5分钟阅读
谷歌新发布DSSTAR:一站式数据科学智能体,性能超越AutoGen和DAAgent
谷歌新发布DS-STAR:一站式数据科学智能体,性能超越AutoGen/DA-Agent
编者按:谷歌推出一款全能数据科学智能体DS-STAR,可处理CSV、JSON、Markdown等异构数据。它能自动分析数据、生成代码、校验错误并输出结果,将数据科学全流程封装为“一键式”解决方案。对非技术背景的业务人员,只需上传文件并提出问题,即可直接获取分析报告;对数据科学家而言,它可自动生成代码草稿,大幅减少重复繁琐工作。该智能体在DABStep、KramaBench、DA-Code三大基准测试中,性能超越AutoGen、DA-Agent等现有方案。其核心流程分为两步:先通过数据文件分析器扫描目录,生成各格式文件的字段与语义摘要;再通过“规划-编码-验证-优化”的迭代循环推进任务,复杂任务平均5.6轮可解决,简单任务平均3轮,超半数简单任务首轮即可完成。
2025年11月6日
作者:Jinsung Yoon(谷歌云研究科学家)、Jaehyun Nam(谷歌云学生研究员)
DS-STAR是一款顶尖的数据科学智能体,具备极强的通用性——可自动化完成统计分析、数据可视化、数据清洗等一系列任务,兼容多种数据类型,最终在知名的DABStep基准测试中取得顶尖成绩。
数据科学的核心是将原始数据转化为有意义、可落地的洞察,在解决现实世界问题中发挥着关键作用。企业通常依赖数据驱动的洞察来制定重要战略决策。但数据科学流程往往复杂,需要使用者具备扎实的计算机科学、统计学等专业知识。整个工作流包含大量耗时任务,从解读各类文档到执行复杂的数据处理与统计分析均在此列。
为简化这一复杂流程,近期研究聚焦于利用现成的大型语言模型(LLM)开发自主数据科学智能体。这类智能体的目标是将自然语言问题转化为特定任务的可执行代码。尽管相关技术已取得显著进展,但当前数据科学智能体仍存在诸多限制,阻碍了其实际应用。
核心问题之一是对结构化数据的高度依赖,例如关系型数据库中的CSV文件。这种局限使其忽略了现实场景中常见的异构数据格式(如JSON、非结构化文本、Markdown文件)所包含的宝贵信息。另一个挑战是,许多数据科学问题具有开放性,缺乏真值标签,难以验证智能体的推理过程是否正确。
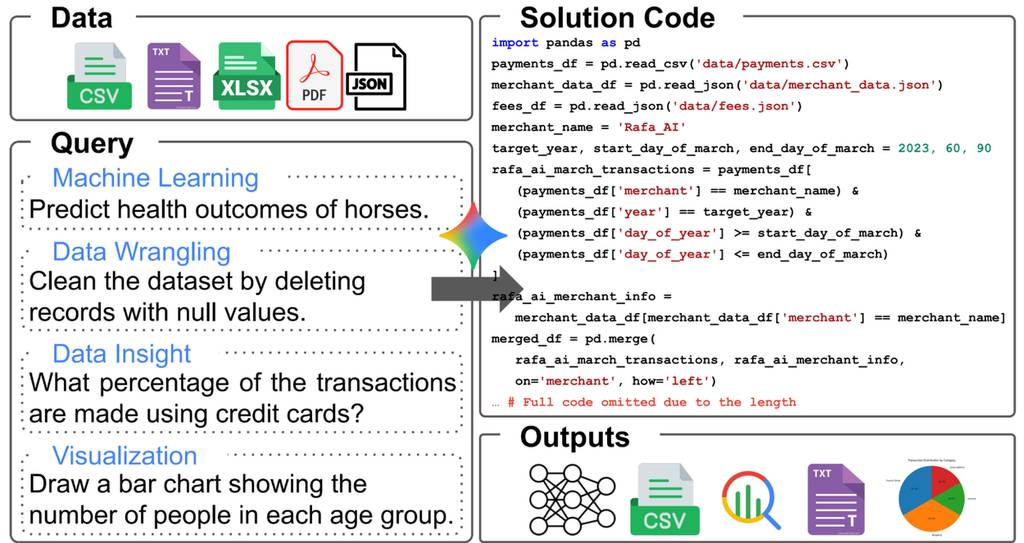
数据科学智能体通过生成可操作多种数据格式的代码来响应用户查询。代码执行后,智能体会输出最终解决方案,形式可能包括训练好的模型、处理后的数据库、可视化图表或文本格式的答案。
为此,我们推出了DS-STAR——一款专为解决数据科学问题设计的新型智能体。DS-STAR包含三大核心创新:(1)数据文件分析模块,可自动从包括非结构化数据在内的多种格式中提取上下文信息;(2)验证阶段,由基于LLM的裁判模型评估每一步计划的充分性;(3)序列规划流程,基于反馈迭代优化初始计划。这种迭代优化能力使DS-STAR能够处理复杂分析任务,从多个数据源中提取可验证的洞察。我们的测试表明,DS-STAR在DABStep、KramaBench、DA-Code等权威基准测试中均达到顶尖性能,尤其在涉及多种异构数据文件的任务中表现突出。
DS-STAR的核心工作流程
DS-STAR框架主要分为两个阶段运行。
第一阶段,智能体自动扫描目录中的所有文件,生成关于文件结构和内容的文本摘要。该摘要将成为后续处理任务的关键上下文依据。
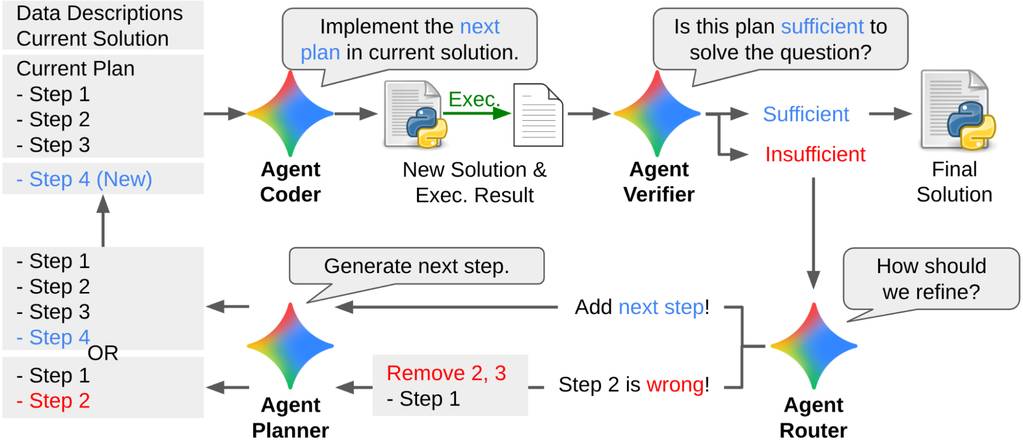
第二阶段,DS-STAR进入“规划-执行-验证”的核心循环。规划模块(Planner)首先制定高层级计划,编码模块(Coder)将其转化为可执行代码脚本。随后,验证模块(Verifier)——一个基于LLM的裁判模型——评估代码解决问题的有效性。若裁判判定计划不足,路由模块(Router)会确定需要修改或新增的步骤,DS-STAR据此优化计划并重复循环。
值得注意的是,DS-STAR采用的工作方式模拟了专业分析师使用Google Colab等工具的流程:逐步构建计划,在推进前审查中间结果。该迭代循环将持续进行,直至计划被判定为满意或达到最大迭代次数(10轮),最终输出代码作为解决方案。
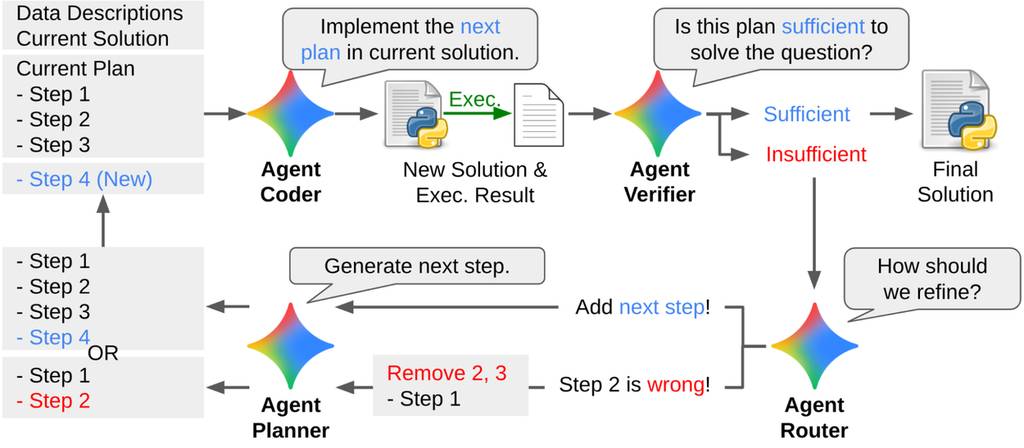
DS-STAR的工作流是一个迭代循环。它从执行简单计划开始,通过验证模块检查计划是否充分;若计划不足,路由模块会引导优化(新增步骤或修正错误),之后循环重复。整个过程持续至验证模块批准计划或达到最大迭代轮数。
性能评估
为验证DS-STAR的有效性,我们在DABStep、KramaBench、DA-Code三大权威数据科学基准测试中,将其与AutoGen、DA-Agent等现有顶尖方案进行了性能对比。这些基准测试涵盖数据清洗、机器学习、可视化等复杂任务,且要求处理多个数据源和格式。
测试结果显示,DS-STAR在所有场景中均显著优于AutoGen和DA-Agent。与最佳对比方案相比,DS-STAR在DABStep上的准确率从41.0%提升至45.2%,在KramaBench上从39.8%提升至44.7%,在DA-Code上从37.0%提升至38.5%。值得一提的是,截至2025年9月18日,DS-STAR已在DABStep基准测试的公开排行榜中位列第一。
无论是简单任务(答案仅需单个文件)还是复杂任务(需多个文件),DS-STAR均持续超越竞争基准,展现出处理多种异构数据源的卓越能力。
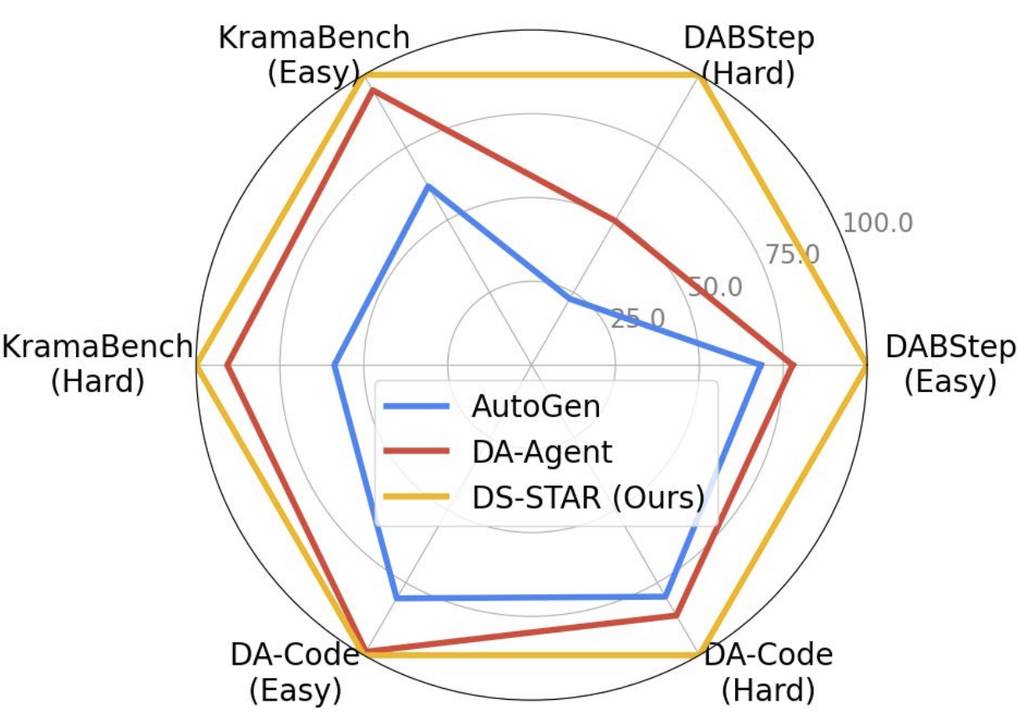
该图表展示了DS-STAR在DABStep、KramaBench、DA-Code基准测试中,针对简单任务(单文件)和复杂任务(多文件)的标准化准确率(%)。DS-STAR持续优于竞争基准,在需处理多种异构数据文件的复杂任务中优势尤为明显。
DS-STAR深度解析
我们进一步开展消融实验,验证DS-STAR各组件的有效性,并分析优化轮数对生成满意计划的影响。
核心组件有效性
- 数据文件分析器:该组件对高性能至关重要。若移除其生成的描述信息(变体1),DS-STAR在DABStep基准测试复杂任务中的准确率骤降至26.98%,可见丰富的数据上下文对有效规划和执行的重要性。
- 路由模块:路由模块具备判断是否需要新增步骤或修正错误步骤的能力,这一功能不可或缺。若移除该模块(变体2),DS-STAR仅能按顺序新增步骤,导致简单任务和复杂任务的性能均下降。这表明,修正计划中的错误比持续添加可能存在缺陷的步骤更有效。
跨LLM的通用性
我们还测试了DS-STAR以GPT-5为基础模型的适应性,其在DABStep基准测试中取得了良好结果,证明该框架具备通用性。有趣的是,基于GPT-5的DS-STAR在简单任务中表现更优,而基于Gemini-2.5-Pro的版本在复杂任务中表现更佳。
优化流程分析
下图显示,复杂任务自然需要更多迭代次数。在DABStep基准测试中,复杂任务平均需5.6轮解决,而简单任务仅需3.0轮,且超半数简单任务在首轮即可完成。
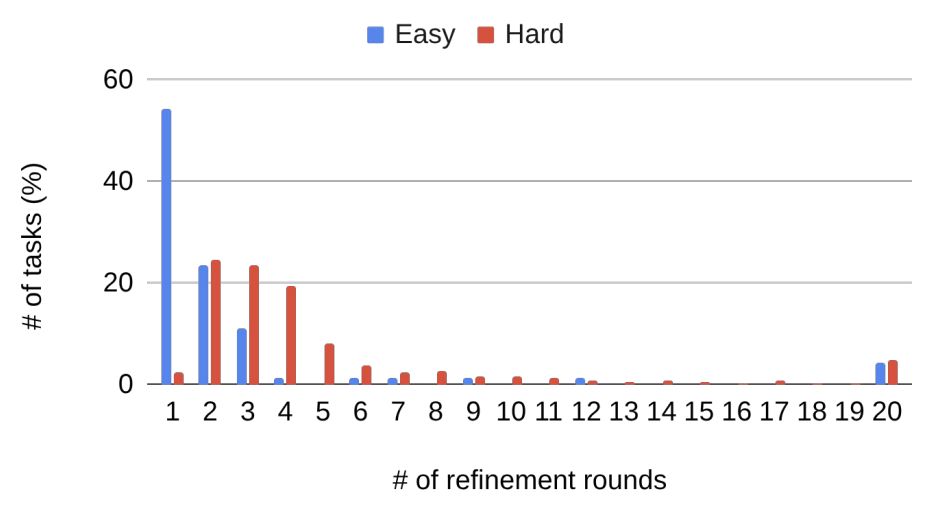
DABStep基准测试的优化轮数分析显示,复杂任务需要更多迭代:复杂任务平均5.6轮,简单任务平均3.0轮,超50%的简单任务可在首轮解决。
总结
本研究推出了DS-STAR——一款能够自主解决数据科学问题的新型智能体。该框架的核心创新体现在两方面:一是对多种文件格式的自动分析能力,二是基于新型LLM验证系统的迭代式序列规划流程。DS-STAR在DABStep、KramaBench、DA-Code三大基准测试中建立了新的性能标杆,超越了现有最佳方案。通过自动化复杂的数据科学任务,DS-STAR有望降低数据科学的使用门槛,让个人和企业都能更便捷地运用相关技术,推动多个领域的创新发展。
致谢
感谢Jiefeng Chen、Jinwoo Shin、Raj Sinha、Mihir Parmar、George Lee、Vishy Tirumalashetty、Tomas Pfister和Burak Gokturk为这项工作做出的宝贵贡献。
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。