的节点?是的。我知道有些人用 Comfy 做了视频游戏,比如那样。所以,我记得,去年,有人用 Comfy 做了一个 Wolfenstein 3 D。当然。然后其中一个输入是,哦,你可以生成一个纹理,然后它在游戏中改变纹理。所以你可以把它插到工作流程中。如果你看那里,有很多疯狂的东西人们做的,所以。是的。
Alessio [00:39:59]: 现在有一个节点注册表,人们可以用来下载节点。是的。
Comfy [00:40:04]: 嗯,一直有 ComfyUI 管理器。是的。但我们正在尝试让它更正式,比如,用节点注册表。因为在节点注册表之前,你的自定义节点是如何进入 ComfyUI 管理器的?那是运行它的人,他每天在 GitHub 上搜索新的自定义节点,并每年添加到他的自定义节点管理器中。所以我们正在尝试让他不那么费力。所以我们正在尝试让他不那么费力,基本上。是的。
Alessio [00:40:40]: 是的。但我看到,有一个 YouTube 下载节点。这几乎像一个数据管道,而不是图像生成的东西。你可以输入数据,你可以对它应用过滤器,你可以生成数据。
Comfy [00:40:54]: 是的。你可以做很多不同的事情。是的。所以我想,我做的让它很容易制作自定义节点。所以我认为这帮助很大。我认为这对生态系统帮助很大,因为它很容易制作一个节点。所以,是的,有时太容易了。然后我们有一个问题,有很多自定义节点包共享相似的节点。但,嗯,这是我们正在尝试通过将一些功能引入核心来解决的问题。是的。是的。
Alessio [00:41:36]: 然后还有视频。人们可以做视频生成。是的。
Comfy [00:41:40]: 视频,嗯,第一个视频模型是 stable video diffusion,那是去年,是的,正好去年,我想。一年前。但那不是一个真正的视频模型。所以它是……
swyx [00:41:55]: 它是,比如,移动图像?是的。
Comfy [00:41:57]: 我生成了视频。我的意思是它仍然是 2 D 潜在空间。基本上这是我想做的。所以他们做的是他们拿了 SD 2,然后他们添加了一些时间注意力,然后在视频上训练它。所以它有点像动画,基本上是一样的想法。我说它不是真正的视频模型是因为你仍然有 2 D 潜在空间。比如,真正的视频模型,比如 Mochi,会有 3 D 潜在空间。嗯。
Alessio [00:42:32]: 这意味着你可以,比如,在空间中移动,基本上。这是区别。你不仅仅是重新定向。是的。
Comfy [00:42:39]: 而且它也是,嗯,它也是因为你有一个时间 VAE。嗯。比如,Mochi 有一个时间 VAE,它在时间方向上也压缩。所以这是你没有的,比如,animated diff 和 stable video diffusion。它们只在空间上压缩,不在时间上压缩。嗯。对。所以,是的。这就是为什么我称之为真正的视频模型。实际上有几个,但我在 comfy 中实现的是 Mochi,因为它似乎是目前为止最好的。是的。
swyx [00:43:15]: 我们有 AJ 来在 stable diffusion meetup 上讲话。另一个我见过的开源的是 COG video。是的。
Comfy [00:43:21]: COG video。是的。那个也看起来不错,但,是的。中文的,所以我们不用它。不,没关系。只是,是的,我可以。是的。只是它不是唯一的。还有几个其他的,我。
swyx [00:43:36]: 其他的是闭源的,对吧?比如,Cling。是的。
Comfy [00:43:39]: 闭源的,有很多。但我的意思是开源的。我见过几个。比如,我不记得它们的名字,但有 COG video,大的那个。然后还有几个和 SSD 3.5 同一天发布的。有一个和 SSD 3.5 同一天发布的,这就是为什么我不记得名字。
swyx [00:44:02]: 我们应该有一个发布时间表,这样我们就不会冲突。是的。
Comfy [00:44:06]: 我想 SD 3.5 和 Mochi 是同一天发布的。所以其他的一切都被淹没了,完全淹没了。所以不知为什么,很多人选择那天发布他们的东西。
Comfy [00:44:21]: 是的。这对那些人是遗憾的。我想 Omnijet 也是同一天发布的,看起来也很有趣。是的。是的。
Alessio [00:44:30]: 什么是 Comfy?所以你是 Comfy。然后还有 comfy. Org。我知道我们为新闻研究做了很多事,那些人也更像开源的东西。你们怎么工作?比如你提到的,你主要做核心部分。然后……
Comfy [00:44:47]: 也许我应该慢慢解释,因为我觉得,是的,我只解释了一部分。对。是的。也许我应该解释剩下的。所以是的。基本上,一月,那是 2023 年 1 月 16 日,那是 Amphi 第一次向公众发布。然后,是的,我在 Reddit 上发了一个关于区域合成的帖子,大概在一月底或二月初。然后有人,一个 YouTuber,做了一个关于它的视频,比如 Olivio,他在 2023 年 3 月做了一个关于 Amphi 的视频。我想那是真正引起关注的时候。那时我继续开发它,人们开始更多地使用它,不幸的是,这意味着我最初写它是为了做实验,但后来我做实验的时间减少了。因为人们实际上开始使用它了。比如,我不得不,我说,好吧,是时候添加所有这些功能了。是的,然后我在 2023 年 6 月被 Stability 雇佣了。然后我做了,基本上,是的,他们雇佣我是因为他们想要 SD-XL。所以我让 SD-XL 在 UI 上工作得很好,因为他们正在实验ámphi. House. Com。实际上,SDX,SDXL 发布的方式是他们先发布了代码,但没有发布模型检查点。所以他们发布了代码。然后,嗯,因为研究是与代码相关的,我在 Compute 2 中发布了代码。然后检查点基本上是早期访问。人们必须注册,他们只允许很多 edu 邮箱的人。比如如果你有 edu 邮箱,他们基本上给你访问 SDXL 0.9。然后,嗯,那泄露了。对。当然,因为如果你这样做,它当然会泄露。嗯,人们唯一能轻松使用它的方式是用 Comfy。所以,是的,人们开始使用。然后我修复了一些人们遇到的问题。所以然后 1.0 大版本发布了。嗯,Comfy UI 是很多人唯一能在他们的电脑上运行它的方式。因为它就像自动一样低效和糟糕,大多数人实际上无法运行它。就像他做了一个快速的实现。所以人们被迫使用 Comfy UI,这就是它变得流行的原因,因为人们别无选择。
swyx [00:47:55]: 增长黑客。
Comfy [00:47:56]: 是的。
swyx [00:47:56]: 是的。
Comfy [00:47:57]: 比如,到处都有,比如没有 4090 的人,他们有,比如,只有普通 GPU 的人,他们没有选择。
Alessio [00:48:05]: 所以是的,我有一台 4070。所以想想我。那么今天,有什么,有一个核心 Comfy 团队吗?
Comfy [00:48:13]: 嗯,是的,现在,嗯,是的,我们正在招聘。好的。实际上,所以现在核心,比如,嗯,核心本身,是我。嗯,但因为,嗯,原因是我们现在大部分精力都放在前端上,因为那是长期被忽视的东西。所以,嗯,所以现在大部分精力都放在前端上,但我们,嗯,是的,我们很快就会得到,嗯,更多的人来帮助我处理实际的后端工作。是的。所以,不,我不会说百分之百,因为这就是为什么一旦我们有 V 1 发布,那将是包,comfy-wise,带有漂亮的界面,易于在 Windows 和希望 Mac 上安装。嗯,是的。一旦我们有那个,嗯,我们将有很多事情要做,后端和前端都有,但,嗯。
Alessio [00:49:14]: 我在等待名单上。时间是什么时候?
Comfy [00:49:18]: 嗯,很快。嗯,很快。是的,我不想承诺发布日期。我们有一个目标发布日期,但我不确定是否公开。是的,我们将继续做开源,让 MPUI 成为运行稳定扩散模型的最佳方式。至少在开源方面,它将是本地运行模型的最佳方式。但我们会有一些东西从中赚钱,比如云推理或那种东西。也许还有一些企业用的东西。
swyx [00:50:08]: 我的意思是,有几个问题。你对其他 comfy 初创公司怎么看?
Comfy [00:50:11]: 我的意思是,我觉得很好。他们在用你的名字。是的,嗯,他们用 comfy 比用其他东西好。是的,这是真的。没关系。我们会尽量不……我们不想……我们希望人们用 comfy。就像我说的,人们用 comfy 比用其他东西好。所以只要他们用 comfy,我认为这对生态系统有帮助。因为更多的人,即使他们不直接贡献,他们使用 comfy 的事实意味着人们更有可能加入生态系统。所以,是的。
swyx [00:50:57]: 然后你会做文本吗?
Comfy [00:50:59]: 是的,嗯,你已经可以用一些自定义节点做文本了。所以,是的,这是我们喜欢的。是的,这是我想最终添加到核心的东西,但它更像不是一个非常……它不是非常高的优先级。但因为很多人用文本做提示增强和其他类似的事情。所以,是的,只是我的重点一直在扩散模型上。是的,除非有一些文本扩散模型出来。
swyx [00:51:30]: 是的,David Holtz 在文本扩散上投入了很多。
Comfy [00:51:34]: 是的,嗯,如果有一个好的出来,我们可能会实现它,因为它符合整个……
swyx [00:51:39]: 是的,我的意思是,我想它会像 Midjourney 一样闭源。是的。
Comfy [00:51:43]: 嗯,如果有一个开源的出来,我可能会实现它。
Alessio [00:51:54]: 酷,comfy。非常感谢你来。这很有趣。再见。
更多 AI 辅助设计和设计灵感趋势,请关注公众号(设计小站):sjxz 00。