5分钟阅读
Figma一键Mockup!另上最新Flux加速技术svdquant安装教程

前言
之前我写过一起关于如何利用阿里的 IC-LoRA 和 Fill+Redux 模型将 logo 放置在 mockup 上,感兴趣的朋友可以回顾一下:
虽然最近也新出了一个叫 ACE++的模型,用于迁移图案,但对比来看,还是觉得 IC-LoRA 稳定一点,不知道是不是我的错觉🤔。
今天,我们还是基于 IC-LoRA 改进几个事情:
- 给工作流加速,用最新的加速技术svdquant,FLUX 可以 7 秒内出图!
- 不做反推了,直接用 DeepSeek R 1 帮我们生成 mockup,这样理论上,mockup 素材 key 无限;
- 接入 Figma,直接调用 ComfyUI 工作流,无缝衔接设计。
先看效果
随便找个 logo(假的):
 使用工作流生成的 mockup:
使用工作流生成的 mockup:

除了还原 logo 的形态,把工艺都完美地呈现了!

有时候文字会丢失,但是效果非常到位!做旧的感觉都有了。




工作流介绍
话不多说,直接上工作流讲解和截图。
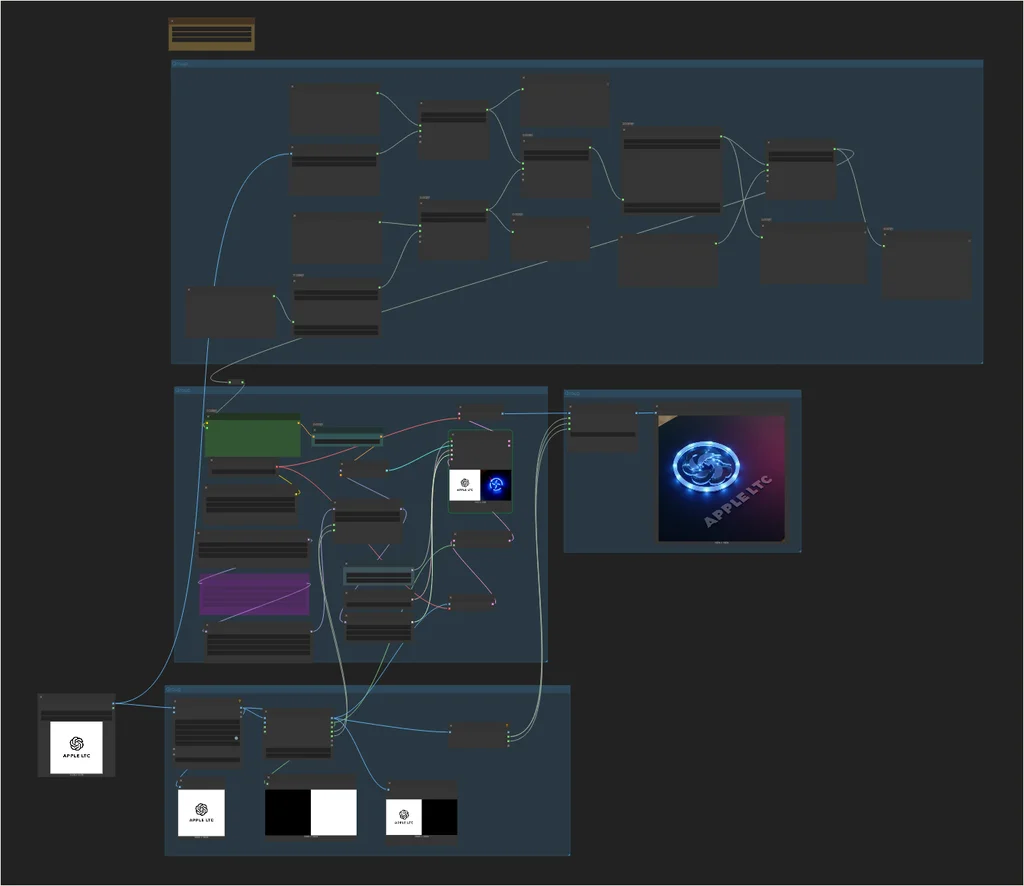
提示语处理
如之前文章所述,IC-LoRA 对于提示词是非常敏感的,其需要的格式如下:
场景整体描述 [IMAGE1] logo描述语; [IMAGE2] logo放置在xx场景(mockup)中
基于此,我们利用 DeepSeek 对提示语进行一系列处理。
第一步:对 logo 进行反推
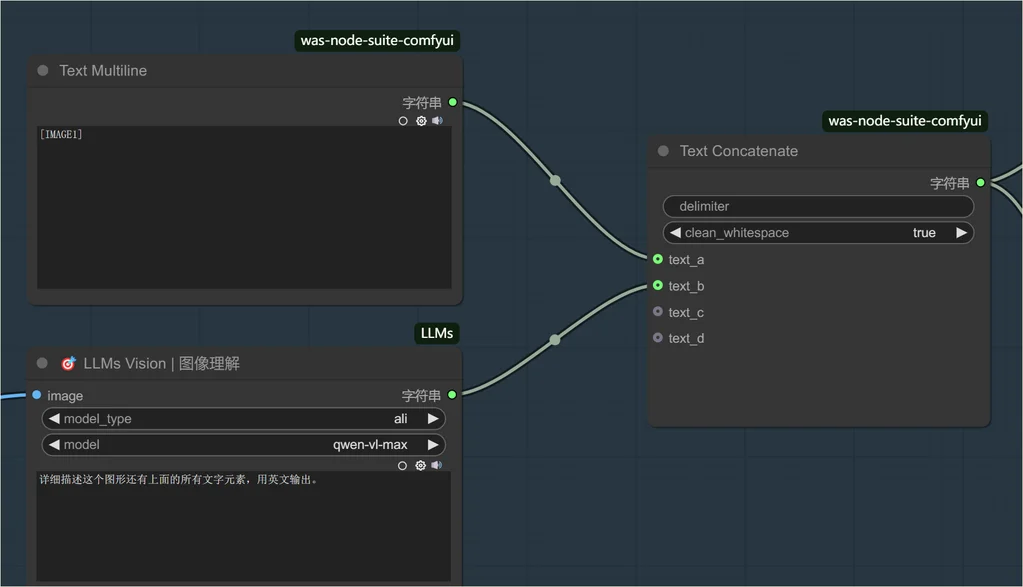
第二步:使用 DeepSeek 进行 mockup 的描述
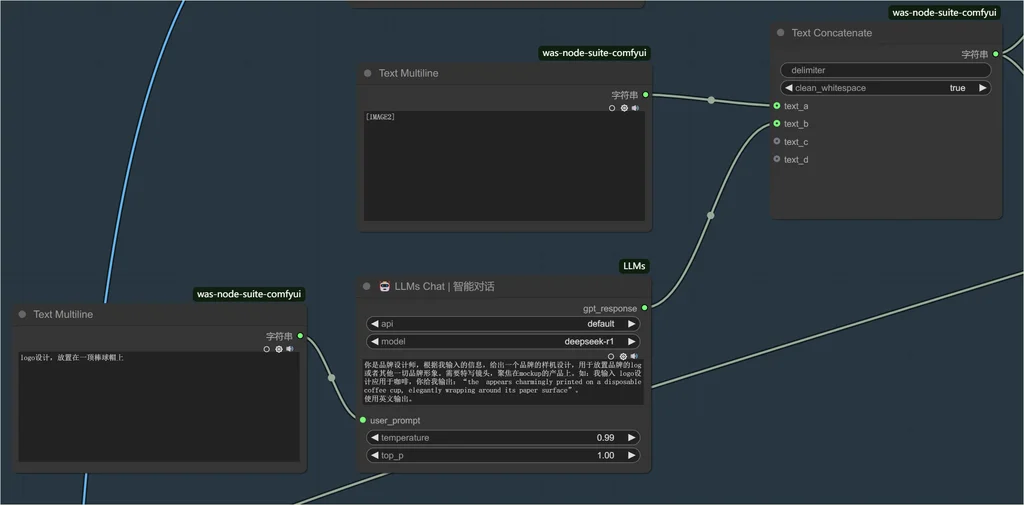
第三步:继续使用 DeepSeek 进行提示语整理
基于第一、第二步的输入,进行归纳和整理。
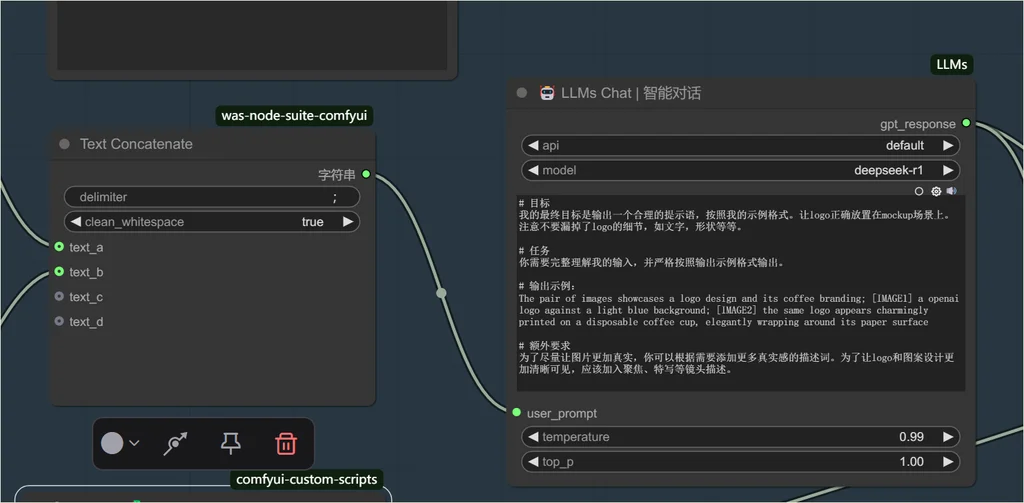
所以最终效果是这样的:
我输入:
logo设计,放置在一顶棒球帽上
最后 llms 给我输出:
The pair of images presents a minimalist logo and its apparel application; [IMAGE1] an abstract geometric logo with interlocking shapes forming a circular motif, accompanied by bold "APPLE LTC" typography on a clean white background; [IMAGE2] the embroidered logo takes center stage on a structured baseball cap, its precisely stitched geometric patterns catching the light through tight macro framing. The premium cotton twill fabric amplifies the dimensional stitching texture, while the camera's shallow depth of field accentuates the crisp contrast between the vibrant emblem and the cap's muted olive-green surface, creating a tactile visual narrative of sporty sophistication..Brand visualization,Product Visualization,Real photography.
已经很完美的符合 IC-LoRA 的提示语要求了。
拼接图像
安装 IC-LoRA 的出图方案,需要对图像进行拼接,然后让 FLUX 重绘非 logo 部分。
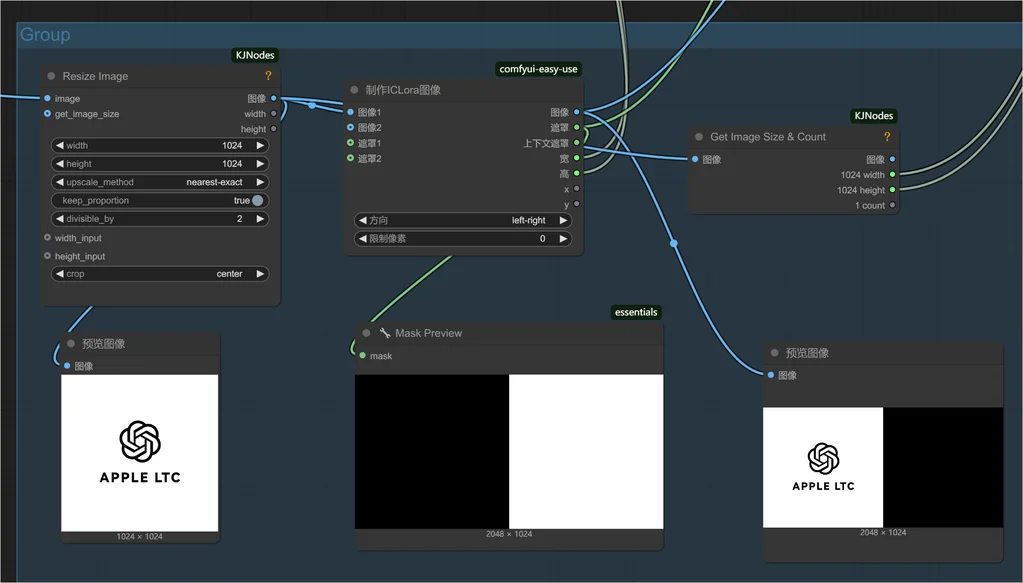
SVD 加速采样
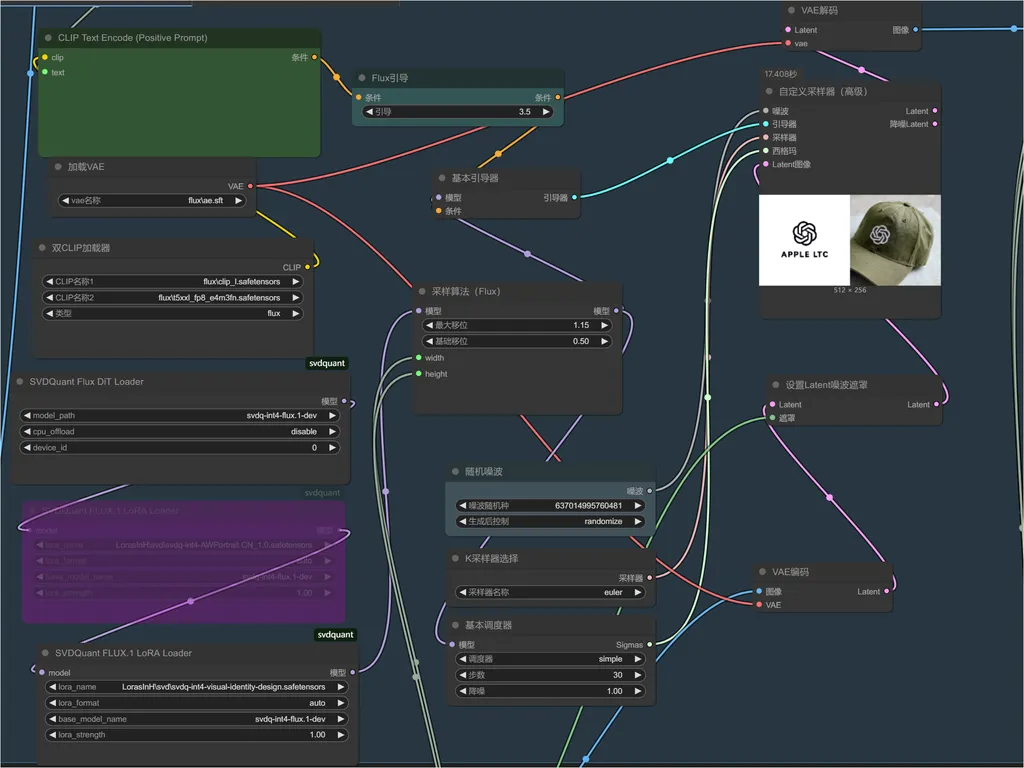
这次,我们引入了最新的 FLUX 加速技术。文章后面附上教程!这里就先看截图。
可以实现 7 秒内出图,而且质量还不会下降!
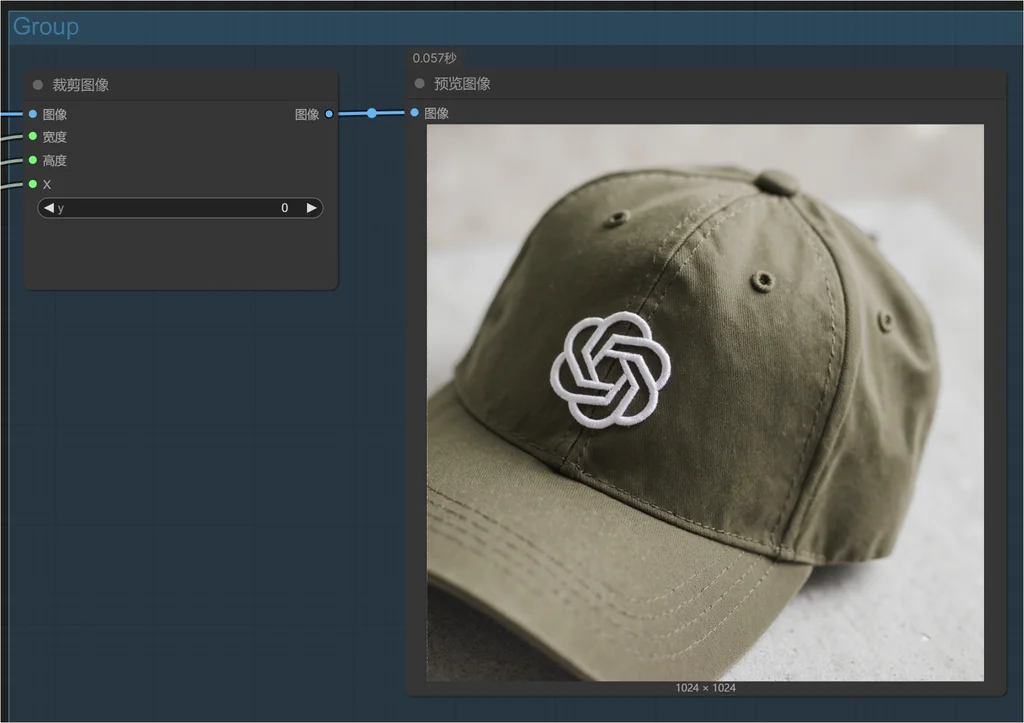
裁剪图像
最后就是裁剪图像,比较简单:
接入 Figma
如果没有接入 Figma 的需求,这步骤大家可以跳过,但是作为一个设计师,通常都会与 Figma 打交道,所以直接在 Figma 调用工作流,可以更无缝地链接设计和产出,节省很多时间。
设置 ComfyUI deploy
在原来的工作流基础上,拖入以下节点:
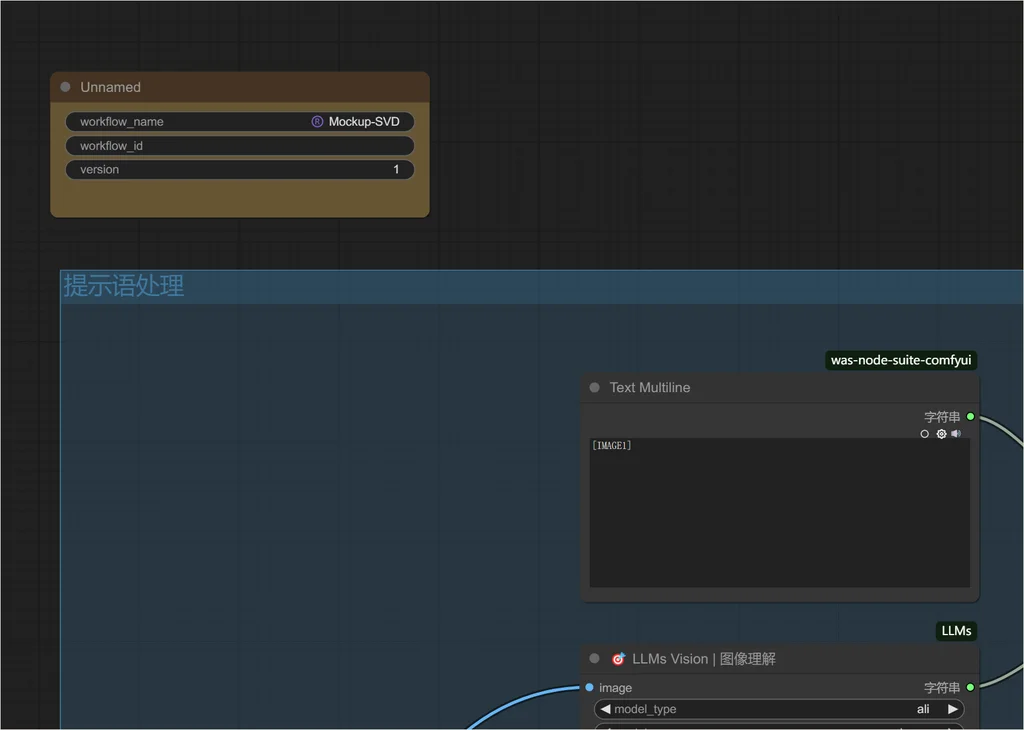
定义需要在 Figma 暴露的参数:
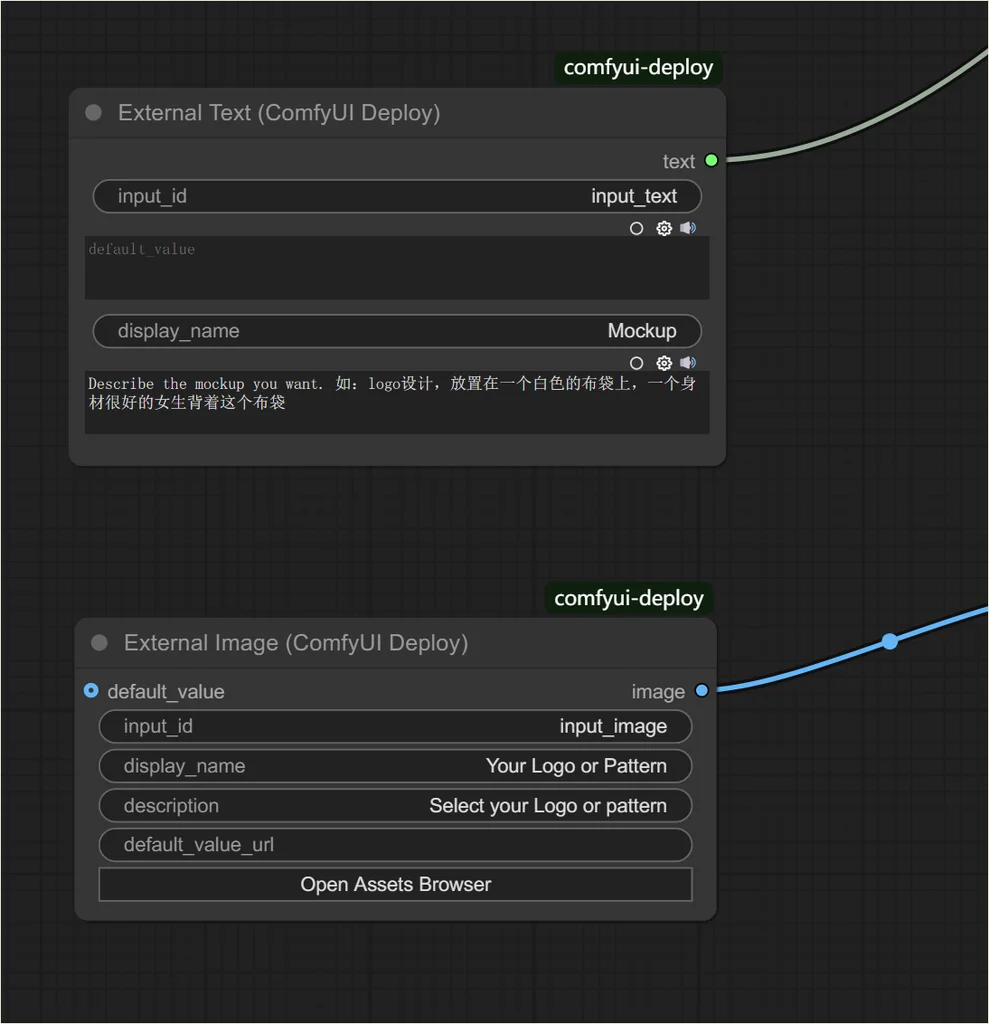
发布到 deploy 服务器:
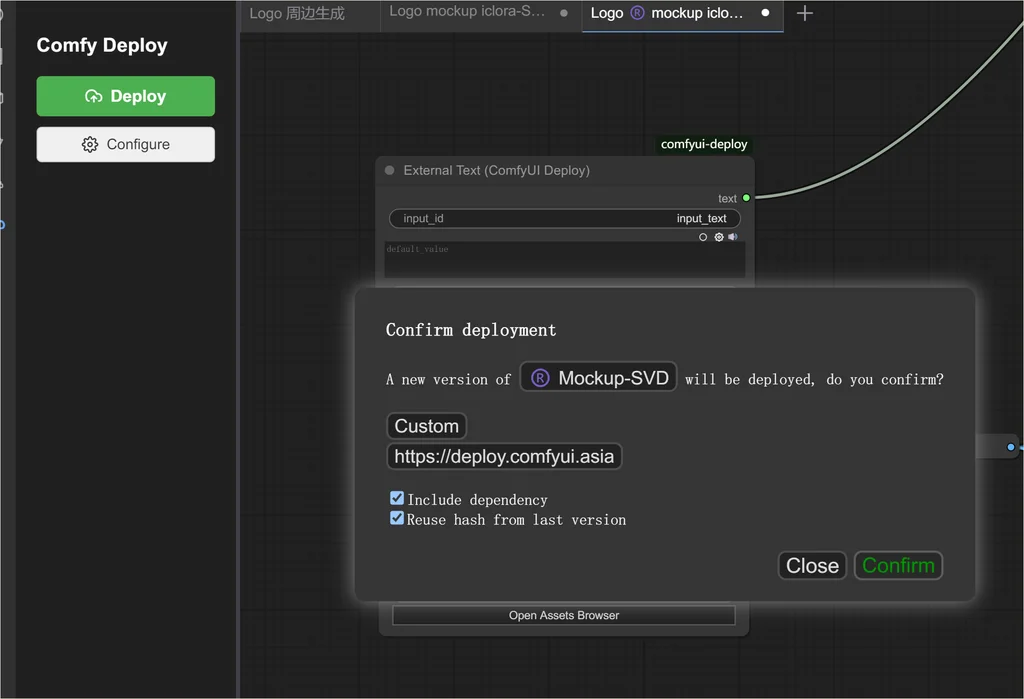
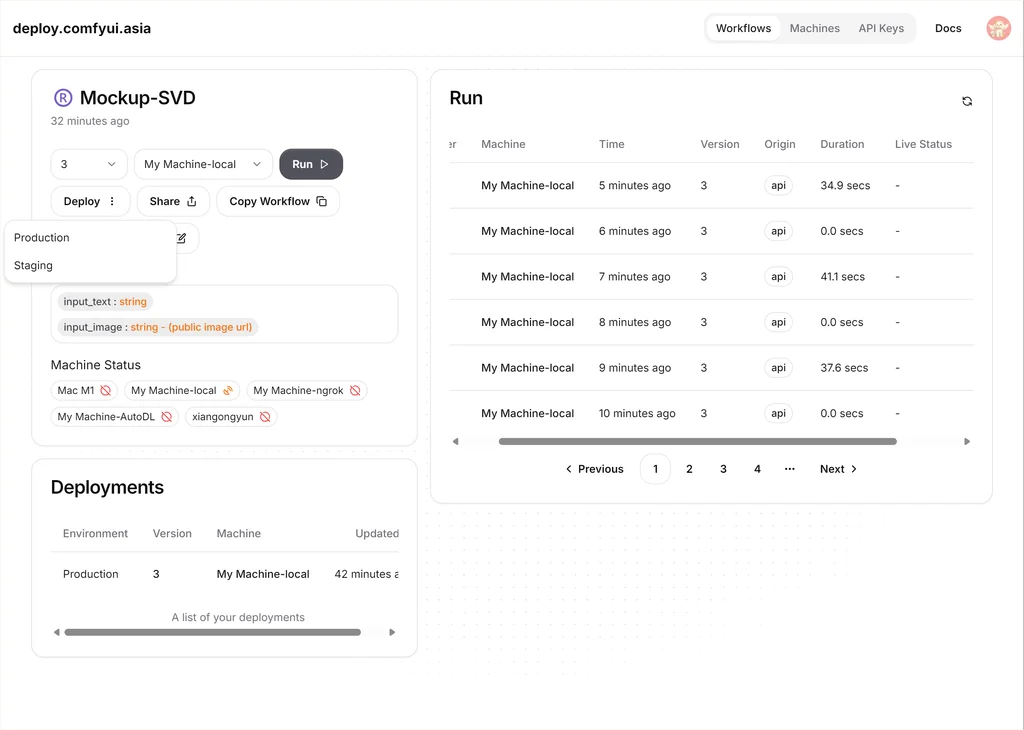
在 deploy 服务器上部署工作流。
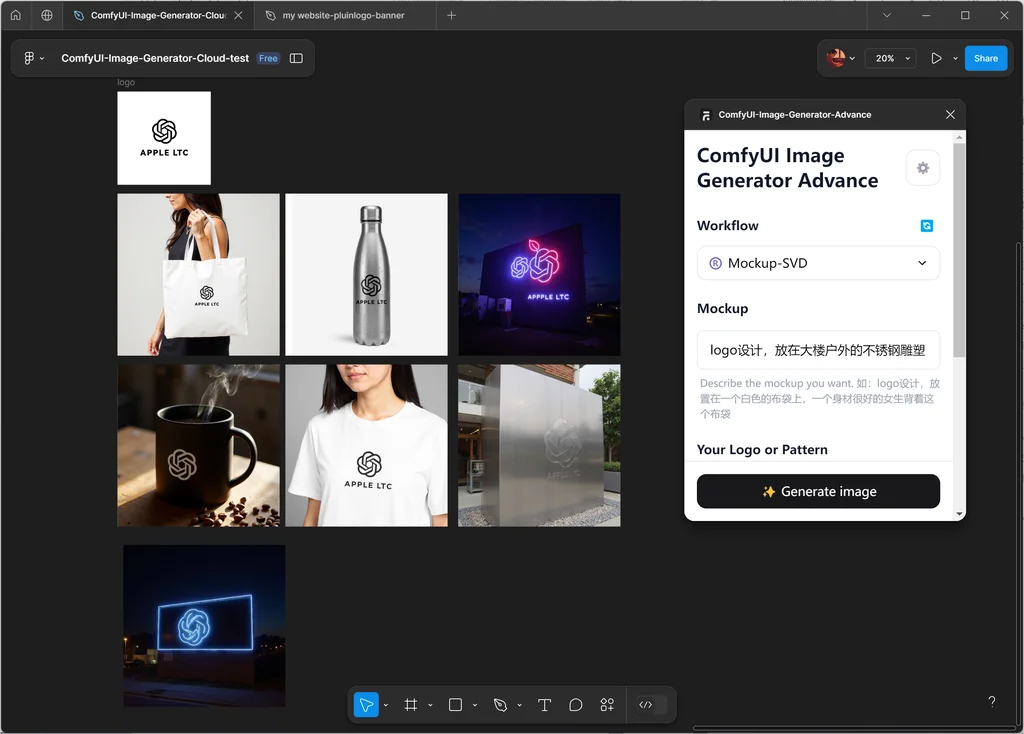
在 Figma 中使用。只需要输入提示词和输入图片即可等待 ComfyUI 返回图像了,非常简洁。
大家可以看看视频,感受一下:
接下来,教大家安装 SVD 加速技术,真的很猛!大家想办法装起来!
加速技术安装
针对 Windows 用户,需要保持网络通畅。
几个必备条件,官方 git 库已经说明了:
先安装 Wheels
pip install https://huggingface.co/mit-han-lab/nunchaku/resolve/main/nunchaku-0.1.4+torch2.6-cp312-cp312-win_amd64.whl
你也可以从魔搭先下载轮子到本地,然后执行安装命令。
魔搭链接地址:https://modelscope.cn/models/Lmxyy1999/nunchaku/files
安装nunchaku 节点
官方推荐用 Comfy-Cli 安装。
注意使用正确的 Python 环境安装,安装节点时需要在 ComfyUI 根目录执行。
pip install comfy-cli # Install ComfyUI CLI
comfy node registry-install nunchaku_nodes # Install Nunchaku 注意在ComfyUI目录下执行
当然,你使用 manager 或者直接 git 安装,也是可以的。
安装 deepcompressor
直接命令行安装,在任意目录就行,但是 python 环境要选对。
git clone https://github.com/mit-han-lab/deepcompressor
cd deepcompressor
poetry install
如果没有 poetry,那么需要 pip install 一下。
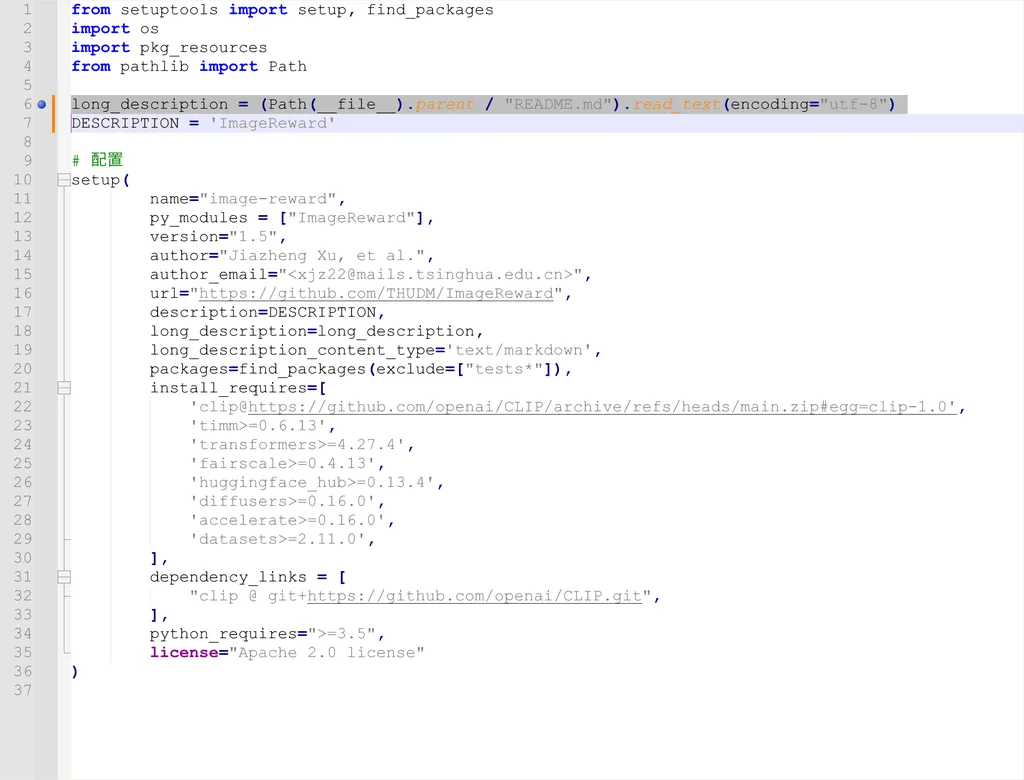
如果遇到下面的错误,是 setup 文件编码问题,解决方法如下:
找到环境的 ImageReward安装目录
例如我的是 conda 的安装环境,在:K:\program\minicaonda\envs\comfy\src\ImageReward 下面,
用记事本或者 vscode 打开 setup.py 文件,将以下行替换以下:
原:long_description = (Path(__file__).parent / "README.md").read_text()
替换为:long_description = (Path(__file__).parent / "README.md").read_text(encoding="utf-8")
最终如图:
安装 svdquant 节点
继续使用 cli:
comfy node registry-install svdquant
额外安装
不是所有人都会遇到,但是我遇到了缺失依赖的情况。
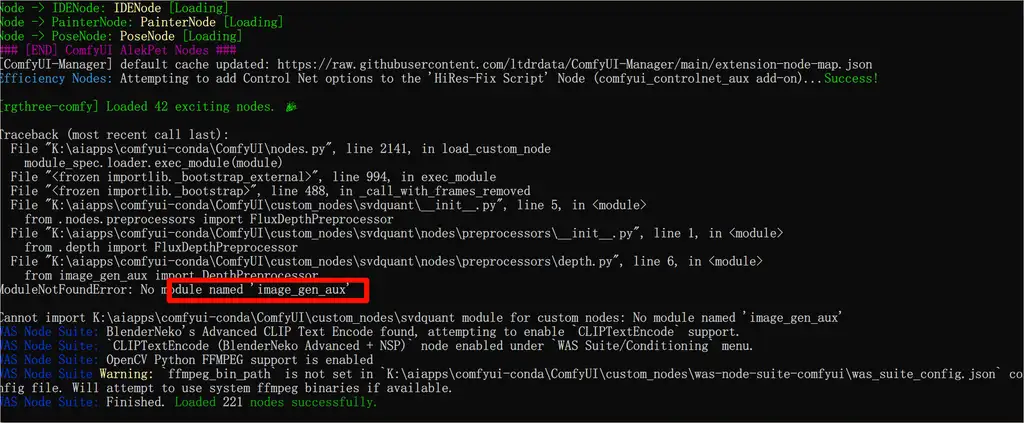
使用以下命令解决:
pip install git+https://github.com/asomoza/image_gen_aux.git
下载模型
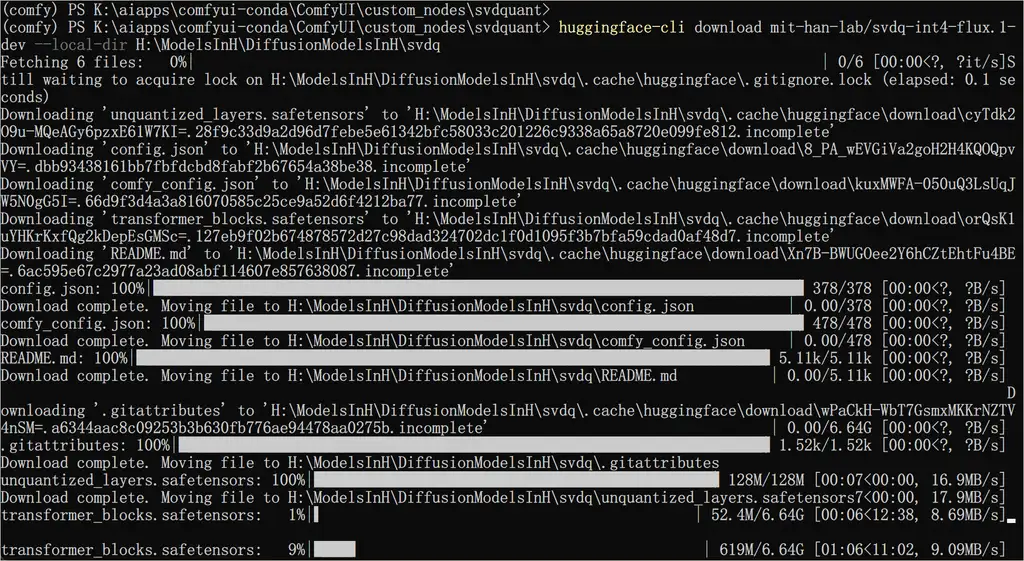
使用官方推荐的命令行下载,速度还不错,大家可以按照需求下载:
huggingface-cli download mit-han-lab/svdq-int4-flux.1-dev --local-dir models/diffusion_models/svdq-int4-flux.1-dev
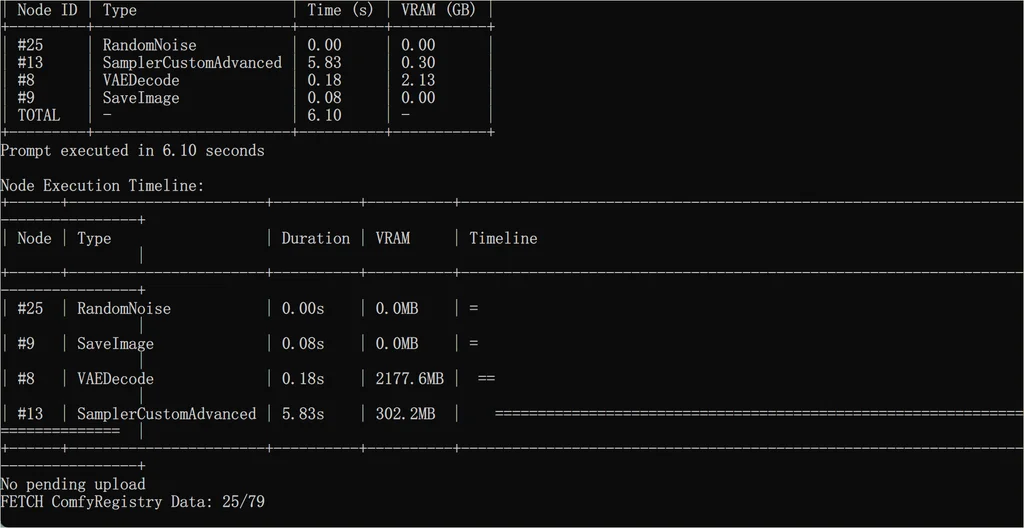
测试
默认图跑一下,只用了 6.1 s,速度简直飞快!这可是 FLUX dev 的模型,质量还不错!
转换 LoRA 模型支持 SVD
一般的 LoRA 应该还没有适配 SVD 的,需要手动转一下。这是来自 B 站 UP 主:
sirenmz的方法。
python -m nunchaku.lora.flux.convert \ --quant-path "你的量化模型路径" \ --lora-path "原始LoRA路径" \ --output-root "转换后保存文件夹" \ --lora-format comfyui
例如我的示例:
python -m nunchaku.lora.flux.convert --quant-path "J:/ComfyUI-aki-v1.1/models/diffusion_models/svdq-int4-flux.1-dev/transformer_blocks.safetensors" --lora-path "J:/ComfyUI-aki-v1.1/models/loras/flux/AWPortrait CN_1.0.safetensors" --output-root "H:/ModelsInH/LorasInH/svd" --lora-format comfyui
执行后,就会看到目标文件夹有这个转换后的 LoRA:
SVD LoRA 节点这样选择:
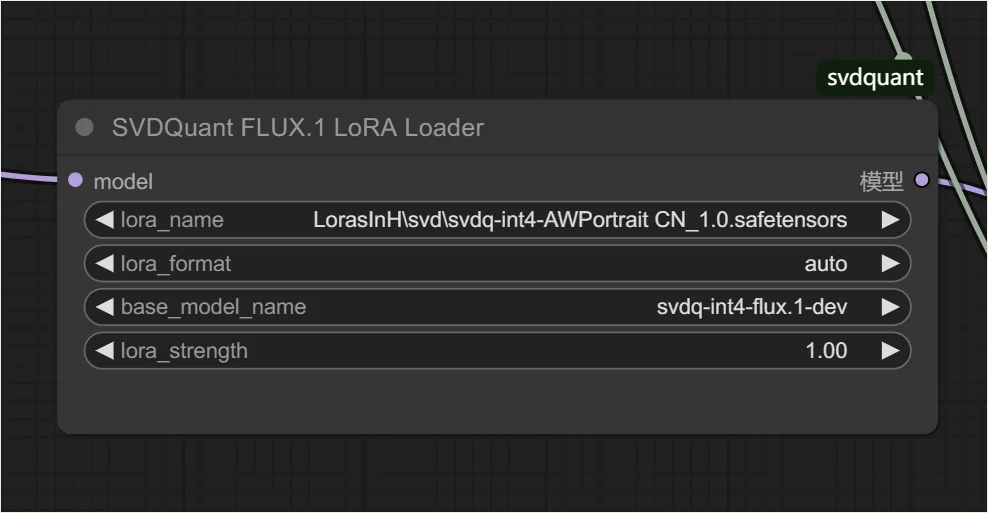
就可以愉快地使用 LoRA 进行出图了!
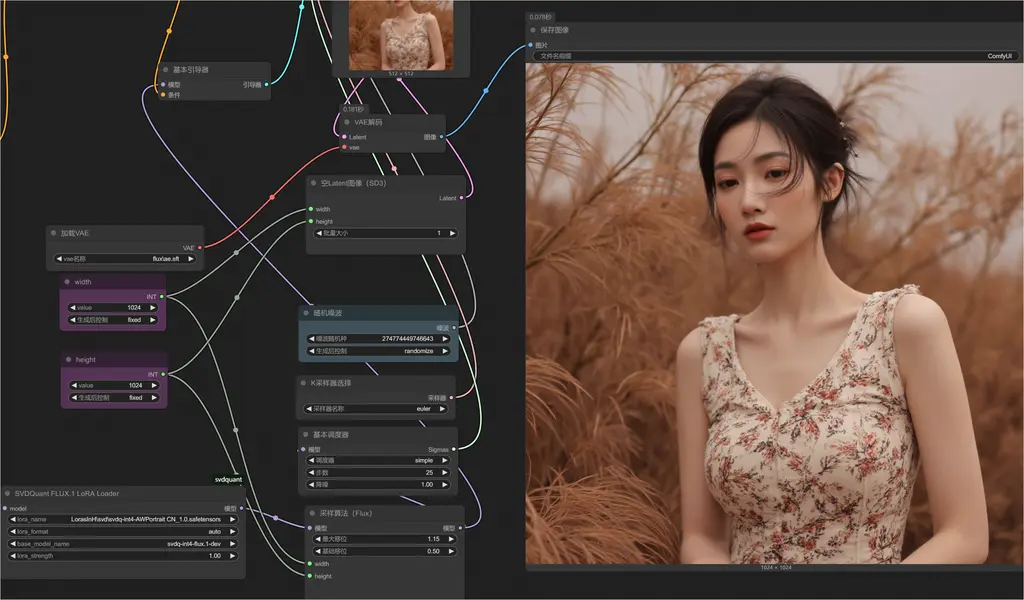
速度与质量的平衡的感觉真的爽!


还有现场占用,只用了 12 G 左右。

想获取更多 AI 辅助设计和设计灵感趋势? 欢迎关注我的公众号(设计小站):sjxz00。